 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAHA: Supervised Autonomous HArvester for selective forest thinning
Jan 03, 2026Forestry plays a vital role in our society, creating significant ecological, economic, and recreational value. Efficient forest management involves labor-intensive and complex operations. One essential task for maintaining forest health and productivity is selective thinning, which requires skilled operators to remove specific trees to create optimal growing conditions for the remaining ones. In this work, we present a solution based on a small-scale robotic harvester (SAHA) designed for executing this task with supervised autonomy. We build on a 4.5-ton harvester platform and implement key hardware modifications for perception and automatic control. We implement learning- and model-based approaches for precise control of hydraulic actuators, accurate navigation through cluttered environments, robust state estimation, and reliable semantic estimation of terrain traversability. Integrating state-of-the-art techniques in perception, planning, and control, our robotic harvester can autonomously navigate forest environments and reach targeted trees for selective thinning. We present experimental results from extensive field trials over kilometer-long autonomous missions in northern European forests, demonstrating the harvester's ability to operate in real forests. We analyze the performance and provide the lessons learned for advancing robotic forest management.
SemRaFiner: Panoptic Segmentation in Sparse and Noisy Radar Point Clouds
Jul 09, 2025Semantic scene understanding, including the perception and classification of moving agents, is essential to enabling safe and robust driving behaviours of autonomous vehicles. Cameras and LiDARs are commonly used for semantic scene understanding. However, both sensor modalities face limitations in adverse weather and usually do not provide motion information. Radar sensors overcome these limitations and directly offer information about moving agents by measuring the Doppler velocity, but the measurements are comparably sparse and noisy. In this paper, we address the problem of panoptic segmentation in sparse radar point clouds to enhance scene understanding. Our approach, called SemRaFiner, accounts for changing density in sparse radar point clouds and optimizes the feature extraction to improve accuracy. Furthermore, we propose an optimized training procedure to refine instance assignments by incorporating a dedicated data augmentation. Our experiments suggest that our approach outperforms state-of-the-art methods for radar-based panoptic segmentation.
Coherent Online Road Topology Estimation and Reasoning with Standard-Definition Maps
Jul 02, 2025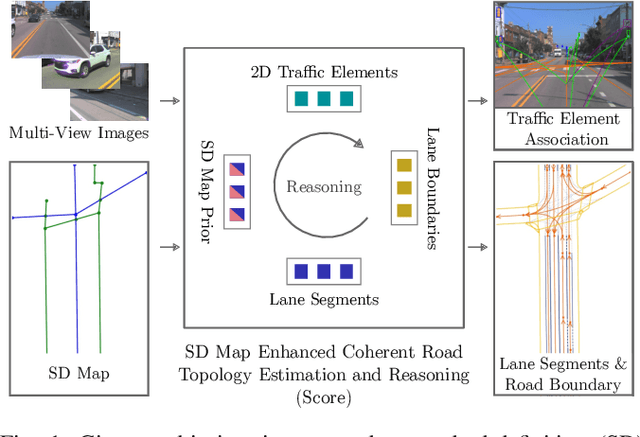
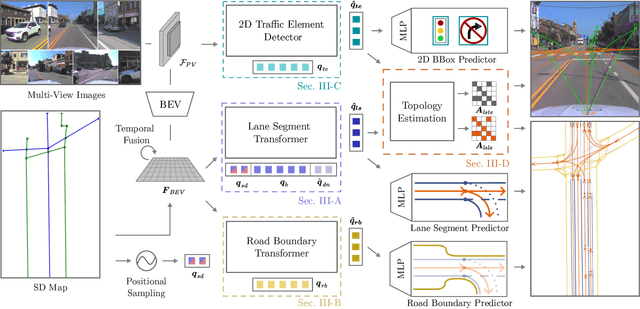
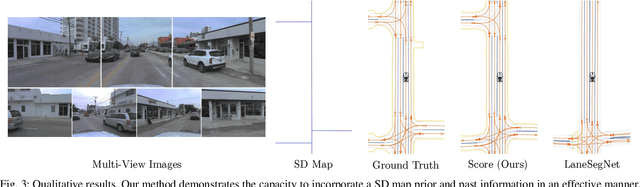
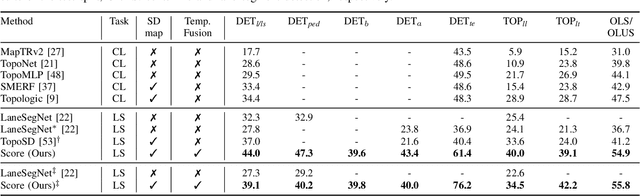
Most autonomous cars rely on the availability of high-definition (HD) maps. Current research aims to address this constraint by directly predicting HD map elements from onboard sensors and reasoning about the relationships between the predicted map and traffic elements. Despite recent advancements, the coherent online construction of HD maps remains a challenging endeavor, as it necessitates modeling the high complexity of road topologies in a unified and consistent manner. To address this challenge, we propose a coherent approach to predict lane segments and their corresponding topology, as well as road boundaries, all by leveraging prior map information represented by commonly available standard-definition (SD) maps. We propose a network architecture, which leverages hybrid lane segment encodings comprising prior information and denoising techniques to enhance training stability and performance. Furthermore, we facilitate past frames for temporal consistency. Our experimental evaluation demonstrates that our approach outperforms previous methods by a large margin, highlighting the benefits of our modeling scheme.
Improving Indoor Localization Accuracy by Using an Efficient Implicit Neural Map Representation
Mar 30, 2025Globally localizing a mobile robot in a known map is often a foundation for enabling robots to navigate and operate autonomously. In indoor environments, traditional Monte Carlo localization based on occupancy grid maps is considered the gold standard, but its accuracy is limited by the representation capabilities of the occupancy grid map. In this paper, we address the problem of building an effective map representation that allows to accurately perform probabilistic global localization. To this end, we propose an implicit neural map representation that is able to capture positional and directional geometric features from 2D LiDAR scans to efficiently represent the environment and learn a neural network that is able to predict both, the non-projective signed distance and a direction-aware projective distance for an arbitrary point in the mapped environment. This combination of neural map representation with a light-weight neural network allows us to design an efficient observation model within a conventional Monte Carlo localization framework for pose estimation of a robot in real time. We evaluated our approach to indoor localization on a publicly available dataset for global localization and the experimental results indicate that our approach is able to more accurately localize a mobile robot than other localization approaches employing occupancy or existing neural map representations. In contrast to other approaches employing an implicit neural map representation for 2D LiDAR localization, our approach allows to perform real-time pose tracking after convergence and near real-time global localization. The code of our approach is available at: https://github.com/PRBonn/enm-mcl.
Towards Generating Realistic 3D Semantic Training Data for Autonomous Driving
Mar 27, 2025



Semantic scene understanding is crucial for robotics and computer vision applications. In autonomous driving, 3D semantic segmentation plays an important role for enabling safe navigation. Despite significant advances in the field, the complexity of collecting and annotating 3D data is a bottleneck in this developments. To overcome that data annotation limitation, synthetic simulated data has been used to generate annotated data on demand. There is still however a domain gap between real and simulated data. More recently, diffusion models have been in the spotlight, enabling close-to-real data synthesis. Those generative models have been recently applied to the 3D data domain for generating scene-scale data with semantic annotations. Still, those methods either rely on image projection or decoupled models trained with different resolutions in a coarse-to-fine manner. Such intermediary representations impact the generated data quality due to errors added in those transformations. In this work, we propose a novel approach able to generate 3D semantic scene-scale data without relying on any projection or decoupled trained multi-resolution models, achieving more realistic semantic scene data generation compared to previous state-of-the-art methods. Besides improving 3D semantic scene-scale data synthesis, we thoroughly evaluate the use of the synthetic scene samples as labeled data to train a semantic segmentation network. In our experiments, we show that using the synthetic annotated data generated by our method as training data together with the real semantic segmentation labels, leads to an improvement in the semantic segmentation model performance. Our results show the potential of generated scene-scale point clouds to generate more training data to extend existing datasets, reducing the data annotation effort. Our code is available at https://github.com/PRBonn/3DiSS.
3D Hierarchical Panoptic Segmentation in Real Orchard Environments Across Different Sensors
Mar 17, 2025Crop yield estimation is a relevant problem in agriculture, because an accurate crop yield estimate can support farmers' decisions on harvesting or precision intervention. Robots can help to automate this process. To do so, they need to be able to perceive the surrounding environment to identify target objects. In this paper, we introduce a novel approach to address the problem of hierarchical panoptic segmentation of apple orchards on 3D data from different sensors. Our approach is able to simultaneously provide semantic segmentation, instance segmentation of trunks and fruits, and instance segmentation of plants (a single trunk with its fruits). This allows us to identify relevant information such as individual plants, fruits, and trunks, and capture the relationship among them, such as precisely estimate the number of fruits associated to each tree in an orchard. Additionally, to efficiently evaluate our approach for hierarchical panoptic segmentation, we provide a dataset designed specifically for this task. Our dataset is recorded in Bonn in a real apple orchard with a variety of sensors, spanning from a terrestrial laser scanner to a RGB-D camera mounted on different robotic platforms. The experiments show that our approach surpasses state-of-the-art approaches in 3D panoptic segmentation in the agricultural domain, while also providing full hierarchical panoptic segmentation. Our dataset has been made publicly available at https://www.ipb.uni-bonn.de/data/hops/. We will provide the open-source implementation of our approach and public competiton for hierarchical panoptic segmentation on the hidden test sets upon paper acceptance.
PINGS: Gaussian Splatting Meets Distance Fields within a Point-Based Implicit Neural Map
Feb 09, 2025Robots require high-fidelity reconstructions of their environment for effective operation. Such scene representations should be both, geometrically accurate and photorealistic to support downstream tasks. While this can be achieved by building distance fields from range sensors and radiance fields from cameras, the scalable incremental mapping of both fields consistently and at the same time with high quality remains challenging. In this paper, we propose a novel map representation that unifies a continuous signed distance field and a Gaussian splatting radiance field within an elastic and compact point-based implicit neural map. By enforcing geometric consistency between these fields, we achieve mutual improvements by exploiting both modalities. We devise a LiDAR-visual SLAM system called PINGS using the proposed map representation and evaluate it on several challenging large-scale datasets. Experimental results demonstrate that PINGS can incrementally build globally consistent distance and radiance fields encoded with a compact set of neural points. Compared to the state-of-the-art methods, PINGS achieves superior photometric and geometric rendering at novel views by leveraging the constraints from the distance field. Furthermore, by utilizing dense photometric cues and multi-view consistency from the radiance field, PINGS produces more accurate distance fields, leading to improved odometry estimation and mesh reconstruction.
ActiveGS: Active Scene Reconstruction using Gaussian Splatting
Dec 23, 2024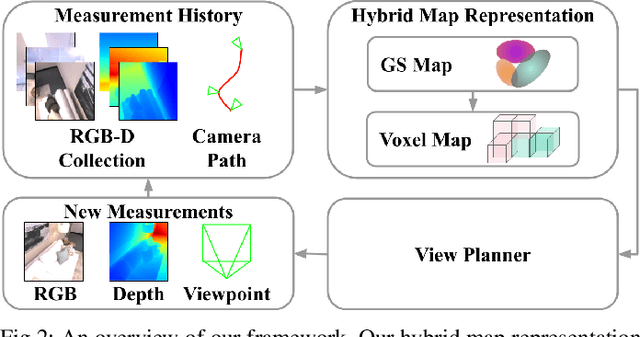
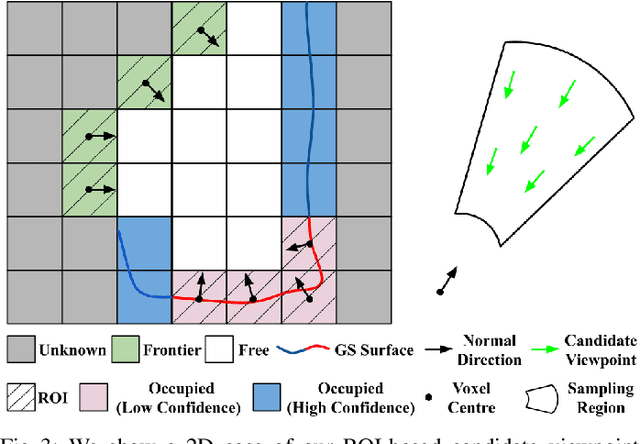
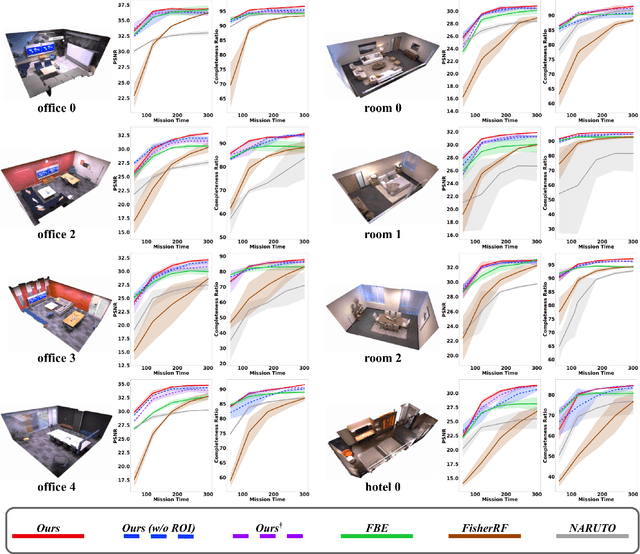

Robotics applications often rely on scene reconstructions to enable downstream tasks. In this work, we tackle the challenge of actively building an accurate map of an unknown scene using an on-board RGB-D camera. We propose a hybrid map representation that combines a Gaussian splatting map with a coarse voxel map, leveraging the strengths of both representations: the high-fidelity scene reconstruction capabilities of Gaussian splatting and the spatial modelling strengths of the voxel map. The core of our framework is an effective confidence modelling technique for the Gaussian splatting map to identify under-reconstructed areas, while utilising spatial information from the voxel map to target unexplored areas and assist in collision-free path planning. By actively collecting scene information in under-reconstructed and unexplored areas for map updates, our approach achieves superior Gaussian splatting reconstruction results compared to state-of-the-art approaches. Additionally, we demonstrate the applicability of our active scene reconstruction framework in the real world using an unmanned aerial vehicle.
Open-World Panoptic Segmentation
Dec 17, 2024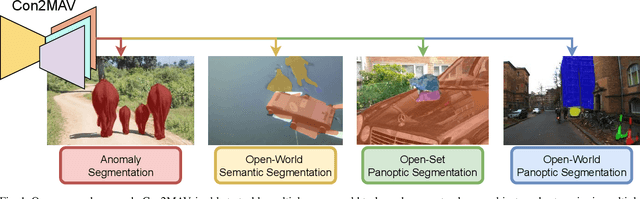

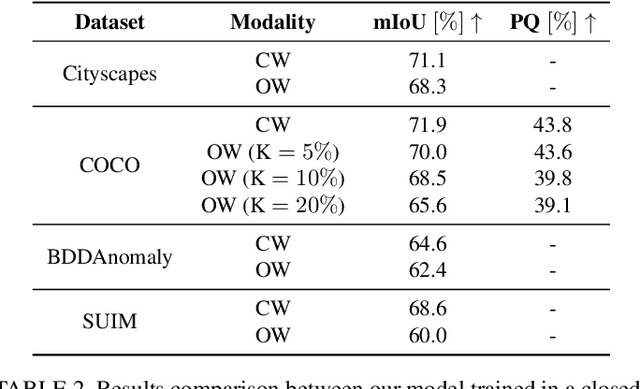
Perception is a key building block of autonomously acting vision systems such as autonomous vehicles. It is crucial that these systems are able to understand their surroundings in order to operate safely and robustly. Additionally, autonomous systems deployed in unconstrained real-world scenarios must be able of dealing with novel situations and object that have never been seen before. In this article, we tackle the problem of open-world panoptic segmentation, i.e., the task of discovering new semantic categories and new object instances at test time, while enforcing consistency among the categories that we incrementally discover. We propose Con2MAV, an approach for open-world panoptic segmentation that extends our previous work, ContMAV, which was developed for open-world semantic segmentation. Through extensive experiments across multiple datasets, we show that our model achieves state-of-the-art results on open-world segmentation tasks, while still performing competitively on the known categories. We will open-source our implementation upon acceptance. Additionally, we propose PANIC (Panoptic ANomalies In Context), a benchmark for evaluating open-world panoptic segmentation in autonomous driving scenarios. This dataset, recorded with a multi-modal sensor suite mounted on a car, provides high-quality, pixel-wise annotations of anomalous objects at both semantic and instance level. Our dataset contains 800 images, with more than 50 unknown classes, i.e., classes that do not appear in the training set, and 4000 object instances, making it an extremely challenging dataset for open-world segmentation tasks in the autonomous driving scenario. We provide competitions for multiple open-world tasks on a hidden test set. Our dataset and competitions are available at https://www.ipb.uni-bonn.de/data/panic.
Efficient LiDAR Bundle Adjustment for Multi-Scan Alignment Utilizing Continuous-Time Trajectories
Dec 16, 2024Constructing precise global maps is a key task in robotics and is required for localization, surveying, monitoring, or constructing digital twins. To build accurate maps, data from mobile 3D LiDAR sensors is often used. Mapping requires correctly aligning the individual point clouds to each other to obtain a globally consistent map. In this paper, we investigate the problem of multi-scan alignment to obtain globally consistent point cloud maps. We propose a 3D LiDAR bundle adjustment approach to solve the global alignment problem and jointly optimize the available data. Utilizing a continuous-time trajectory allows us to consider the ego-motion of the LiDAR scanner while recording a single scan directly in the least squares adjustment. Furthermore, pruning the search space of correspondences and utilizing out-of-core circular buffer enables our approach to align thousands of point clouds efficiently. We successfully align point clouds recorded with a handheld LiDAR, as well as ones mounted on a vehicle, and are able to perform multi-session alignment.