 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorticultural Temporal Fruit Monitoring via 3D Instance Segmentation and Re-Identification using Point Clouds
Nov 12, 2024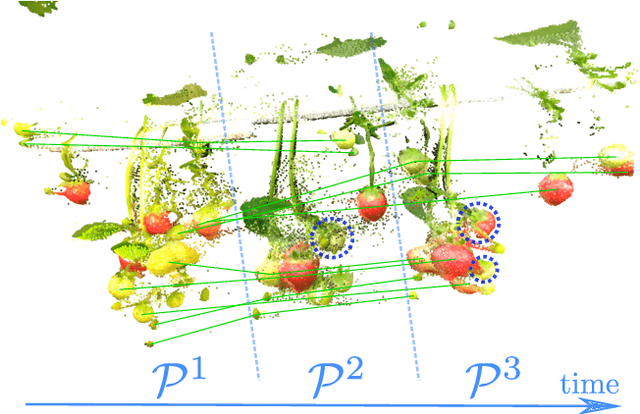
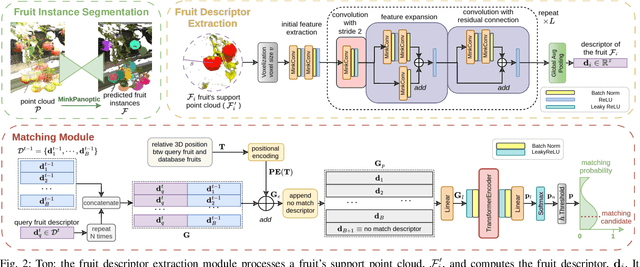

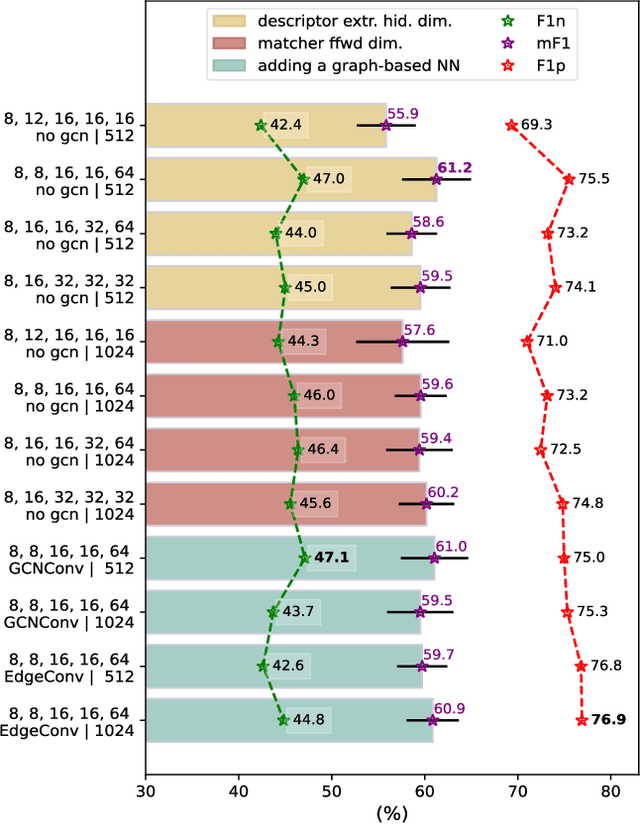
Robotic fruit monitoring is a key step toward automated agricultural production systems. Robots can significantly enhance plant and temporal fruit monitoring by providing precise, high-throughput assessments that overcome the limitations of traditional manual methods. Fruit monitoring is a challenging task due to the significant variation in size, shape, orientation, and occlusion of fruits. Also, fruits may be harvested or newly grown between recording sessions. Most methods are 2D image-based and they lack the 3D structure, depth, and spatial information, which represent key aspects of fruit monitoring. 3D colored point clouds, instead, can offer this information but they introduce challenges such as their sparsity and irregularity. In this paper, we present a novel approach for temporal fruit monitoring that addresses point clouds collected in a greenhouse over time. Our method segments fruits using a learning-based instance segmentation approach directly on the point cloud. Each segmented fruit is processed by a 3D sparse convolutional neural network to extract descriptors, which are used in an attention-based matching network to associate fruits with their instances from previous data collections. Experimental results on a real dataset of strawberries demonstrate that our approach outperforms other methods for fruits re-identification over time, allowing for precise temporal fruit monitoring in real and complex scenarios.
Multi-Modal 3D Scene Graph Updater for Shared and Dynamic Environments
Nov 05, 2024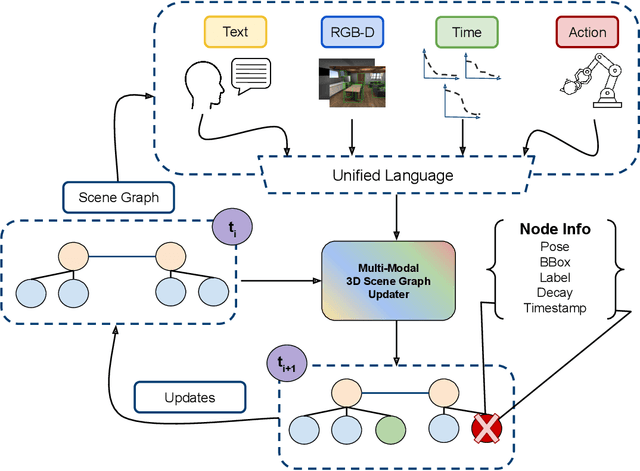

The advent of generalist Large Language Models (LLMs) and Large Vision Models (VLMs) have streamlined the construction of semantically enriched maps that can enable robots to ground high-level reasoning and planning into their representations. One of the most widely used semantic map formats is the 3D Scene Graph, which captures both metric (low-level) and semantic (high-level) information. However, these maps often assume a static world, while real environments, like homes and offices, are dynamic. Even small changes in these spaces can significantly impact task performance. To integrate robots into dynamic environments, they must detect changes and update the scene graph in real-time. This update process is inherently multimodal, requiring input from various sources, such as human agents, the robot's own perception system, time, and its actions. This work proposes a framework that leverages these multimodal inputs to maintain the consistency of scene graphs during real-time operation, presenting promising initial results and outlining a roadmap for future research.
Exploiting Local Features and Range Images for Small Data Real-Time Point Cloud Semantic Segmentation
Oct 14, 2024



Semantic segmentation of point clouds is an essential task for understanding the environment in autonomous driving and robotics. Recent range-based works achieve real-time efficiency, while point- and voxel-based methods produce better results but are affected by high computational complexity. Moreover, highly complex deep learning models are often not suited to efficiently learn from small datasets. Their generalization capabilities can easily be driven by the abundance of data rather than the architecture design. In this paper, we harness the information from the three-dimensional representation to proficiently capture local features, while introducing the range image representation to incorporate additional information and facilitate fast computation. A GPU-based KDTree allows for rapid building, querying, and enhancing projection with straightforward operations. Extensive experiments on SemanticKITTI and nuScenes datasets demonstrate the benefits of our modification in a ``small data'' setup, in which only one sequence of the dataset is used to train the models, but also in the conventional setup, where all sequences except one are used for training. We show that a reduced version of our model not only demonstrates strong competitiveness against full-scale state-of-the-art models but also operates in real-time, making it a viable choice for real-world case applications. The code of our method is available at https://github.com/Bender97/WaffleAndRange.
IPC: Incremental Probabilistic Consensus-based Consistent Set Maximization for SLAM Backends
May 14, 2024In SLAM (Simultaneous localization and mapping) problems, Pose Graph Optimization (PGO) is a technique to refine an initial estimate of a set of poses (positions and orientations) from a set of pairwise relative measurements. The optimization procedure can be negatively affected even by a single outlier measurement, with possible catastrophic and meaningless results. Although recent works on robust optimization aim to mitigate the presence of outlier measurements, robust solutions capable of handling large numbers of outliers are yet to come. This paper presents IPC, acronym for Incremental Probabilistic Consensus, a method that approximates the solution to the combinatorial problem of finding the maximally consistent set of measurements in an incremental fashion. It evaluates the consistency of each loop closure measurement through a consensus-based procedure, possibly applied to a subset of the global problem, where all previously integrated inlier measurements have veto power. We evaluated IPC on standard benchmarks against several state-of-the-art methods. Although it is simple and relatively easy to implement, IPC competes with or outperforms the other tested methods in handling outliers while providing online performances. We release with this paper an open-source implementation of the proposed method.
* This paper has been accepted for publication at the 2024 IEEE International Conference on Robotics and Automation (ICRA)
A Sonar-based AUV Positioning System for Underwater Environments with Low Infrastructure Density
May 03, 2024The increasing demand for underwater vehicles highlights the necessity for robust localization solutions in inspection missions. In this work, we present a novel real-time sonar-based underwater global positioning algorithm for AUVs (Autonomous Underwater Vehicles) designed for environments with a sparse distribution of human-made assets. Our approach exploits two synergistic data interpretation frontends applied to the same stream of sonar data acquired by a multibeam Forward-Looking Sonar (FSD). These observations are fused within a Particle Filter (PF) either to weigh more particles that belong to high-likelihood regions or to solve symmetric ambiguities. Preliminary experiments carried out on a simulated environment resembling a real underwater plant provided promising results. This work represents a starting point towards future developments of the method and consequent exhaustive evaluations also in real-world scenarios.
* Accepted to the IEEE ICRA Workshop on Field Robotics 2024
CombiNeRF: A Combination of Regularization Techniques for Few-Shot Neural Radiance Field View Synthesis
Mar 21, 2024Neural Radiance Fields (NeRFs) have shown impressive results for novel view synthesis when a sufficiently large amount of views are available. When dealing with few-shot settings, i.e. with a small set of input views, the training could overfit those views, leading to artifacts and geometric and chromatic inconsistencies in the resulting rendering. Regularization is a valid solution that helps NeRF generalization. On the other hand, each of the most recent NeRF regularization techniques aim to mitigate a specific rendering problem. Starting from this observation, in this paper we propose CombiNeRF, a framework that synergically combines several regularization techniques, some of them novel, in order to unify the benefits of each. In particular, we regularize single and neighboring rays distributions and we add a smoothness term to regularize near geometries. After these geometric approaches, we propose to exploit Lipschitz regularization to both NeRF density and color networks and to use encoding masks for input features regularization. We show that CombiNeRF outperforms the state-of-the-art methods with few-shot settings in several publicly available datasets. We also present an ablation study on the LLFF and NeRF-Synthetic datasets that support the choices made. We release with this paper the open-source implementation of our framework.
* This paper has been accepted for publication at the 2024 International Conference on 3D Vision (3DV)
Improving Generalization of Synthetically Trained Sonar Image Descriptors for Underwater Place Recognition
Aug 02, 2023Autonomous navigation in underwater environments presents challenges due to factors such as light absorption and water turbidity, limiting the effectiveness of optical sensors. Sonar systems are commonly used for perception in underwater operations as they are unaffected by these limitations. Traditional computer vision algorithms are less effective when applied to sonar-generated acoustic images, while convolutional neural networks (CNNs) typically require large amounts of labeled training data that are often unavailable or difficult to acquire. To this end, we propose a novel compact deep sonar descriptor pipeline that can generalize to real scenarios while being trained exclusively on synthetic data. Our architecture is based on a ResNet18 back-end and a properly parameterized random Gaussian projection layer, whereas input sonar data is enhanced with standard ad-hoc normalization/prefiltering techniques. A customized synthetic data generation procedure is also presented. The proposed method has been evaluated extensively using both synthetic and publicly available real data, demonstrating its effectiveness compared to state-of-the-art methods.
KVN: Keypoints Voting Network with Differentiable RANSAC for Stereo Pose Estimation
Jul 21, 2023

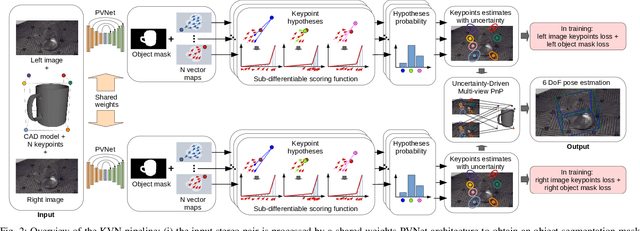

Object pose estimation is a fundamental computer vision task exploited in several robotics and augmented reality applications. Many established approaches rely on predicting 2D-3D keypoint correspondences using RANSAC (Random sample consensus) and estimating the object pose using the PnP (Perspective-n-Point) algorithm. Being RANSAC non-differentiable, correspondences cannot be directly learned in an end-to-end fashion. In this paper, we address the stereo image-based object pose estimation problem by (i) introducing a differentiable RANSAC layer into a well-known monocular pose estimation network; (ii) exploiting an uncertainty-driven multi-view PnP solver which can fuse information from multiple views. We evaluate our approach on a challenging public stereo object pose estimation dataset, yielding state-of-the-art results against other recent approaches. Furthermore, in our ablation study, we show that the differentiable RANSAC layer plays a significant role in the accuracy of the proposed method. We release with this paper the open-source implementation of our method.
A Graph-based Optimization Framework for Hand-Eye Calibration for Multi-Camera Setups
Mar 08, 2023



Hand-eye calibration is the problem of estimating the spatial transformation between a reference frame, usually the base of a robot arm or its gripper, and the reference frame of one or multiple cameras. Generally, this calibration is solved as a non-linear optimization problem, what instead is rarely done is to exploit the underlying graph structure of the problem itself. Actually, the problem of hand-eye calibration can be seen as an instance of the Simultaneous Localization and Mapping (SLAM) problem. Inspired by this fact, in this work we present a pose-graph approach to the hand-eye calibration problem that extends a recent state-of-the-art solution in two different ways: i) by formulating the solution to eye-on-base setups with one camera; ii) by covering multi-camera robotic setups. The proposed approach has been validated in simulation against standard hand-eye calibration methods. Moreover, a real application is shown. In both scenarios, the proposed approach overcomes all alternative methods. We release with this paper an open-source implementation of our graph-based optimization framework for multi-camera setups.
Software Architecture for Mobile Robots
Jun 07, 2022
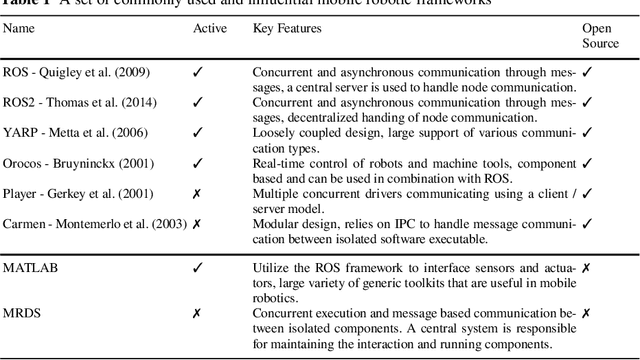

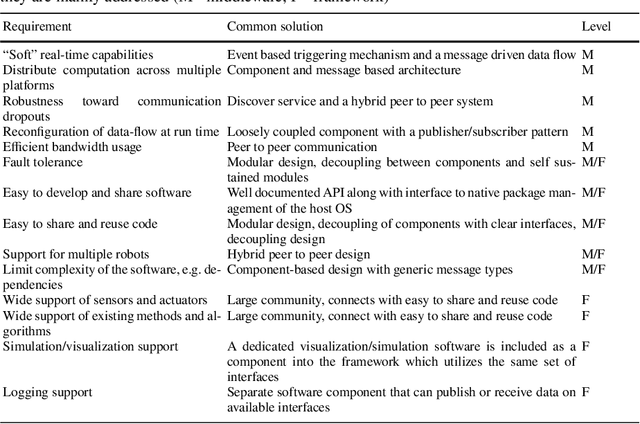
A software architecture defines the blueprints of a large computational system, and is thus a crucial part of the design and development effort. This task has been explored extensively in the context of mobile robots, resulting in a plethora of reference designs and implementations. As the software architecture defines the framework in which all components are implemented, it is naturally a very important aspect of a mobile robot system. In this chapter, we overview the requirements that the particular problem domain (a mobile robot system) imposes on the software framework. We discuss some of the current design solutions, provide a historical perspective on common frameworks, and outline directions for future development.