 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Semantic Transformer for 3D Scene Understanding
Dec 18, 2025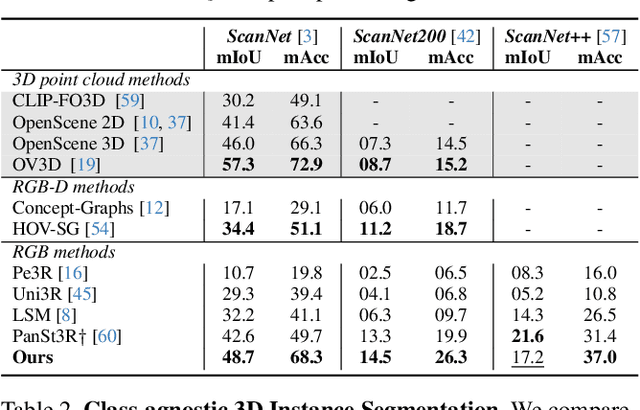
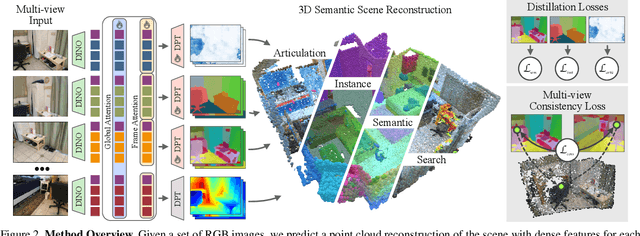
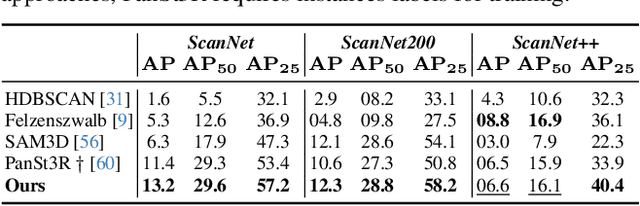
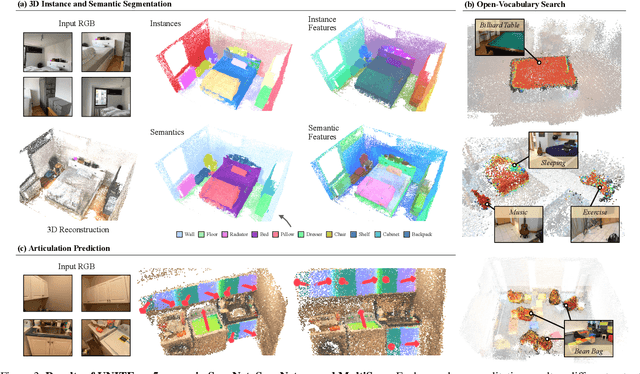
Holistic 3D scene understanding involves capturing and parsing unstructured 3D environments. Due to the inherent complexity of the real world, existing models have predominantly been developed and limited to be task-specific. We introduce UNITE, a Unified Semantic Transformer for 3D scene understanding, a novel feed-forward neural network that unifies a diverse set of 3D semantic tasks within a single model. Our model operates on unseen scenes in a fully end-to-end manner and only takes a few seconds to infer the full 3D semantic geometry. Our approach is capable of directly predicting multiple semantic attributes, including 3D scene segmentation, instance embeddings, open-vocabulary features, as well as affordance and articulations, solely from RGB images. The method is trained using a combination of 2D distillation, heavily relying on self-supervision and leverages novel multi-view losses designed to ensure 3D view consistency. We demonstrate that UNITE achieves state-of-the-art performance on several different semantic tasks and even outperforms task-specific models, in many cases, surpassing methods that operate on ground truth 3D geometry. See the project website at unite-page.github.io
S2D: Sparse-To-Dense Keymask Distillation for Unsupervised Video Instance Segmentation
Dec 16, 2025In recent years, the state-of-the-art in unsupervised video instance segmentation has heavily relied on synthetic video data, generated from object-centric image datasets such as ImageNet. However, video synthesis by artificially shifting and scaling image instance masks fails to accurately model realistic motion in videos, such as perspective changes, movement by parts of one or multiple instances, or camera motion. To tackle this issue, we propose an unsupervised video instance segmentation model trained exclusively on real video data. We start from unsupervised instance segmentation masks on individual video frames. However, these single-frame segmentations exhibit temporal noise and their quality varies through the video. Therefore, we establish temporal coherence by identifying high-quality keymasks in the video by leveraging deep motion priors. The sparse keymask pseudo-annotations are then used to train a segmentation model for implicit mask propagation, for which we propose a Sparse-To-Dense Distillation approach aided by a Temporal DropLoss. After training the final model on the resulting dense labelset, our approach outperforms the current state-of-the-art across various benchmarks.
OpenHype: Hyperbolic Embeddings for Hierarchical Open-Vocabulary Radiance Fields
Oct 24, 2025Modeling the inherent hierarchical structure of 3D objects and 3D scenes is highly desirable, as it enables a more holistic understanding of environments for autonomous agents. Accomplishing this with implicit representations, such as Neural Radiance Fields, remains an unexplored challenge. Existing methods that explicitly model hierarchical structures often face significant limitations: they either require multiple rendering passes to capture embeddings at different levels of granularity, significantly increasing inference time, or rely on predefined, closed-set discrete hierarchies that generalize poorly to the diverse and nuanced structures encountered by agents in the real world. To address these challenges, we propose OpenHype, a novel approach that represents scene hierarchies using a continuous hyperbolic latent space. By leveraging the properties of hyperbolic geometry, OpenHype naturally encodes multi-scale relationships and enables smooth traversal of hierarchies through geodesic paths in latent space. Our method outperforms state-of-the-art approaches on standard benchmarks, demonstrating superior efficiency and adaptability in 3D scene understanding.
Context-Aware Human Behavior Prediction Using Multimodal Large Language Models: Challenges and Insights
Apr 01, 2025Predicting human behavior in shared environments is crucial for safe and efficient human-robot interaction. Traditional data-driven methods to that end are pre-trained on domain-specific datasets, activity types, and prediction horizons. In contrast, the recent breakthroughs in Large Language Models (LLMs) promise open-ended cross-domain generalization to describe various human activities and make predictions in any context. In particular, Multimodal LLMs (MLLMs) are able to integrate information from various sources, achieving more contextual awareness and improved scene understanding. The difficulty in applying general-purpose MLLMs directly for prediction stems from their limited capacity for processing large input sequences, sensitivity to prompt design, and expensive fine-tuning. In this paper, we present a systematic analysis of applying pre-trained MLLMs for context-aware human behavior prediction. To this end, we introduce a modular multimodal human activity prediction framework that allows us to benchmark various MLLMs, input variations, In-Context Learning (ICL), and autoregressive techniques. Our evaluation indicates that the best-performing framework configuration is able to reach 92.8% semantic similarity and 66.1% exact label accuracy in predicting human behaviors in the target frame.
Active Learning Inspired ControlNet Guidance for Augmenting Semantic Segmentation Datasets
Mar 12, 2025



Recent advances in conditional image generation from diffusion models have shown great potential in achieving impressive image quality while preserving the constraints introduced by the user. In particular, ControlNet enables precise alignment between ground truth segmentation masks and the generated image content, allowing the enhancement of training datasets in segmentation tasks. This raises a key question: Can ControlNet additionally be guided to generate the most informative synthetic samples for a specific task? Inspired by active learning, where the most informative real-world samples are selected based on sample difficulty or model uncertainty, we propose the first approach to integrate active learning-based selection metrics into the backward diffusion process for sample generation. Specifically, we explore uncertainty, query by committee, and expected model change, which are commonly used in active learning, and demonstrate their application for guiding the sample generation process through gradient approximation. Our method is training-free, modifying only the backward diffusion process, allowing it to be used on any pretrained ControlNet. Using this process, we show that segmentation models trained with guided synthetic data outperform those trained on non-guided synthetic data. Our work underscores the need for advanced control mechanisms for diffusion-based models, which are not only aligned with image content but additionally downstream task performance, highlighting the true potential of synthetic data generation.
RelationField: Relate Anything in Radiance Fields
Dec 18, 2024



Neural radiance fields are an emerging 3D scene representation and recently even been extended to learn features for scene understanding by distilling open-vocabulary features from vision-language models. However, current method primarily focus on object-centric representations, supporting object segmentation or detection, while understanding semantic relationships between objects remains largely unexplored. To address this gap, we propose RelationField, the first method to extract inter-object relationships directly from neural radiance fields. RelationField represents relationships between objects as pairs of rays within a neural radiance field, effectively extending its formulation to include implicit relationship queries. To teach RelationField complex, open-vocabulary relationships, relationship knowledge is distilled from multi-modal LLMs. To evaluate RelationField, we solve open-vocabulary 3D scene graph generation tasks and relationship-guided instance segmentation, achieving state-of-the-art performance in both tasks. See the project website at https://relationfield.github.io.
CutS3D: Cutting Semantics in 3D for 2D Unsupervised Instance Segmentation
Nov 26, 2024Traditionally, algorithms that learn to segment object instances in 2D images have heavily relied on large amounts of human-annotated data. Only recently, novel approaches have emerged tackling this problem in an unsupervised fashion. Generally, these approaches first generate pseudo-masks and then train a class-agnostic detector. While such methods deliver the current state of the art, they often fail to correctly separate instances overlapping in 2D image space since only semantics are considered. To tackle this issue, we instead propose to cut the semantic masks in 3D to obtain the final 2D instances by utilizing a point cloud representation of the scene. Furthermore, we derive a Spatial Importance function, which we use to resharpen the semantics along the 3D borders of instances. Nevertheless, these pseudo-masks are still subject to mask ambiguity. To address this issue, we further propose to augment the training of a class-agnostic detector with three Spatial Confidence components aiming to isolate a clean learning signal. With these contributions, our approach outperforms competing methods across multiple standard benchmarks for unsupervised instance segmentation and object detection.
Less is More: Selective Reduction of CT Data for Self-Supervised Pre-Training of Deep Learning Models with Contrastive Learning Improves Downstream Classification Performance
Oct 18, 2024Self-supervised pre-training of deep learning models with contrastive learning is a widely used technique in image analysis. Current findings indicate a strong potential for contrastive pre-training on medical images. However, further research is necessary to incorporate the particular characteristics of these images. We hypothesize that the similarity of medical images hinders the success of contrastive learning in the medical imaging domain. To this end, we investigate different strategies based on deep embedding, information theory, and hashing in order to identify and reduce redundancy in medical pre-training datasets. The effect of these different reduction strategies on contrastive learning is evaluated on two pre-training datasets and several downstream classification tasks. In all of our experiments, dataset reduction leads to a considerable performance gain in downstream tasks, e.g., an AUC score improvement from 0.78 to 0.83 for the COVID CT Classification Grand Challenge, 0.97 to 0.98 for the OrganSMNIST Classification Challenge and 0.73 to 0.83 for a brain hemorrhage classification task. Furthermore, pre-training is up to nine times faster due to the dataset reduction. In conclusion, the proposed approach highlights the importance of dataset quality and provides a transferable approach to improve contrastive pre-training for classification downstream tasks on medical images.
* Published in Computers in Biology and Medicine
Evaluating Text-to-Image Synthesis: Survey and Taxonomy of Image Quality Metrics
Mar 29, 2024Recent advances in text-to-image synthesis enabled through a combination of language and vision foundation models have led to a proliferation of the tools available and an increased attention to the field. When conducting text-to-image synthesis, a central goal is to ensure that the content between text and image is aligned. As such, there exist numerous evaluation metrics that aim to mimic human judgement. However, it is often unclear which metric to use for evaluating text-to-image synthesis systems as their evaluation is highly nuanced. In this work, we provide a comprehensive overview of existing text-to-image evaluation metrics. Based on our findings, we propose a new taxonomy for categorizing these metrics. Our taxonomy is grounded in the assumption that there are two main quality criteria, namely compositionality and generality, which ideally map to human preferences. Ultimately, we derive guidelines for practitioners conducting text-to-image evaluation, discuss open challenges of evaluation mechanisms, and surface limitations of current metrics.
Attention-Guided Masked Autoencoders For Learning Image Representations
Feb 23, 2024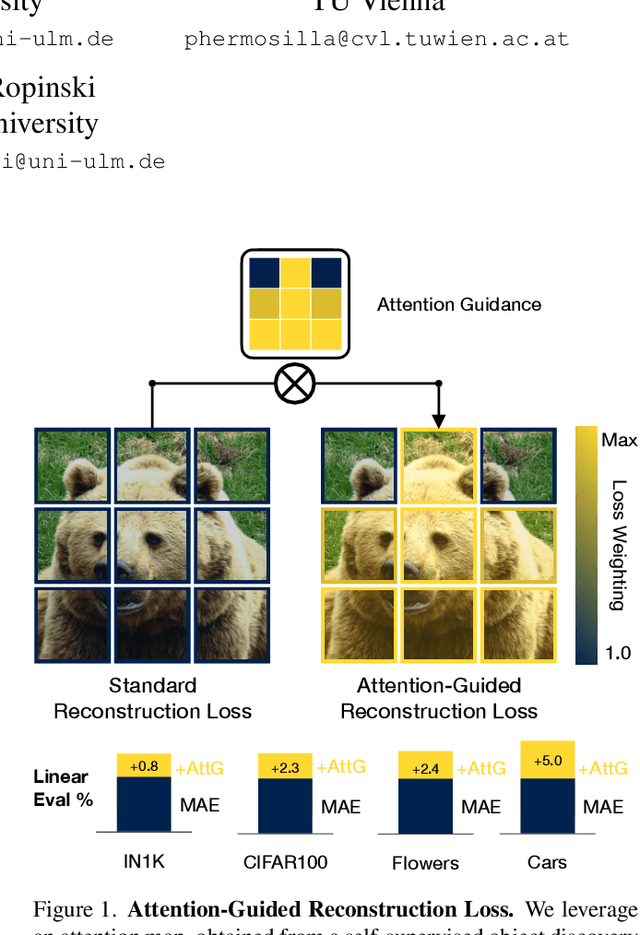
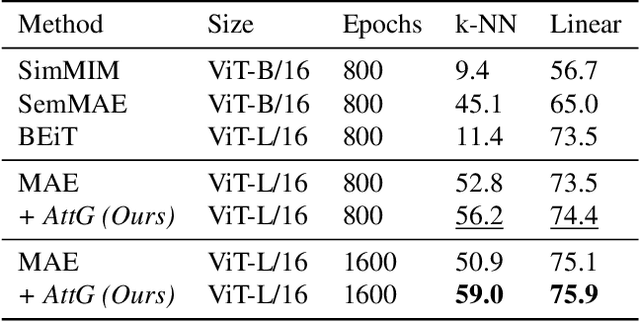
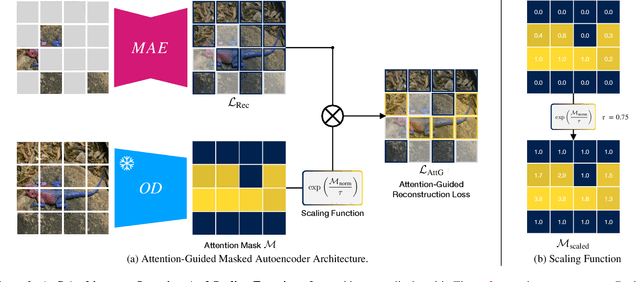
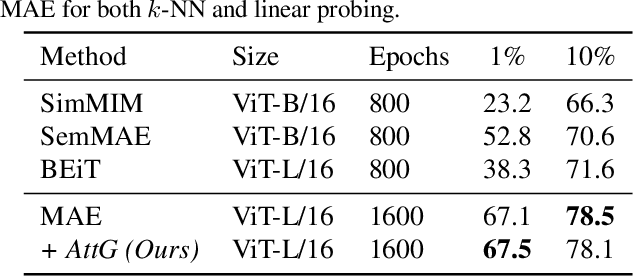
Masked autoencoders (MAEs) have established themselves as a powerful method for unsupervised pre-training for computer vision tasks. While vanilla MAEs put equal emphasis on reconstructing the individual parts of the image, we propose to inform the reconstruction process through an attention-guided loss function. By leveraging advances in unsupervised object discovery, we obtain an attention map of the scene which we employ in the loss function to put increased emphasis on reconstructing relevant objects, thus effectively incentivizing the model to learn more object-focused representations without compromising the established masking strategy. Our evaluations show that our pre-trained models learn better latent representations than the vanilla MAE, demonstrated by improved linear probing and k-NN classification results on several benchmarks while at the same time making ViTs more robust against varying backgrounds.