 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Identification of Problematic Bias in Large Label Spaces
Jan 17, 2022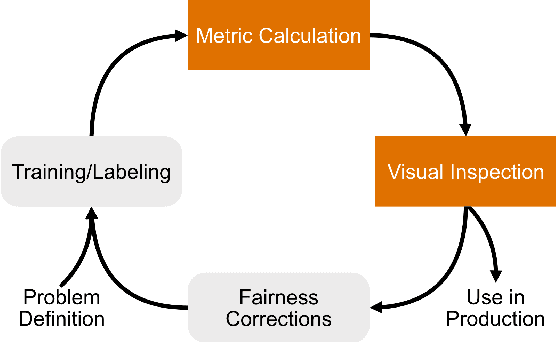

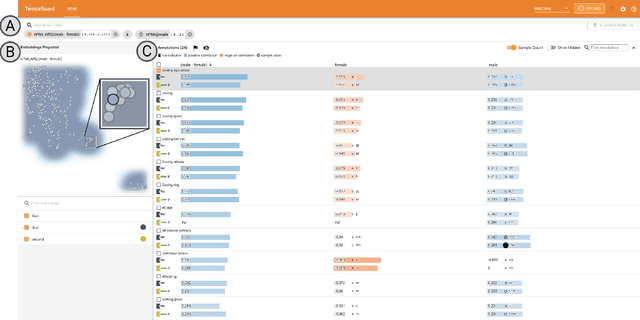
While the need for well-trained, fair ML systems is increasing ever more, measuring fairness for modern models and datasets is becoming increasingly difficult as they grow at an unprecedented pace. One key challenge in scaling common fairness metrics to such models and datasets is the requirement of exhaustive ground truth labeling, which cannot always be done. Indeed, this often rules out the application of traditional analysis metrics and systems. At the same time, ML-fairness assessments cannot be made algorithmically, as fairness is a highly subjective matter. Thus, domain experts need to be able to extract and reason about bias throughout models and datasets to make informed decisions. While visual analysis tools are of great help when investigating potential bias in DL models, none of the existing approaches have been designed for the specific tasks and challenges that arise in large label spaces. Addressing the lack of visualization work in this area, we propose guidelines for designing visualizations for such large label spaces, considering both technical and ethical issues. Our proposed visualization approach can be integrated into classical model and data pipelines, and we provide an implementation of our techniques open-sourced as a TensorBoard plug-in. With our approach, different models and datasets for large label spaces can be systematically and visually analyzed and compared to make informed fairness assessments tackling problematic bias.
Measuring Model Biases in the Absence of Ground Truth
Mar 05, 2021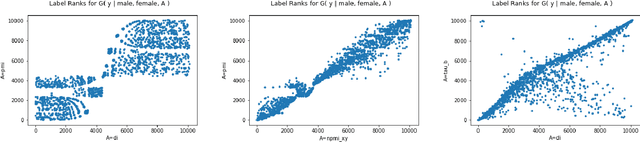
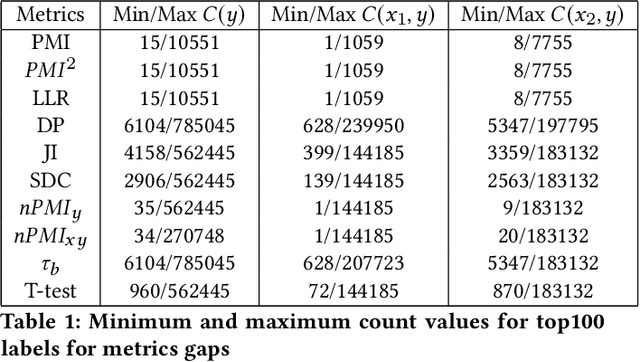

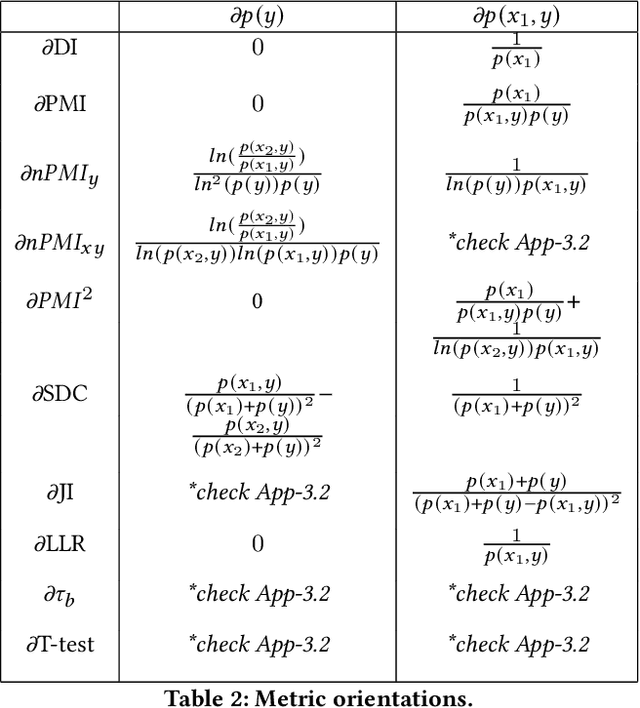
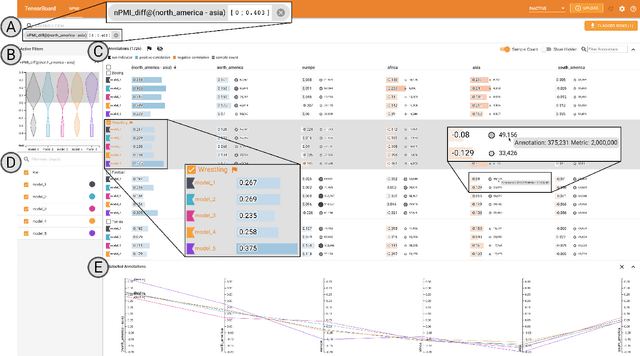
Recent advances in computer vision have led to the development of image classification models that can predict tens of thousands of object classes. Training these models can require millions of examples, leading to a demand of potentially billions of annotations. In practice, however, images are typically sparsely annotated, which can lead to problematic biases in the distribution of ground truth labels that are collected. This potential for annotation bias may then limit the utility of ground truth-dependent fairness metrics (e.g., Equalized Odds). To address this problem, in this work we introduce a new framing to the measurement of fairness and bias that does not rely on ground truth labels. Instead, we treat the model predictions for a given image as a set of labels, analogous to a 'bag of words' approach used in Natural Language Processing (NLP). This allows us to explore different association metrics between prediction sets in order to detect patterns of bias. We apply this approach to examine the relationship between identity labels, and all other labels in the dataset, using labels associated with 'male' and 'female') as a concrete example. We demonstrate how the statistical properties (especially normalization) of the different association metrics can lead to different sets of labels detected as having "gender bias". We conclude by demonstrating that pointwise mutual information normalized by joint probability (nPMI) is able to detect many labels with significant gender bias despite differences in the labels' marginal frequencies. Finally, we announce an open-sourced nPMI visualization tool using TensorBoard.