 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Hierarchical Panoptic Segmentation in Real Orchard Environments Across Different Sensors
Mar 17, 2025Crop yield estimation is a relevant problem in agriculture, because an accurate crop yield estimate can support farmers' decisions on harvesting or precision intervention. Robots can help to automate this process. To do so, they need to be able to perceive the surrounding environment to identify target objects. In this paper, we introduce a novel approach to address the problem of hierarchical panoptic segmentation of apple orchards on 3D data from different sensors. Our approach is able to simultaneously provide semantic segmentation, instance segmentation of trunks and fruits, and instance segmentation of plants (a single trunk with its fruits). This allows us to identify relevant information such as individual plants, fruits, and trunks, and capture the relationship among them, such as precisely estimate the number of fruits associated to each tree in an orchard. Additionally, to efficiently evaluate our approach for hierarchical panoptic segmentation, we provide a dataset designed specifically for this task. Our dataset is recorded in Bonn in a real apple orchard with a variety of sensors, spanning from a terrestrial laser scanner to a RGB-D camera mounted on different robotic platforms. The experiments show that our approach surpasses state-of-the-art approaches in 3D panoptic segmentation in the agricultural domain, while also providing full hierarchical panoptic segmentation. Our dataset has been made publicly available at https://www.ipb.uni-bonn.de/data/hops/. We will provide the open-source implementation of our approach and public competiton for hierarchical panoptic segmentation on the hidden test sets upon paper acceptance.
Open-World Panoptic Segmentation
Dec 17, 2024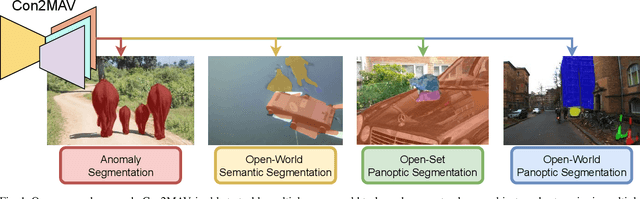
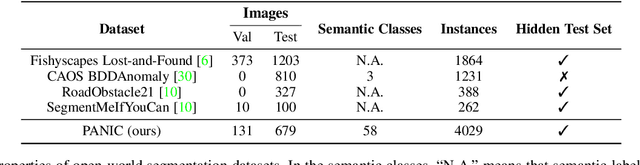

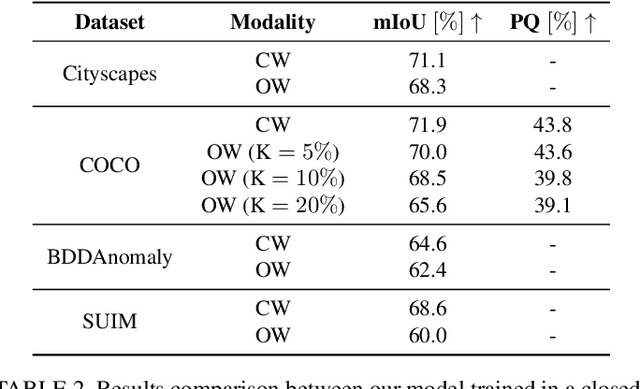
Perception is a key building block of autonomously acting vision systems such as autonomous vehicles. It is crucial that these systems are able to understand their surroundings in order to operate safely and robustly. Additionally, autonomous systems deployed in unconstrained real-world scenarios must be able of dealing with novel situations and object that have never been seen before. In this article, we tackle the problem of open-world panoptic segmentation, i.e., the task of discovering new semantic categories and new object instances at test time, while enforcing consistency among the categories that we incrementally discover. We propose Con2MAV, an approach for open-world panoptic segmentation that extends our previous work, ContMAV, which was developed for open-world semantic segmentation. Through extensive experiments across multiple datasets, we show that our model achieves state-of-the-art results on open-world segmentation tasks, while still performing competitively on the known categories. We will open-source our implementation upon acceptance. Additionally, we propose PANIC (Panoptic ANomalies In Context), a benchmark for evaluating open-world panoptic segmentation in autonomous driving scenarios. This dataset, recorded with a multi-modal sensor suite mounted on a car, provides high-quality, pixel-wise annotations of anomalous objects at both semantic and instance level. Our dataset contains 800 images, with more than 50 unknown classes, i.e., classes that do not appear in the training set, and 4000 object instances, making it an extremely challenging dataset for open-world segmentation tasks in the autonomous driving scenario. We provide competitions for multiple open-world tasks on a hidden test set. Our dataset and competitions are available at https://www.ipb.uni-bonn.de/data/panic.
Horticultural Temporal Fruit Monitoring via 3D Instance Segmentation and Re-Identification using Point Clouds
Nov 12, 2024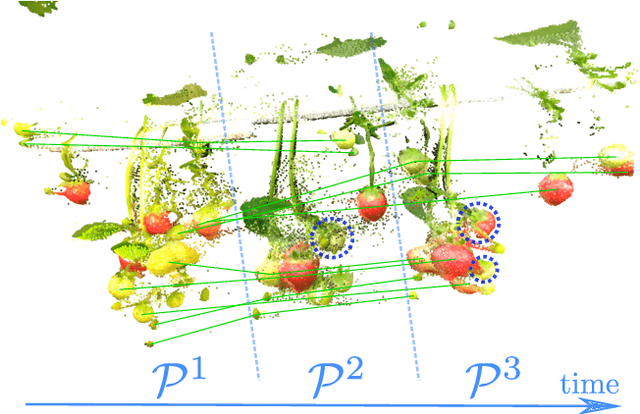
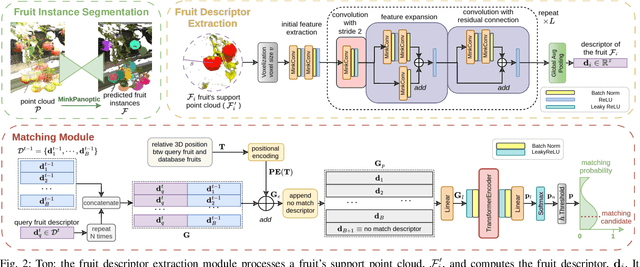

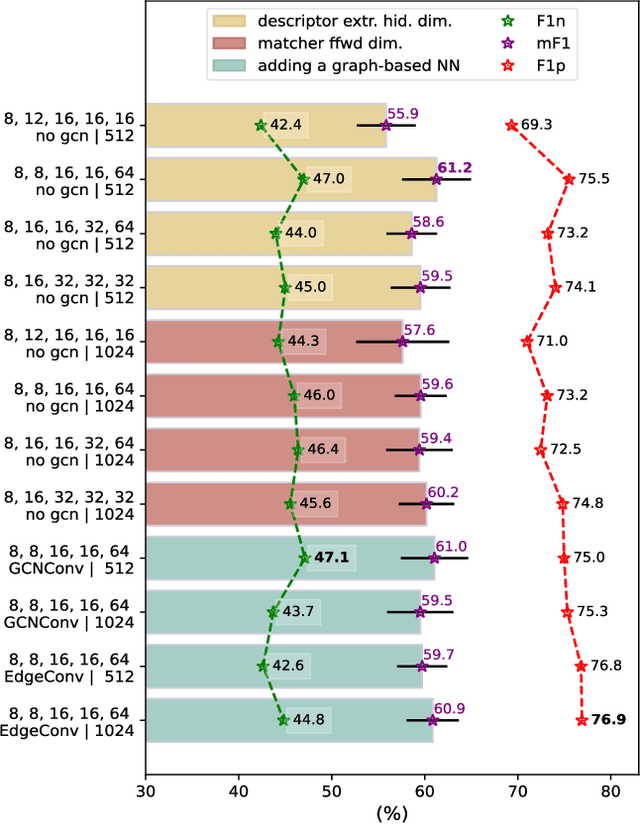
Robotic fruit monitoring is a key step toward automated agricultural production systems. Robots can significantly enhance plant and temporal fruit monitoring by providing precise, high-throughput assessments that overcome the limitations of traditional manual methods. Fruit monitoring is a challenging task due to the significant variation in size, shape, orientation, and occlusion of fruits. Also, fruits may be harvested or newly grown between recording sessions. Most methods are 2D image-based and they lack the 3D structure, depth, and spatial information, which represent key aspects of fruit monitoring. 3D colored point clouds, instead, can offer this information but they introduce challenges such as their sparsity and irregularity. In this paper, we present a novel approach for temporal fruit monitoring that addresses point clouds collected in a greenhouse over time. Our method segments fruits using a learning-based instance segmentation approach directly on the point cloud. Each segmented fruit is processed by a 3D sparse convolutional neural network to extract descriptors, which are used in an attention-based matching network to associate fruits with their instances from previous data collections. Experimental results on a real dataset of strawberries demonstrate that our approach outperforms other methods for fruits re-identification over time, allowing for precise temporal fruit monitoring in real and complex scenarios.
AdaCropFollow: Self-Supervised Online Adaptation for Visual Under-Canopy Navigation
Oct 16, 2024Under-canopy agricultural robots can enable various applications like precise monitoring, spraying, weeding, and plant manipulation tasks throughout the growing season. Autonomous navigation under the canopy is challenging due to the degradation in accuracy of RTK-GPS and the large variability in the visual appearance of the scene over time. In prior work, we developed a supervised learning-based perception system with semantic keypoint representation and deployed this in various field conditions. A large number of failures of this system can be attributed to the inability of the perception model to adapt to the domain shift encountered during deployment. In this paper, we propose a self-supervised online adaptation method for adapting the semantic keypoint representation using a visual foundational model, geometric prior, and pseudo labeling. Our preliminary experiments show that with minimal data and fine-tuning of parameters, the keypoint prediction model trained with labels on the source domain can be adapted in a self-supervised manner to various challenging target domains onboard the robot computer using our method. This can enable fully autonomous row-following capability in under-canopy robots across fields and crops without requiring human intervention.
Active Learning of Robot Vision Using Adaptive Path Planning
Oct 14, 2024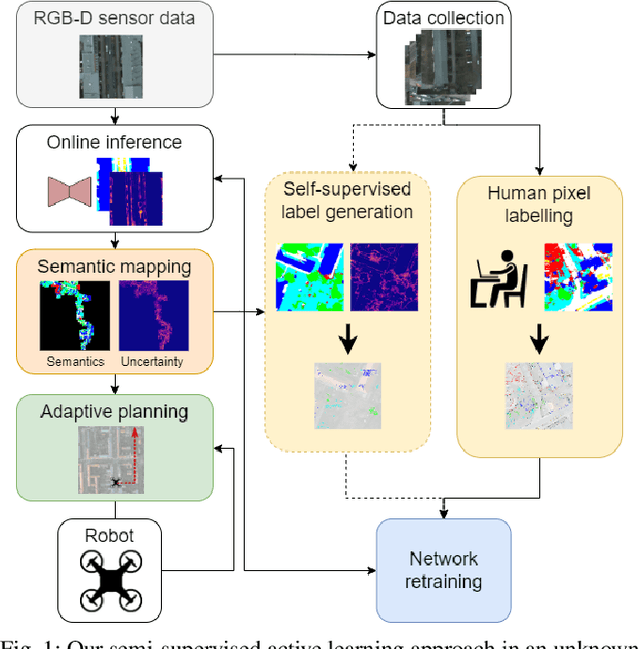
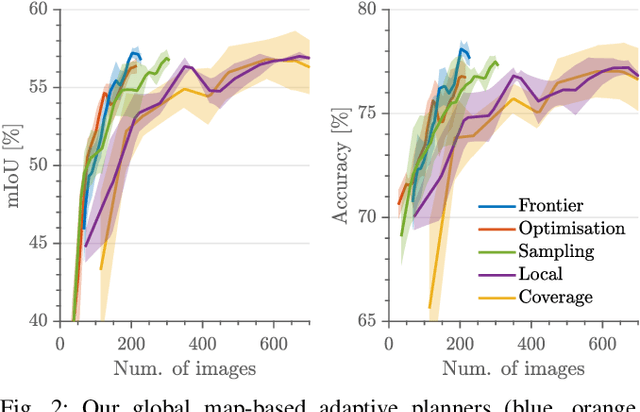
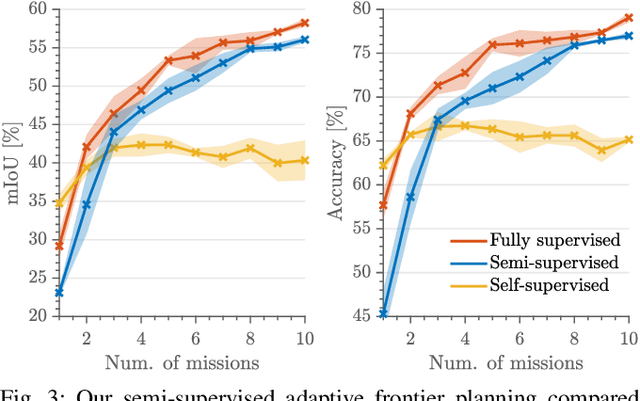
Robots need robust and flexible vision systems to perceive and reason about their environments beyond geometry. Most of such systems build upon deep learning approaches. As autonomous robots are commonly deployed in initially unknown environments, pre-training on static datasets cannot always capture the variety of domains and limits the robot's vision performance during missions. Recently, self-supervised as well as fully supervised active learning methods emerged to improve robotic vision. These approaches rely on large in-domain pre-training datasets or require substantial human labelling effort. To address these issues, we present a recent adaptive planning framework for efficient training data collection to substantially reduce human labelling requirements in semantic terrain monitoring missions. To this end, we combine high-quality human labels with automatically generated pseudo labels. Experimental results show that the framework reaches segmentation performance close to fully supervised approaches with drastically reduced human labelling effort while outperforming purely self-supervised approaches. We discuss the advantages and limitations of current methods and outline valuable future research avenues towards more robust and flexible robotic vision systems in unknown environments.
High-throughput 3D shape completion of potato tubers on a harvester
Jul 31, 2024
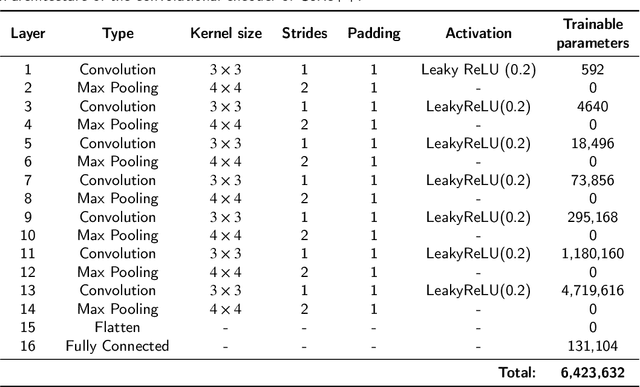


Potato yield is an important metric for farmers to further optimize their cultivation practices. Potato yield can be estimated on a harvester using an RGB-D camera that can estimate the three-dimensional (3D) volume of individual potato tubers. A challenge, however, is that the 3D shape derived from RGB-D images is only partially completed, underestimating the actual volume. To address this issue, we developed a 3D shape completion network, called CoRe++, which can complete the 3D shape from RGB-D images. CoRe++ is a deep learning network that consists of a convolutional encoder and a decoder. The encoder compresses RGB-D images into latent vectors that are used by the decoder to complete the 3D shape using the deep signed distance field network (DeepSDF). To evaluate our CoRe++ network, we collected partial and complete 3D point clouds of 339 potato tubers on an operational harvester in Japan. On the 1425 RGB-D images in the test set (representing 51 unique potato tubers), our network achieved a completion accuracy of 2.8 mm on average. For volumetric estimation, the root mean squared error (RMSE) was 22.6 ml, and this was better than the RMSE of the linear regression (31.1 ml) and the base model (36.9 ml). We found that the RMSE can be further reduced to 18.2 ml when performing the 3D shape completion in the center of the RGB-D image. With an average 3D shape completion time of 10 milliseconds per tuber, we can conclude that CoRe++ is both fast and accurate enough to be implemented on an operational harvester for high-throughput potato yield estimation. Our code, network weights and dataset are publicly available at https://github.com/UTokyo-FieldPhenomics-Lab/corepp.git.
A Dataset and Benchmark for Shape Completion of Fruits for Agricultural Robotics
Jul 18, 2024As the population is expected to reach 10 billion by 2050, our agricultural production system needs to double its productivity despite a decline of human workforce in the agricultural sector. Autonomous robotic systems are one promising pathway to increase productivity by taking over labor-intensive manual tasks like fruit picking. To be effective, such systems need to monitor and interact with plants and fruits precisely, which is challenging due to the cluttered nature of agricultural environments causing, for example, strong occlusions. Thus, being able to estimate the complete 3D shapes of objects in presence of occlusions is crucial for automating operations such as fruit harvesting. In this paper, we propose the first publicly available 3D shape completion dataset for agricultural vision systems. We provide an RGB-D dataset for estimating the 3D shape of fruits. Specifically, our dataset contains RGB-D frames of single sweet peppers in lab conditions but also in a commercial greenhouse. For each fruit, we additionally collected high-precision point clouds that we use as ground truth. For acquiring the ground truth shape, we developed a measuring process that allows us to record data of real sweet pepper plants, both in the lab and in the greenhouse with high precision, and determine the shape of the sensed fruits. We release our dataset, consisting of almost 7000 RGB-D frames belonging to more than 100 different fruits. We provide segmented RGB-D frames, with camera instrinsics to easily obtain colored point clouds, together with the corresponding high-precision, occlusion-free point clouds obtained with a high-precision laser scanner. We additionally enable evaluation ofshape completion approaches on a hidden test set through a public challenge on a benchmark server.
Open-World Semantic Segmentation Including Class Similarity
Mar 12, 2024Interpreting camera data is key for autonomously acting systems, such as autonomous vehicles. Vision systems that operate in real-world environments must be able to understand their surroundings and need the ability to deal with novel situations. This paper tackles open-world semantic segmentation, i.e., the variant of interpreting image data in which objects occur that have not been seen during training. We propose a novel approach that performs accurate closed-world semantic segmentation and, at the same time, can identify new categories without requiring any additional training data. Our approach additionally provides a similarity measure for every newly discovered class in an image to a known category, which can be useful information in downstream tasks such as planning or mapping. Through extensive experiments, we show that our model achieves state-of-the-art results on classes known from training data as well as for anomaly segmentation and can distinguish between different unknown classes.
Deep Reinforcement Learning with Dynamic Graphs for Adaptive Informative Path Planning
Feb 07, 2024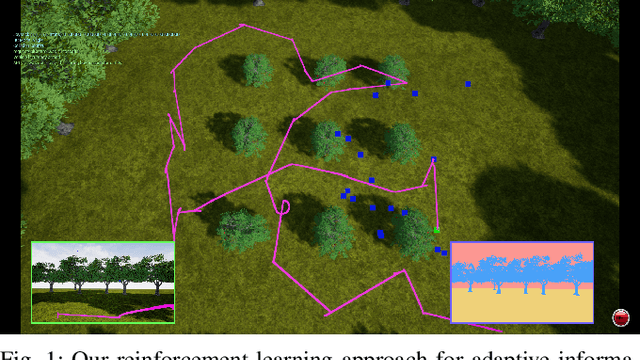



Autonomous robots are often employed for data collection due to their efficiency and low labour costs. A key task in robotic data acquisition is planning paths through an initially unknown environment to collect observations given platform-specific resource constraints, such as limited battery life. Adaptive online path planning in 3D environments is challenging due to the large set of valid actions and the presence of unknown occlusions. To address these issues, we propose a novel deep reinforcement learning approach for adaptively replanning robot paths to map targets of interest in unknown 3D environments. A key aspect of our approach is a dynamically constructed graph that restricts planning actions local to the robot, allowing us to quickly react to newly discovered obstacles and targets of interest. For replanning, we propose a new reward function that balances between exploring the unknown environment and exploiting online-collected data about the targets of interest. Our experiments show that our method enables more efficient target detection compared to state-of-the-art learning and non-learning baselines. We also show the applicability of our approach for orchard monitoring using an unmanned aerial vehicle in a photorealistic simulator.
Unsupervised Pre-Training for 3D Leaf Instance Segmentation
Jan 16, 2024Crops for food, feed, fiber, and fuel are key natural resources for our society. Monitoring plants and measuring their traits is an important task in agriculture often referred to as plant phenotyping. Traditionally, this task is done manually, which is time- and labor-intensive. Robots can automate phenotyping providing reproducible and high-frequency measurements. Today's perception systems use deep learning to interpret these measurements, but require a substantial amount of annotated data to work well. Obtaining such labels is challenging as it often requires background knowledge on the side of the labelers. This paper addresses the problem of reducing the labeling effort required to perform leaf instance segmentation on 3D point clouds, which is a first step toward phenotyping in 3D. Separating all leaves allows us to count them and compute relevant traits as their areas, lengths, and widths. We propose a novel self-supervised task-specific pre-training approach to initialize the backbone of a network for leaf instance segmentation. We also introduce a novel automatic postprocessing that considers the difficulty of correctly segmenting the points close to the stem, where all the leaves petiole overlap. The experiments presented in this paper suggest that our approach boosts the performance over all the investigated scenarios. We also evaluate the embeddings to assess the quality of the fully unsupervised approach and see a higher performance of our domain-specific postprocessing.
* 8 pages, 7 images, RA-L