 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAHA: Supervised Autonomous HArvester for selective forest thinning
Jan 03, 2026Forestry plays a vital role in our society, creating significant ecological, economic, and recreational value. Efficient forest management involves labor-intensive and complex operations. One essential task for maintaining forest health and productivity is selective thinning, which requires skilled operators to remove specific trees to create optimal growing conditions for the remaining ones. In this work, we present a solution based on a small-scale robotic harvester (SAHA) designed for executing this task with supervised autonomy. We build on a 4.5-ton harvester platform and implement key hardware modifications for perception and automatic control. We implement learning- and model-based approaches for precise control of hydraulic actuators, accurate navigation through cluttered environments, robust state estimation, and reliable semantic estimation of terrain traversability. Integrating state-of-the-art techniques in perception, planning, and control, our robotic harvester can autonomously navigate forest environments and reach targeted trees for selective thinning. We present experimental results from extensive field trials over kilometer-long autonomous missions in northern European forests, demonstrating the harvester's ability to operate in real forests. We analyze the performance and provide the lessons learned for advancing robotic forest management.
KISS-SLAM: A Simple, Robust, and Accurate 3D LiDAR SLAM System With Enhanced Generalization Capabilities
Mar 16, 2025



Robust and accurate localization and mapping of an environment using laser scanners, so-called LiDAR SLAM, is essential to many robotic applications. Early 3D LiDAR SLAM methods often exploited additional information from IMU or GNSS sensors to enhance localization accuracy and mitigate drift. Later, advanced systems further improved the estimation at the cost of a higher runtime and complexity. This paper explores the limits of what can be achieved with a LiDAR-only SLAM approach while following the "Keep It Small and Simple" (KISS) principle. By leveraging this minimalistic design principle, our system, KISS-SLAM, archives state-of-the-art performances in pose accuracy while requiring little to no parameter tuning for deployment across diverse environments, sensors, and motion profiles. We follow best practices in graph-based SLAM and build upon LiDAR odometry to compute the relative motion between scans and construct local maps of the environment. To correct drift, we match local maps and optimize the trajectory in a pose graph optimization step. The experimental results demonstrate that this design achieves competitive performance while reducing complexity and reliance on additional sensor modalities. By prioritizing simplicity, this work provides a new strong baseline for LiDAR-only SLAM and a high-performing starting point for future research. Further, our pipeline builds consistent maps that can be used directly for further downstream tasks like navigation. Our open-source system operates faster than the sensor frame rate in all presented datasets and is designed for real-world scenarios.
Efficiently Closing Loops in LiDAR-Based SLAM Using Point Cloud Density Maps
Jan 13, 2025



Consistent maps are key for most autonomous mobile robots. They often use SLAM approaches to build such maps. Loop closures via place recognition help maintain accurate pose estimates by mitigating global drift. This paper presents a robust loop closure detection pipeline for outdoor SLAM with LiDAR-equipped robots. The method handles various LiDAR sensors with different scanning patterns, field of views and resolutions. It generates local maps from LiDAR scans and aligns them using a ground alignment module to handle both planar and non-planar motion of the LiDAR, ensuring applicability across platforms. The method uses density-preserving bird's eye view projections of these local maps and extracts ORB feature descriptors from them for place recognition. It stores the feature descriptors in a binary search tree for efficient retrieval, and self-similarity pruning addresses perceptual aliasing in repetitive environments. Extensive experiments on public and self-recorded datasets demonstrate accurate loop closure detection, long-term localization, and cross-platform multi-map alignment, agnostic to the LiDAR scanning patterns, fields of view, and motion profiles.
Efficient LiDAR Bundle Adjustment for Multi-Scan Alignment Utilizing Continuous-Time Trajectories
Dec 16, 2024Constructing precise global maps is a key task in robotics and is required for localization, surveying, monitoring, or constructing digital twins. To build accurate maps, data from mobile 3D LiDAR sensors is often used. Mapping requires correctly aligning the individual point clouds to each other to obtain a globally consistent map. In this paper, we investigate the problem of multi-scan alignment to obtain globally consistent point cloud maps. We propose a 3D LiDAR bundle adjustment approach to solve the global alignment problem and jointly optimize the available data. Utilizing a continuous-time trajectory allows us to consider the ego-motion of the LiDAR scanner while recording a single scan directly in the least squares adjustment. Furthermore, pruning the search space of correspondences and utilizing out-of-core circular buffer enables our approach to align thousands of point clouds efficiently. We successfully align point clouds recorded with a handheld LiDAR, as well as ones mounted on a vehicle, and are able to perform multi-session alignment.
Kinematic-ICP: Enhancing LiDAR Odometry with Kinematic Constraints for Wheeled Mobile Robots Moving on Planar Surfaces
Oct 14, 2024



LiDAR odometry is essential for many robotics applications, including 3D mapping, navigation, and simultaneous localization and mapping. LiDAR odometry systems are usually based on some form of point cloud registration to compute the ego-motion of a mobile robot. Yet, few of today's LiDAR odometry systems consider the domain-specific knowledge and the kinematic model of the mobile platform during the point cloud alignment. In this paper, we present Kinematic-ICP, a LiDAR odometry system that focuses on wheeled mobile robots equipped with a 3D LiDAR and moving on a planar surface, which is a common assumption for warehouses, offices, hospitals, etc. Our approach introduces kinematic constraints within the optimization of a traditional point-to-point iterative closest point scheme. In this way, the resulting motion follows the kinematic constraints of the platform, effectively exploiting the robot's wheel odometry and the 3D LiDAR observations. We dynamically adjust the influence of LiDAR measurements and wheel odometry in our optimization scheme, allowing the system to handle degenerate scenarios such as feature-poor corridors. We evaluate our approach on robots operating in large-scale warehouse environments, but also outdoors. The experiments show that our approach achieves top performances and is more accurate than wheel odometry and common LiDAR odometry systems. Kinematic-ICP has been recently deployed in the Dexory fleet of robots operating in warehouses worldwide at their customers' sites, showing that our method can run in the real world alongside a complete navigation stack.
Unsupervised Pre-Training for 3D Leaf Instance Segmentation
Jan 16, 2024Crops for food, feed, fiber, and fuel are key natural resources for our society. Monitoring plants and measuring their traits is an important task in agriculture often referred to as plant phenotyping. Traditionally, this task is done manually, which is time- and labor-intensive. Robots can automate phenotyping providing reproducible and high-frequency measurements. Today's perception systems use deep learning to interpret these measurements, but require a substantial amount of annotated data to work well. Obtaining such labels is challenging as it often requires background knowledge on the side of the labelers. This paper addresses the problem of reducing the labeling effort required to perform leaf instance segmentation on 3D point clouds, which is a first step toward phenotyping in 3D. Separating all leaves allows us to count them and compute relevant traits as their areas, lengths, and widths. We propose a novel self-supervised task-specific pre-training approach to initialize the backbone of a network for leaf instance segmentation. We also introduce a novel automatic postprocessing that considers the difficulty of correctly segmenting the points close to the stem, where all the leaves petiole overlap. The experiments presented in this paper suggest that our approach boosts the performance over all the investigated scenarios. We also evaluate the embeddings to assess the quality of the fully unsupervised approach and see a higher performance of our domain-specific postprocessing.
* 8 pages, 7 images, RA-L
LIO-EKF: High Frequency LiDAR-Inertial Odometry using Extended Kalman Filters
Nov 16, 2023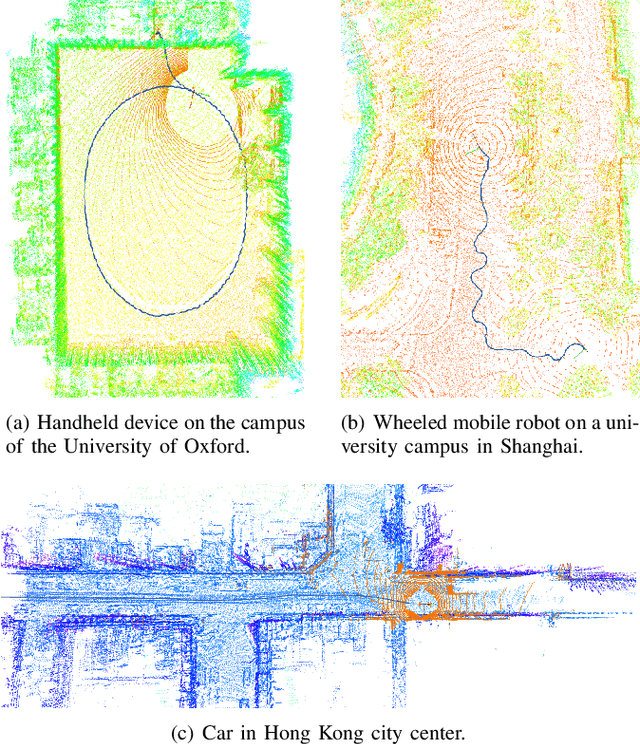
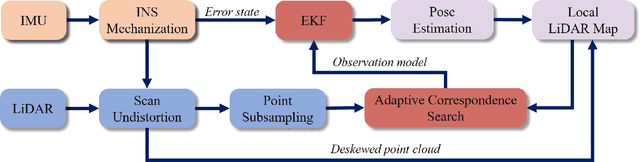
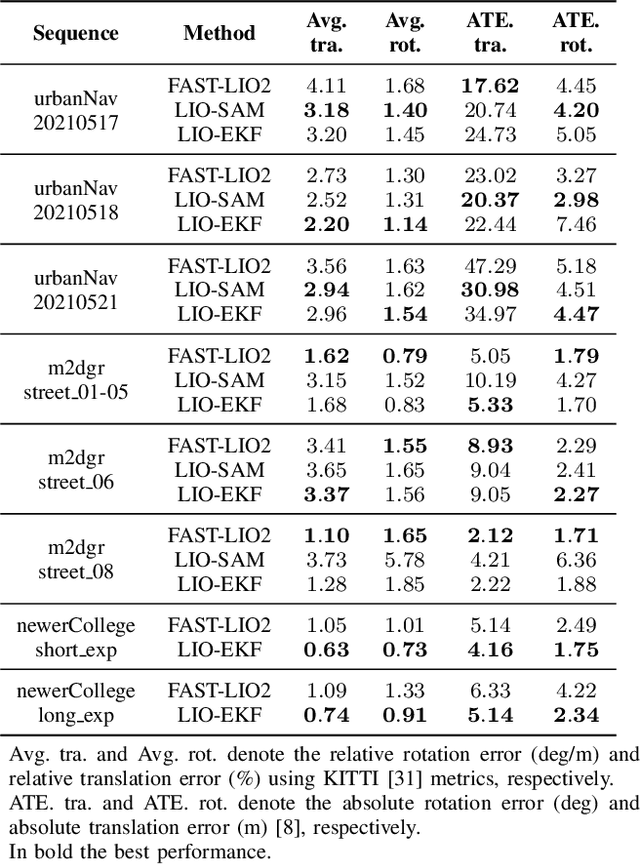

Odometry estimation is a key element for every autonomous system requiring navigation in an unknown environment. In modern mobile robots, 3D LiDAR-inertial systems are often used for this task. By fusing LiDAR scans and IMU measurements, these systems can reduce the accumulated drift caused by sequentially registering individual LiDAR scans and provide a robust pose estimate. Although effective, LiDAR-inertial odometry systems require proper parameter tuning to be deployed. In this paper, we propose LIO-EKF, a tightly-coupled LiDAR-inertial odometry system based on point-to-point registration and the classical extended Kalman filter scheme. We propose an adaptive data association that considers the relative pose uncertainty, the map discretization errors, and the LiDAR noise. In this way, we can substantially reduce the parameters to tune for a given type of environment. The experimental evaluation suggests that the proposed system performs on par with the state-of-the-art LiDAR-inertial odometry pipelines, but is significantly faster in computing the odometry.
Building Volumetric Beliefs for Dynamic Environments Exploiting Map-Based Moving Object Segmentation
Jul 17, 2023



Mobile robots that navigate in unknown environments need to be constantly aware of the dynamic objects in their surroundings for mapping, localization, and planning. It is key to reason about moving objects in the current observation and at the same time to also update the internal model of the static world to ensure safety. In this paper, we address the problem of jointly estimating moving objects in the current 3D LiDAR scan and a local map of the environment. We use sparse 4D convolutions to extract spatio-temporal features from scan and local map and segment all 3D points into moving and non-moving ones. Additionally, we propose to fuse these predictions in a probabilistic representation of the dynamic environment using a Bayes filter. This volumetric belief models, which parts of the environment can be occupied by moving objects. Our experiments show that our approach outperforms existing moving object segmentation baselines and even generalizes to different types of LiDAR sensors. We demonstrate that our volumetric belief fusion can increase the precision and recall of moving object segmentation and even retrieve previously missed moving objects in an online mapping scenario.
On Domain-Specific Pre-Training for Effective Semantic Perception in Agricultural Robotics
Mar 22, 2023



Agricultural robots have the prospect to enable more efficient and sustainable agricultural production of food, feed, and fiber. Perception of crops and weeds is a central component of agricultural robots that aim to monitor fields and assess the plants as well as their growth stage in an automatic manner. Semantic perception mostly relies on deep learning using supervised approaches, which require time and qualified workers to label fairly large amounts of data. In this paper, we look into the problem of reducing the amount of labels without compromising the final segmentation performance. For robots operating in the field, pre-training networks in a supervised way is already a popular method to reduce the number of required labeled images. We investigate the possibility of pre-training in a self-supervised fashion using data from the target domain. To better exploit this data, we propose a set of domain-specific augmentation strategies. We evaluate our pre-training on semantic segmentation and leaf instance segmentation, two important tasks in our domain. The experimental results suggest that pre-training with domain-specific data paired with our data augmentation strategy leads to superior performance compared to commonly used pre-trainings. Furthermore, the pre-trained networks obtain similar performance to the fully supervised with less labeled data.
Hierarchical Approach for Joint Semantic, Plant Instance, and Leaf Instance Segmentation in the Agricultural Domain
Oct 14, 2022
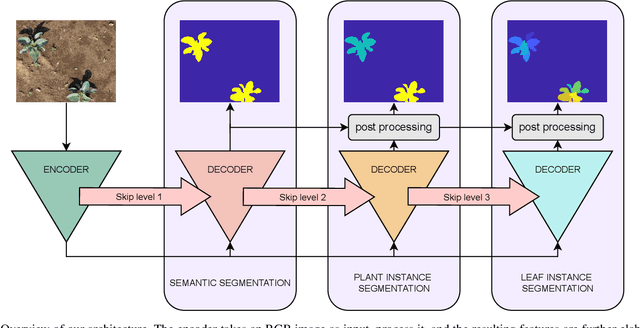


Plant phenotyping is a central task in agriculture, as it describes plants' growth stage, development, and other relevant quantities. Robots can help automate this process by accurately estimating plant traits such as the number of leaves, leaf area, and the plant size. In this paper, we address the problem of joint semantic, plant instance, and leaf instance segmentation of crop fields from RGB data. We propose a single convolutional neural network that addresses the three tasks simultaneously, exploiting their underlying hierarchical structure. We introduce task-specific skip connections, which our experimental evaluation proves to be more beneficial than the usual schemes. We also propose a novel automatic post-processing, which explicitly addresses the problem of spatially close instances, common in the agricultural domain because of overlapping leaves. Our architecture simultaneously tackles these problems jointly in the agricultural context. Previous works either focus on plant or leaf segmentation, or do not optimise for semantic segmentation. Results show that our system has superior performance to state-of-the-art approaches, while having a reduced number of parameters and is operating at camera frame rate.