 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Hierarchical Panoptic Segmentation in Real Orchard Environments Across Different Sensors
Mar 17, 2025Crop yield estimation is a relevant problem in agriculture, because an accurate crop yield estimate can support farmers' decisions on harvesting or precision intervention. Robots can help to automate this process. To do so, they need to be able to perceive the surrounding environment to identify target objects. In this paper, we introduce a novel approach to address the problem of hierarchical panoptic segmentation of apple orchards on 3D data from different sensors. Our approach is able to simultaneously provide semantic segmentation, instance segmentation of trunks and fruits, and instance segmentation of plants (a single trunk with its fruits). This allows us to identify relevant information such as individual plants, fruits, and trunks, and capture the relationship among them, such as precisely estimate the number of fruits associated to each tree in an orchard. Additionally, to efficiently evaluate our approach for hierarchical panoptic segmentation, we provide a dataset designed specifically for this task. Our dataset is recorded in Bonn in a real apple orchard with a variety of sensors, spanning from a terrestrial laser scanner to a RGB-D camera mounted on different robotic platforms. The experiments show that our approach surpasses state-of-the-art approaches in 3D panoptic segmentation in the agricultural domain, while also providing full hierarchical panoptic segmentation. Our dataset has been made publicly available at https://www.ipb.uni-bonn.de/data/hops/. We will provide the open-source implementation of our approach and public competiton for hierarchical panoptic segmentation on the hidden test sets upon paper acceptance.
Open-World Panoptic Segmentation
Dec 17, 2024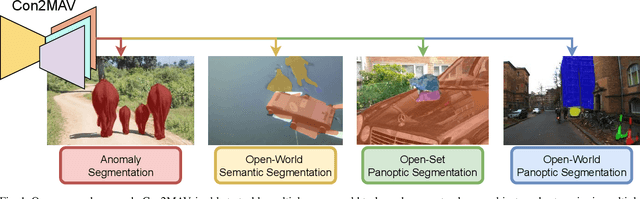
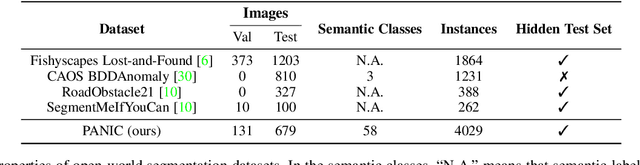

Perception is a key building block of autonomously acting vision systems such as autonomous vehicles. It is crucial that these systems are able to understand their surroundings in order to operate safely and robustly. Additionally, autonomous systems deployed in unconstrained real-world scenarios must be able of dealing with novel situations and object that have never been seen before. In this article, we tackle the problem of open-world panoptic segmentation, i.e., the task of discovering new semantic categories and new object instances at test time, while enforcing consistency among the categories that we incrementally discover. We propose Con2MAV, an approach for open-world panoptic segmentation that extends our previous work, ContMAV, which was developed for open-world semantic segmentation. Through extensive experiments across multiple datasets, we show that our model achieves state-of-the-art results on open-world segmentation tasks, while still performing competitively on the known categories. We will open-source our implementation upon acceptance. Additionally, we propose PANIC (Panoptic ANomalies In Context), a benchmark for evaluating open-world panoptic segmentation in autonomous driving scenarios. This dataset, recorded with a multi-modal sensor suite mounted on a car, provides high-quality, pixel-wise annotations of anomalous objects at both semantic and instance level. Our dataset contains 800 images, with more than 50 unknown classes, i.e., classes that do not appear in the training set, and 4000 object instances, making it an extremely challenging dataset for open-world segmentation tasks in the autonomous driving scenario. We provide competitions for multiple open-world tasks on a hidden test set. Our dataset and competitions are available at https://www.ipb.uni-bonn.de/data/panic.
Human-Inspired Long-Term Indoor Localization in Human-Oriented Environment
Oct 16, 2024Lifelong localization is crucial for enabling the autonomy of service robots. In this paper, we present an overview of our past research on long-term localization and mapping, exploiting geometric priors such as floor plans and integrating textual and semantic information. Our approach was validated on challenging sequences spanning over many months, and we released open source implementations.
Open-World Semantic Segmentation Including Class Similarity
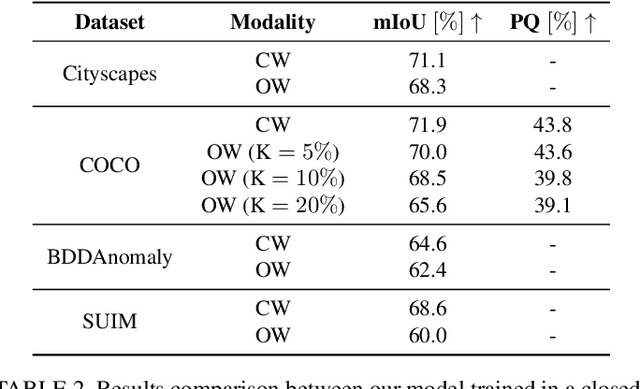
Mar 12, 2024Interpreting camera data is key for autonomously acting systems, such as autonomous vehicles. Vision systems that operate in real-world environments must be able to understand their surroundings and need the ability to deal with novel situations. This paper tackles open-world semantic segmentation, i.e., the variant of interpreting image data in which objects occur that have not been seen during training. We propose a novel approach that performs accurate closed-world semantic segmentation and, at the same time, can identify new categories without requiring any additional training data. Our approach additionally provides a similarity measure for every newly discovered class in an image to a known category, which can be useful information in downstream tasks such as planning or mapping. Through extensive experiments, we show that our model achieves state-of-the-art results on classes known from training data as well as for anomaly segmentation and can distinguish between different unknown classes.
PhenoBench -- A Large Dataset and Benchmarks for Semantic Image Interpretation in the Agricultural Domain
Jun 07, 2023



The production of food, feed, fiber, and fuel is a key task of agriculture. Especially crop production has to cope with a multitude of challenges in the upcoming decades caused by a growing world population, climate change, the need for sustainable production, lack of skilled workers, and generally the limited availability of arable land. Vision systems could help cope with these challenges by offering tools to make better and more sustainable field management decisions and support the breeding of new varieties of crops by allowing temporally dense and reproducible measurements. Recently, tackling perception tasks in the agricultural domain got increasing interest in the computer vision and robotics community since agricultural robotics are one promising solution for coping with the lack of workers and enable a more sustainable agricultural production at the same time. While large datasets and benchmarks in other domains are readily available and have enabled significant progress toward more reliable vision systems, agricultural datasets and benchmarks are comparably rare. In this paper, we present a large dataset and benchmarks for the semantic interpretation of images of real agricultural fields. Our dataset recorded with a UAV provides high-quality, dense annotations of crops and weeds, but also fine-grained labels of crop leaves at the same time, which enable the development of novel algorithms for visual perception in the agricultural domain. Together with the labeled data, we provide novel benchmarks for evaluating different visual perception tasks on a hidden test set comprised of different fields: known fields covered by the training data and a completely unseen field. The tasks cover semantic segmentation, panoptic segmentation of plants, leaf instance segmentation, detection of plants and leaves, and hierarchical panoptic segmentation for jointly identifying plants and leaves.
Long-Term Indoor Localization with Metric-Semantic Mapping using a Floor Plan Prior
Mar 20, 2023Object-based maps are relevant for scene understanding since they integrate geometric and semantic information of the environment, allowing autonomous robots to robustly localize and interact with on objects. In this paper, we address the task of constructing a metric-semantic map for the purpose of long-term object-based localization. We exploit 3D object detections from monocular RGB frames for both, the object-based map construction, and for globally localizing in the constructed map. To tailor the approach to a target environment, we propose an efficient way of generating 3D annotations to finetune the 3D object detection model. We evaluate our map construction in an office building, and test our long-term localization approach on challenging sequences recorded in the same environment over nine months. The experiments suggest that our approach is suitable for constructing metric-semantic maps, and that our localization approach is robust to long-term changes. Both, the mapping algorithm and the localization pipeline can run online on an onboard computer. We will release an open-source C++/ROS implementation of our approach.
Hierarchical Approach for Joint Semantic, Plant Instance, and Leaf Instance Segmentation in the Agricultural Domain
Oct 14, 2022
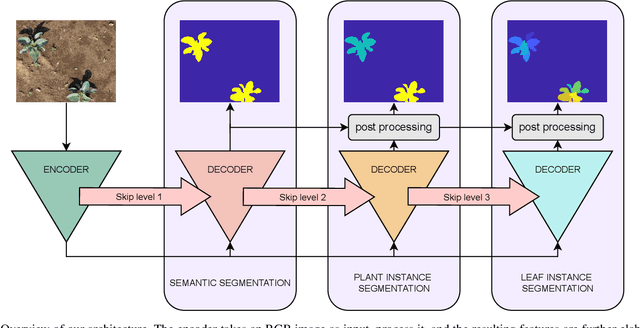


Plant phenotyping is a central task in agriculture, as it describes plants' growth stage, development, and other relevant quantities. Robots can help automate this process by accurately estimating plant traits such as the number of leaves, leaf area, and the plant size. In this paper, we address the problem of joint semantic, plant instance, and leaf instance segmentation of crop fields from RGB data. We propose a single convolutional neural network that addresses the three tasks simultaneously, exploiting their underlying hierarchical structure. We introduce task-specific skip connections, which our experimental evaluation proves to be more beneficial than the usual schemes. We also propose a novel automatic post-processing, which explicitly addresses the problem of spatially close instances, common in the agricultural domain because of overlapping leaves. Our architecture simultaneously tackles these problems jointly in the agricultural context. Previous works either focus on plant or leaf segmentation, or do not optimise for semantic segmentation. Results show that our system has superior performance to state-of-the-art approaches, while having a reduced number of parameters and is operating at camera frame rate.
Robust Double-Encoder Network for RGB-D Panoptic Segmentation
Oct 06, 2022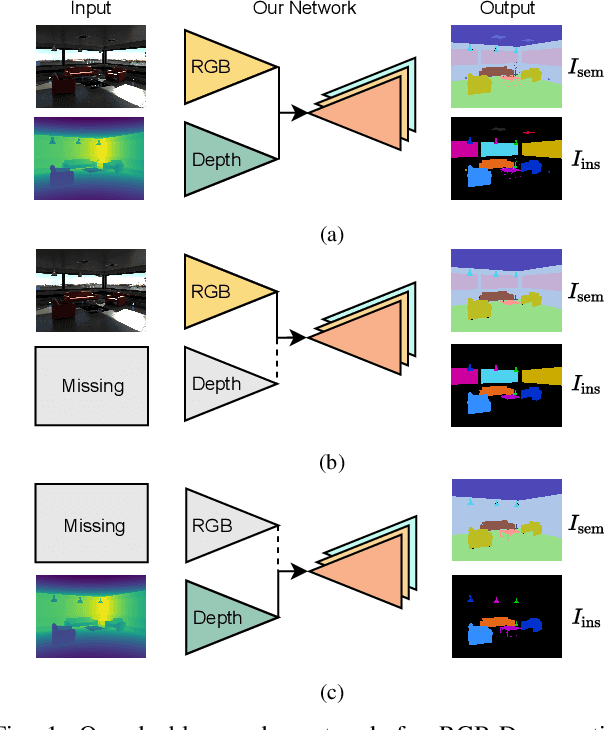
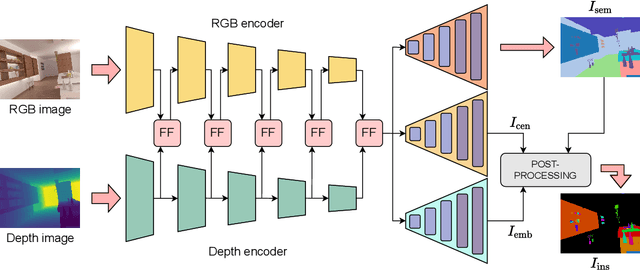


Perception is crucial for robots that act in real-world environments, as autonomous systems need to see and understand the world around them to act appropriately. Panoptic segmentation provides an interpretation of the scene by computing a pixel-wise semantic label together with instance IDs. In this paper, we address panoptic segmentation using RGB-D data of indoor scenes. We propose a novel encoder-decoder neural network that processes RGB and depth separately through two encoders. The features of the individual encoders are progressively merged at different resolutions, such that the RGB features are enhanced using complementary depth information. We propose a novel merging approach called ResidualExcite, which reweighs each entry of the feature map according to its importance. With our double-encoder architecture, we are robust to missing cues. In particular, the same model can train and infer on RGB-D, RGB-only, and depth-only input data, without the need to train specialized models. We evaluate our method on publicly available datasets and show that our approach achieves superior results compared to other common approaches for panoptic segmentation.