 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombiNeRF: A Combination of Regularization Techniques for Few-Shot Neural Radiance Field View Synthesis
Mar 21, 2024Neural Radiance Fields (NeRFs) have shown impressive results for novel view synthesis when a sufficiently large amount of views are available. When dealing with few-shot settings, i.e. with a small set of input views, the training could overfit those views, leading to artifacts and geometric and chromatic inconsistencies in the resulting rendering. Regularization is a valid solution that helps NeRF generalization. On the other hand, each of the most recent NeRF regularization techniques aim to mitigate a specific rendering problem. Starting from this observation, in this paper we propose CombiNeRF, a framework that synergically combines several regularization techniques, some of them novel, in order to unify the benefits of each. In particular, we regularize single and neighboring rays distributions and we add a smoothness term to regularize near geometries. After these geometric approaches, we propose to exploit Lipschitz regularization to both NeRF density and color networks and to use encoding masks for input features regularization. We show that CombiNeRF outperforms the state-of-the-art methods with few-shot settings in several publicly available datasets. We also present an ablation study on the LLFF and NeRF-Synthetic datasets that support the choices made. We release with this paper the open-source implementation of our framework.
* This paper has been accepted for publication at the 2024 International Conference on 3D Vision (3DV)
Improving Generalization of Synthetically Trained Sonar Image Descriptors for Underwater Place Recognition
Aug 02, 2023Autonomous navigation in underwater environments presents challenges due to factors such as light absorption and water turbidity, limiting the effectiveness of optical sensors. Sonar systems are commonly used for perception in underwater operations as they are unaffected by these limitations. Traditional computer vision algorithms are less effective when applied to sonar-generated acoustic images, while convolutional neural networks (CNNs) typically require large amounts of labeled training data that are often unavailable or difficult to acquire. To this end, we propose a novel compact deep sonar descriptor pipeline that can generalize to real scenarios while being trained exclusively on synthetic data. Our architecture is based on a ResNet18 back-end and a properly parameterized random Gaussian projection layer, whereas input sonar data is enhanced with standard ad-hoc normalization/prefiltering techniques. A customized synthetic data generation procedure is also presented. The proposed method has been evaluated extensively using both synthetic and publicly available real data, demonstrating its effectiveness compared to state-of-the-art methods.
A Graph-based Optimization Framework for Hand-Eye Calibration for Multi-Camera Setups
Mar 08, 2023



Hand-eye calibration is the problem of estimating the spatial transformation between a reference frame, usually the base of a robot arm or its gripper, and the reference frame of one or multiple cameras. Generally, this calibration is solved as a non-linear optimization problem, what instead is rarely done is to exploit the underlying graph structure of the problem itself. Actually, the problem of hand-eye calibration can be seen as an instance of the Simultaneous Localization and Mapping (SLAM) problem. Inspired by this fact, in this work we present a pose-graph approach to the hand-eye calibration problem that extends a recent state-of-the-art solution in two different ways: i) by formulating the solution to eye-on-base setups with one camera; ii) by covering multi-camera robotic setups. The proposed approach has been validated in simulation against standard hand-eye calibration methods. Moreover, a real application is shown. In both scenarios, the proposed approach overcomes all alternative methods. We release with this paper an open-source implementation of our graph-based optimization framework for multi-camera setups.
Pushing the Limits of Learning-based Traversability Analysis for Autonomous Driving on CPU
Jun 07, 2022
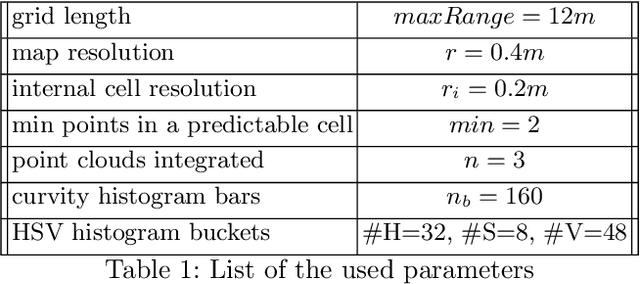

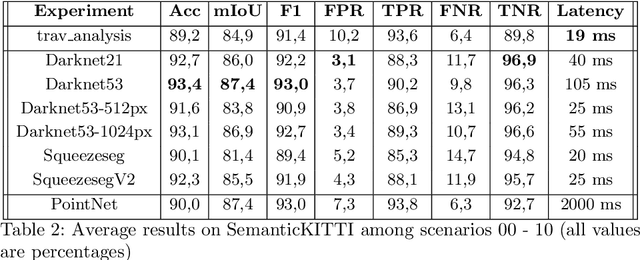
Self-driving vehicles and autonomous ground robots require a reliable and accurate method to analyze the traversability of the surrounding environment for safe navigation. This paper proposes and evaluates a real-time machine learning-based Traversability Analysis method that combines geometric features with appearance-based features in a hybrid approach based on a SVM classifier. In particular, we show that integrating a new set of geometric and visual features and focusing on important implementation details enables a noticeable boost in performance and reliability. The proposed approach has been compared with state-of-the-art Deep Learning approaches on a public dataset of outdoor driving scenarios. It reaches an accuracy of 89.2% in scenarios of varying complexity, demonstrating its effectiveness and robustness. The method runs fully on CPU and reaches comparable results with respect to the other methods, operates faster, and requires fewer hardware resources.
Learning to Segment Human Body Parts with Synthetically Trained Deep Convolutional Networks
Feb 02, 2021
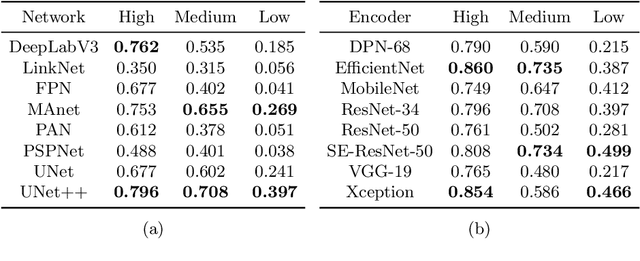
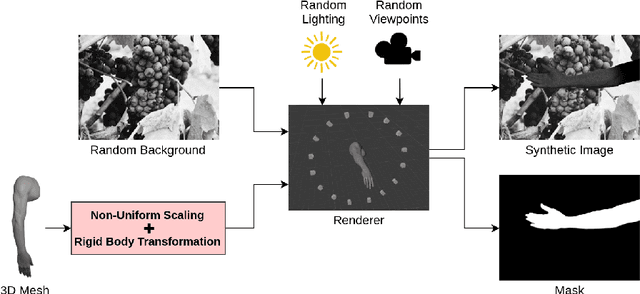

This paper presents a new framework for human body part segmentation based on Deep Convolutional Neural Networks trained using only synthetic data. The proposed approach achieves cutting-edge results without the need of training the models with real annotated data of human body parts. Our contributions include a data generation pipeline, that exploits a game engine for the creation of the synthetic data used for training the network, and a novel pre-processing module, that combines edge response map and adaptive histogram equalization to guide the network to learn the shape of the human body parts ensuring robustness to changes in the illumination conditions. For selecting the best candidate architecture, we performed exhaustive tests on manually-annotated images of real human body limbs. We further present an ablation study to validate our pre-processing module. The results show that our method outperforms several state-of-the-art semantic segmentation networks by a large margin. We release an implementation of the proposed approach along with the acquired datasets with this paper.