 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelationField: Relate Anything in Radiance Fields
Dec 18, 2024



Neural radiance fields are an emerging 3D scene representation and recently even been extended to learn features for scene understanding by distilling open-vocabulary features from vision-language models. However, current method primarily focus on object-centric representations, supporting object segmentation or detection, while understanding semantic relationships between objects remains largely unexplored. To address this gap, we propose RelationField, the first method to extract inter-object relationships directly from neural radiance fields. RelationField represents relationships between objects as pairs of rays within a neural radiance field, effectively extending its formulation to include implicit relationship queries. To teach RelationField complex, open-vocabulary relationships, relationship knowledge is distilled from multi-modal LLMs. To evaluate RelationField, we solve open-vocabulary 3D scene graph generation tasks and relationship-guided instance segmentation, achieving state-of-the-art performance in both tasks. See the project website at https://relationfield.github.io.
Open3DSG: Open-Vocabulary 3D Scene Graphs from Point Clouds with Queryable Objects and Open-Set Relationships
Feb 19, 2024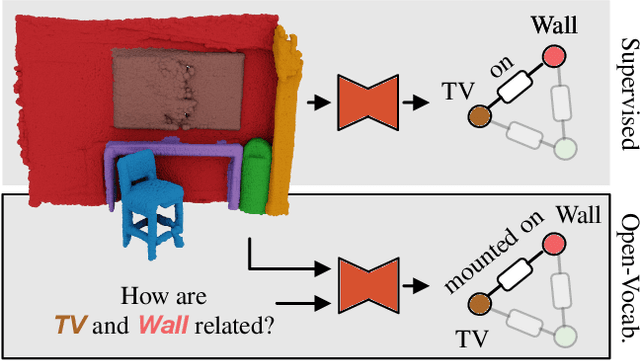



Current approaches for 3D scene graph prediction rely on labeled datasets to train models for a fixed set of known object classes and relationship categories. We present Open3DSG, an alternative approach to learn 3D scene graph prediction in an open world without requiring labeled scene graph data. We co-embed the features from a 3D scene graph prediction backbone with the feature space of powerful open world 2D vision language foundation models. This enables us to predict 3D scene graphs from 3D point clouds in a zero-shot manner by querying object classes from an open vocabulary and predicting the inter-object relationships from a grounded LLM with scene graph features and queried object classes as context. Open3DSG is the first 3D point cloud method to predict not only explicit open-vocabulary object classes, but also open-set relationships that are not limited to a predefined label set, making it possible to express rare as well as specific objects and relationships in the predicted 3D scene graph. Our experiments show that Open3DSG is effective at predicting arbitrary object classes as well as their complex inter-object relationships describing spatial, supportive, semantic and comparative relationships.
Lang3DSG: Language-based contrastive pre-training for 3D Scene Graph prediction
Oct 25, 2023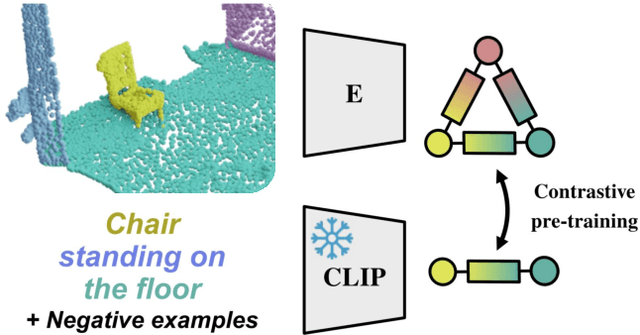


D scene graphs are an emerging 3D scene representation, that models both the objects present in the scene as well as their relationships. However, learning 3D scene graphs is a challenging task because it requires not only object labels but also relationship annotations, which are very scarce in datasets. While it is widely accepted that pre-training is an effective approach to improve model performance in low data regimes, in this paper, we find that existing pre-training methods are ill-suited for 3D scene graphs. To solve this issue, we present the first language-based pre-training approach for 3D scene graphs, whereby we exploit the strong relationship between scene graphs and language. To this end, we leverage the language encoder of CLIP, a popular vision-language model, to distill its knowledge into our graph-based network. We formulate a contrastive pre-training, which aligns text embeddings of relationships (subject-predicate-object triplets) and predicted 3D graph features. Our method achieves state-of-the-art results on the main semantic 3D scene graph benchmark by showing improved effectiveness over pre-training baselines and outperforming all the existing fully supervised scene graph prediction methods by a significant margin. Furthermore, since our scene graph features are language-aligned, it allows us to query the language space of the features in a zero-shot manner. In this paper, we show an example of utilizing this property of the features to predict the room type of a scene without further training.
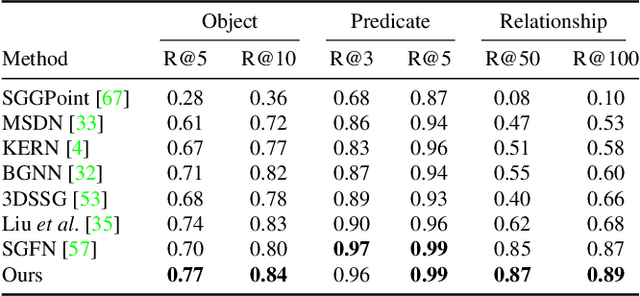
SGRec3D: Self-Supervised 3D Scene Graph Learning via Object-Level Scene Reconstruction
Sep 27, 2023



In the field of 3D scene understanding, 3D scene graphs have emerged as a new scene representation that combines geometric and semantic information about objects and their relationships. However, learning semantic 3D scene graphs in a fully supervised manner is inherently difficult as it requires not only object-level annotations but also relationship labels. While pre-training approaches have helped to boost the performance of many methods in various fields, pre-training for 3D scene graph prediction has received little attention. Furthermore, we find in this paper that classical contrastive point cloud-based pre-training approaches are ineffective for 3D scene graph learning. To this end, we present SGRec3D, a novel self-supervised pre-training method for 3D scene graph prediction. We propose to reconstruct the 3D input scene from a graph bottleneck as a pretext task. Pre-training SGRec3D does not require object relationship labels, making it possible to exploit large-scale 3D scene understanding datasets, which were off-limits for 3D scene graph learning before. Our experiments demonstrate that in contrast to recent point cloud-based pre-training approaches, our proposed pre-training improves the 3D scene graph prediction considerably, which results in SOTA performance, outperforming other 3D scene graph models by +10% on object prediction and +4% on relationship prediction. Additionally, we show that only using a small subset of 10% labeled data during fine-tuning is sufficient to outperform the same model without pre-training.
Plug-and-Play SLAM: A Unified SLAM Architecture for Modularity and Ease of Use
Mar 02, 2020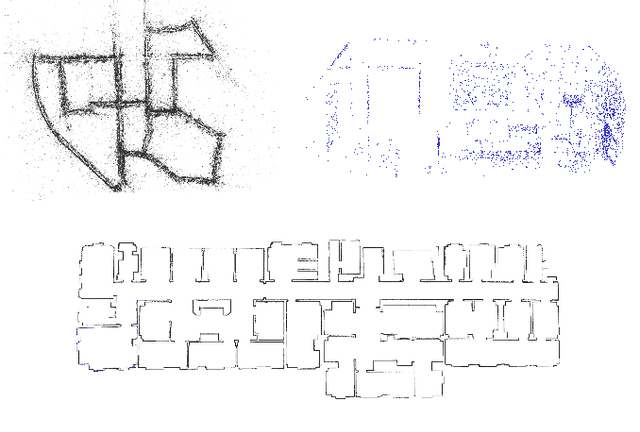
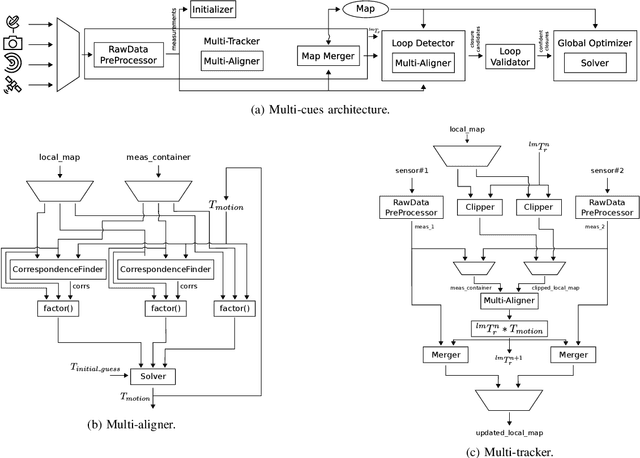
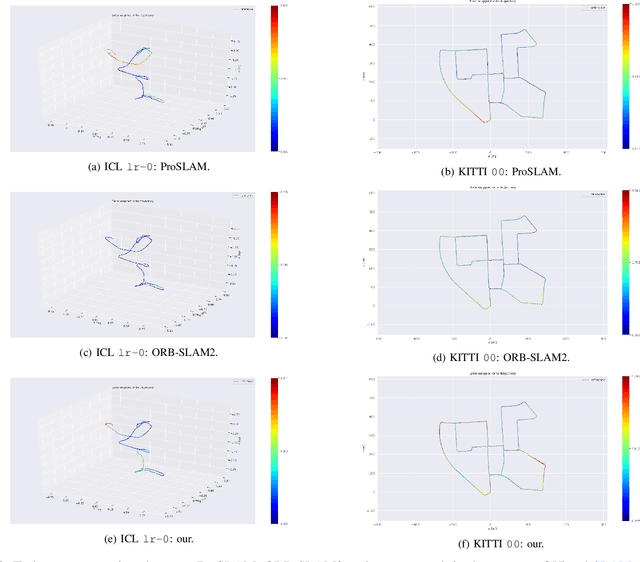
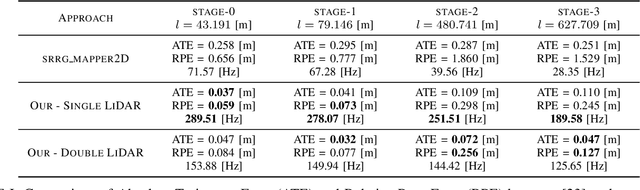
Nowadays, SLAM (Simultaneous Localization and Mapping) is considered by the Robotics community to be a mature field. Currently, there are many open-source systems that are able to deliver fast and accurate estimation in typical real-world scenarios. Still, all these systems often provide an ad-hoc implementation that entailed to predefined sensor configurations. In this work, we tackle this issue, proposing a novel SLAM architecture specifically designed to address heterogeneous sensors' configuration and to standardize SLAM solutions. Thanks to its modularity and to specific design patterns, the presented architecture is easy to extend, enhancing code reuse and efficiency. Finally, adopting our solution, we conducted comparative experiments for a variety of sensor configurations, showing competitive results that confirm state-of-the-art performance.
Least Squares Optimization: from Theory to Practice
Feb 26, 2020
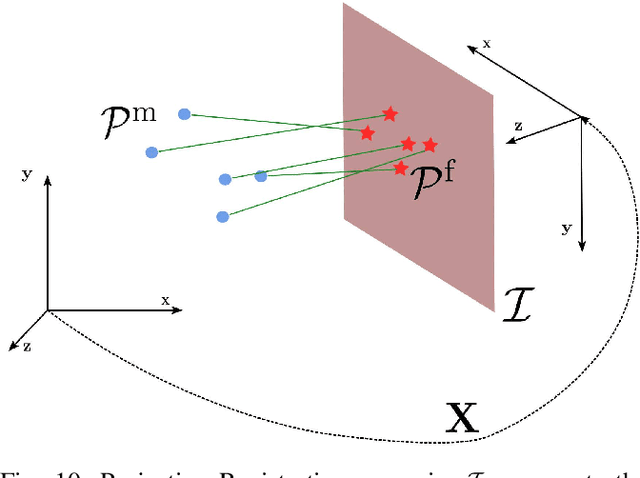
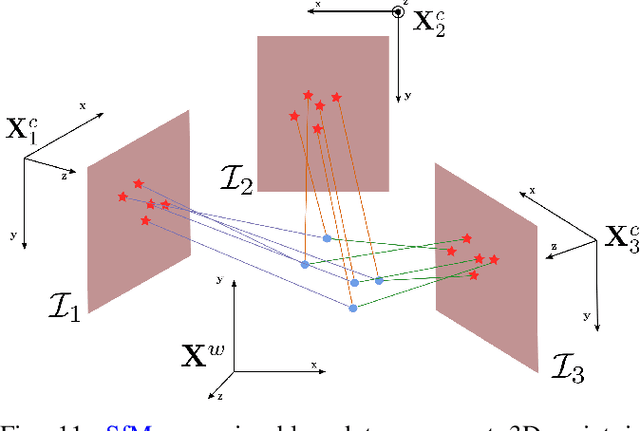
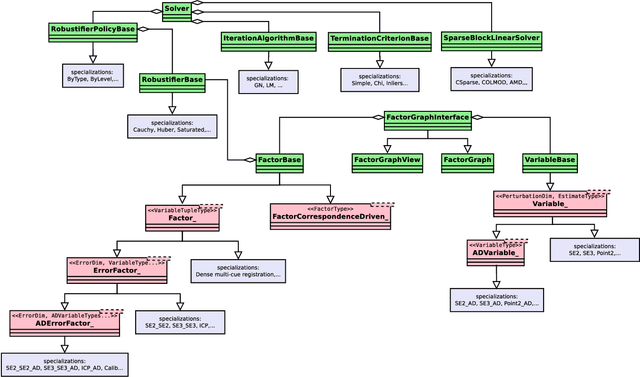
Nowadays, Non-Linear Least-Squares embodies the foundation of many Robotics and Computer Vision systems. The research community deeply investigated this topic in the last years, and this resulted in the development of several open-source solvers to approach constantly increasing classes of problems. In this work, we propose a unified methodology to design and develop efficient Least-Squares Optimization algorithms, focusing on the structures and patterns of each specific domain. Furthermore, we present a novel open-source optimization system, that addresses transparently problems with a different structure and designed to be easy to extend. The system is written in modern C++ and can run efficiently on embedded systems. Source code: https://srrg.gitlab.io/srrg2-solver.html. We validated our approach by conducting comparative experiments on several problems using standard datasets. The results show that our system achieves state-of-the-art performances in all tested scenarios.
ProSLAM: Graph SLAM from a Programmer's Perspective
Sep 13, 2017

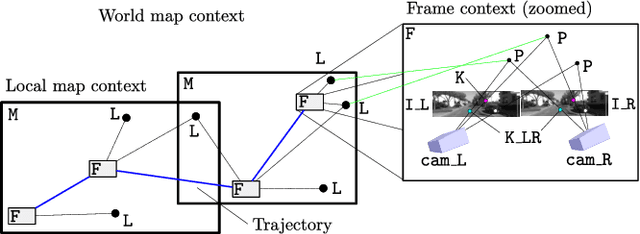
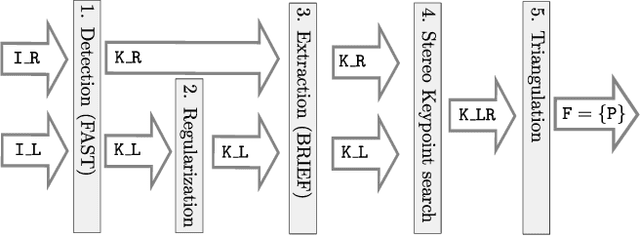
In this paper we present ProSLAM, a lightweight stereo visual SLAM system designed with simplicity in mind. Our work stems from the experience gathered by the authors while teaching SLAM to students and aims at providing a highly modular system that can be easily implemented and understood. Rather than focusing on the well known mathematical aspects of Stereo Visual SLAM, in this work we highlight the data structures and the algorithmic aspects that one needs to tackle during the design of such a system. We implemented ProSLAM using the C++ programming language in combination with a minimal set of well known used external libraries. In addition to an open source implementation, we provide several code snippets that address the core aspects of our approach directly in this paper. The results of a thorough validation performed on standard benchmark datasets show that our approach achieves accuracy comparable to state of the art methods, while requiring substantially less computational resources.
Bridging between Computer and Robot Vision through Data Augmentation: a Case Study on Object Recognition
May 05, 2017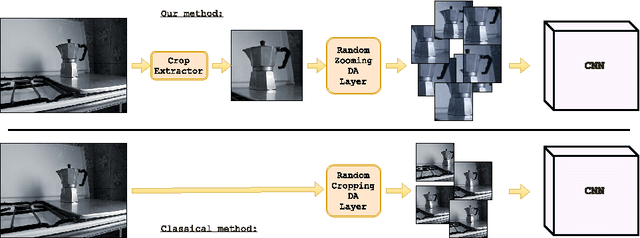
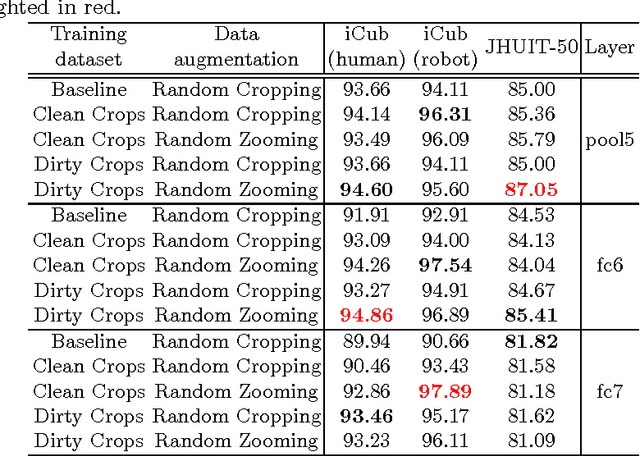

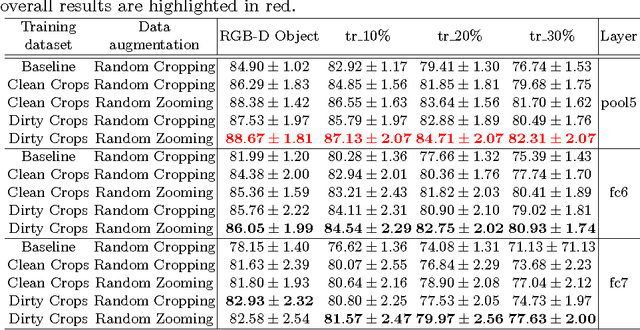
Despite the impressive progress brought by deep network in visual object recognition, robot vision is still far from being a solved problem. The most successful convolutional architectures are developed starting from ImageNet, a large scale collection of images of object categories downloaded from the Web. This kind of images is very different from the situated and embodied visual experience of robots deployed in unconstrained settings. To reduce the gap between these two visual experiences, this paper proposes a simple yet effective data augmentation layer that zooms on the object of interest and simulates the object detection outcome of a robot vision system. The layer, that can be used with any convolutional deep architecture, brings to an increase in object recognition performance of up to 7\%, in experiments performed over three different benchmark databases. Upon acceptance of the paper, our robot data augmentation layer will be made publicly available.