 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointRAFT: 3D deep learning for high-throughput prediction of potato tuber weight from partial point clouds
Dec 30, 2025Potato yield is a key indicator for optimizing cultivation practices in agriculture. Potato yield can be estimated on harvesters using RGB-D cameras, which capture three-dimensional (3D) information of individual tubers moving along the conveyor belt. However, point clouds reconstructed from RGB-D images are incomplete due to self-occlusion, leading to systematic underestimation of tuber weight. To address this, we introduce PointRAFT, a high-throughput point cloud regression network that directly predicts continuous 3D shape properties, such as tuber weight, from partial point clouds. Rather than reconstructing full 3D geometry, PointRAFT infers target values directly from raw 3D data. Its key architectural novelty is an object height embedding that incorporates tuber height as an additional geometric cue, improving weight prediction under practical harvesting conditions. PointRAFT was trained and evaluated on 26,688 partial point clouds collected from 859 potato tubers across four cultivars and three growing seasons on an operational harvester in Japan. On a test set of 5,254 point clouds from 172 tubers, PointRAFT achieved a mean absolute error of 12.0 g and a root mean squared error of 17.2 g, substantially outperforming a linear regression baseline and a standard PointNet++ regression network. With an average inference time of 6.3 ms per point cloud, PointRAFT supports processing rates of up to 150 tubers per second, meeting the high-throughput requirements of commercial potato harvesters. Beyond potato weight estimation, PointRAFT provides a versatile regression network applicable to a wide range of 3D phenotyping and robotic perception tasks. The code, network weights, and a subset of the dataset are publicly available at https://github.com/pieterblok/pointraft.git.
High-throughput 3D shape completion of potato tubers on a harvester
Jul 31, 2024
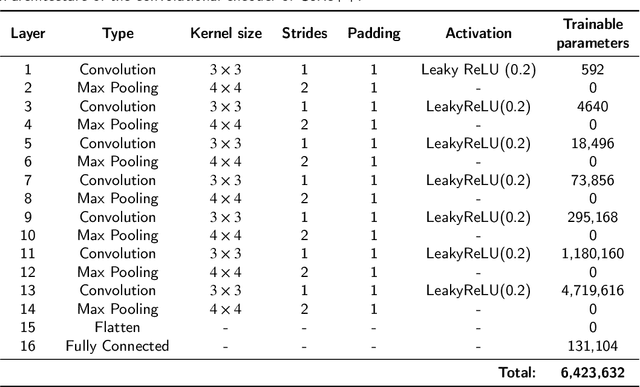


Potato yield is an important metric for farmers to further optimize their cultivation practices. Potato yield can be estimated on a harvester using an RGB-D camera that can estimate the three-dimensional (3D) volume of individual potato tubers. A challenge, however, is that the 3D shape derived from RGB-D images is only partially completed, underestimating the actual volume. To address this issue, we developed a 3D shape completion network, called CoRe++, which can complete the 3D shape from RGB-D images. CoRe++ is a deep learning network that consists of a convolutional encoder and a decoder. The encoder compresses RGB-D images into latent vectors that are used by the decoder to complete the 3D shape using the deep signed distance field network (DeepSDF). To evaluate our CoRe++ network, we collected partial and complete 3D point clouds of 339 potato tubers on an operational harvester in Japan. On the 1425 RGB-D images in the test set (representing 51 unique potato tubers), our network achieved a completion accuracy of 2.8 mm on average. For volumetric estimation, the root mean squared error (RMSE) was 22.6 ml, and this was better than the RMSE of the linear regression (31.1 ml) and the base model (36.9 ml). We found that the RMSE can be further reduced to 18.2 ml when performing the 3D shape completion in the center of the RGB-D image. With an average 3D shape completion time of 10 milliseconds per tuber, we can conclude that CoRe++ is both fast and accurate enough to be implemented on an operational harvester for high-throughput potato yield estimation. Our code, network weights and dataset are publicly available at https://github.com/UTokyo-FieldPhenomics-Lab/corepp.git.
DODA: Diffusion for Object-detection Domain Adaptation in Agriculture
Mar 27, 2024The diverse and high-quality content generated by recent generative models demonstrates the great potential of using synthetic data to train downstream models. However, in vision, especially in objection detection, related areas are not fully explored, the synthetic images are merely used to balance the long tails of existing datasets, and the accuracy of the generated labels is low, the full potential of generative models has not been exploited. In this paper, we propose DODA, a data synthesizer that can generate high-quality object detection data for new domains in agriculture. Specifically, we improve the controllability of layout-to-image through encoding layout as an image, thereby improving the quality of labels, and use a visual encoder to provide visual clues for the diffusion model to decouple visual features from the diffusion model, and empowering the model the ability to generate data in new domains. On the Global Wheat Head Detection (GWHD) Dataset, which is the largest dataset in agriculture and contains diverse domains, using the data synthesized by DODA improves the performance of the object detector by 12.74-17.76 AP$_{50}$ in the domain that was significantly shifted from the training data.
Global Wheat Head Dataset 2021: more diversity to improve the benchmarking of wheat head localization methods
Jun 03, 2021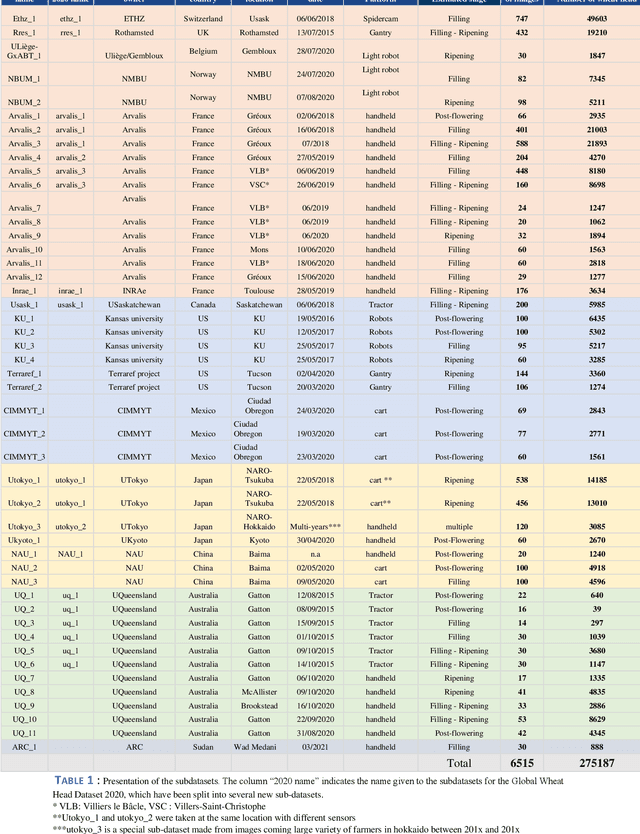
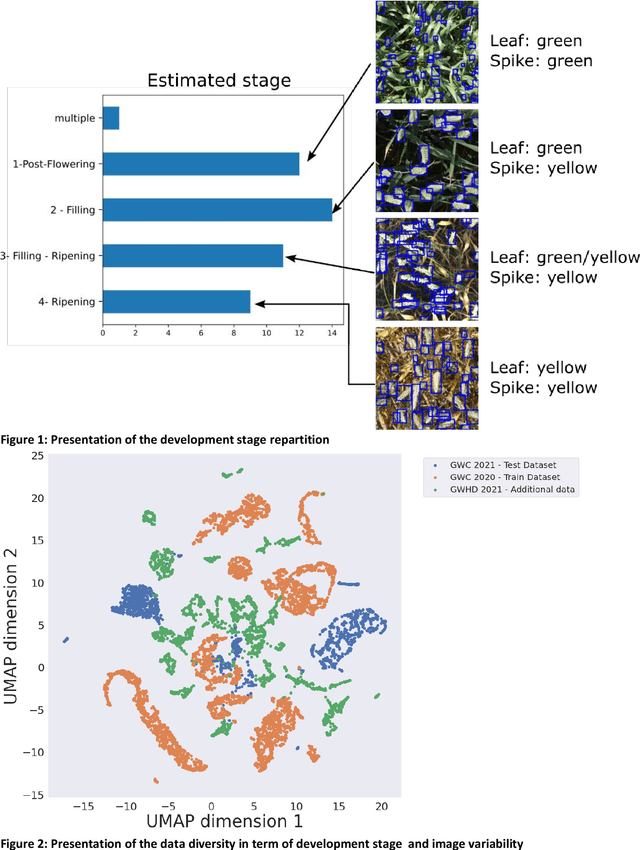
The Global Wheat Head Detection (GWHD) dataset was created in 2020 and has assembled 193,634 labelled wheat heads from 4,700 RGB images acquired from various acquisition platforms and 7 countries/institutions. With an associated competition hosted in Kaggle, GWHD has successfully attracted attention from both the computer vision and agricultural science communities. From this first experience in 2020, a few avenues for improvements have been identified, especially from the perspective of data size, head diversity and label reliability. To address these issues, the 2020 dataset has been reexamined, relabeled, and augmented by adding 1,722 images from 5 additional countries, allowing for 81,553 additional wheat heads to be added. We now release a new version of the Global Wheat Head Detection (GWHD) dataset in 2021, which is bigger, more diverse, and less noisy than the 2020 version. The GWHD 2021 is now publicly available at http://www.global-wheat.com/ and a new data challenge has been organized on AIcrowd to make use of this updated dataset.
Multi-Adversarial Learning for Cross-Lingual Word Embeddings
Oct 16, 2020
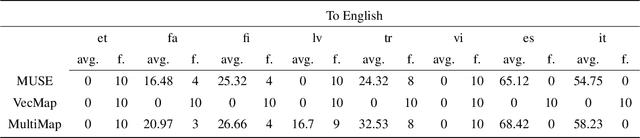

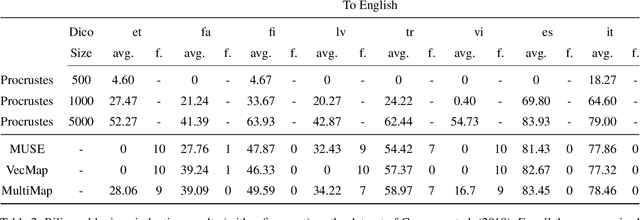
Generative adversarial networks (GANs) have succeeded in inducing cross-lingual word embeddings -- maps of matching words across languages -- without supervision. Despite these successes, GANs' performance for the difficult case of distant languages is still not satisfactory. These limitations have been explained by GANs' incorrect assumption that source and target embedding spaces are related by a single linear mapping and are approximately isomorphic. We assume instead that, especially across distant languages, the mapping is only piece-wise linear, and propose a multi-adversarial learning method. This novel method induces the seed cross-lingual dictionary through multiple mappings, each induced to fit the mapping for one subspace. Our experiments on unsupervised bilingual lexicon induction show that this method improves performance over previous single-mapping methods, especially for distant languages.
Weakly-Supervised Concept-based Adversarial Learning for Cross-lingual Word Embeddings
Apr 20, 2019
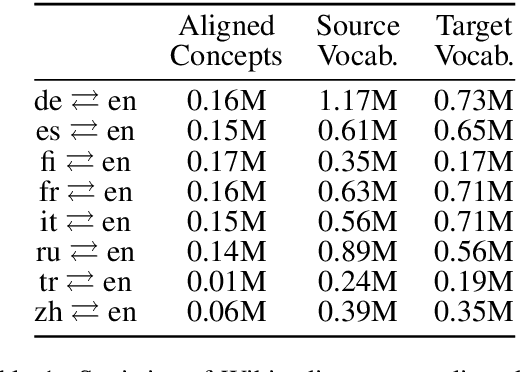
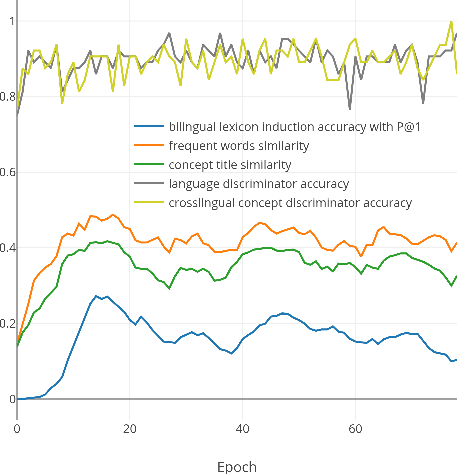
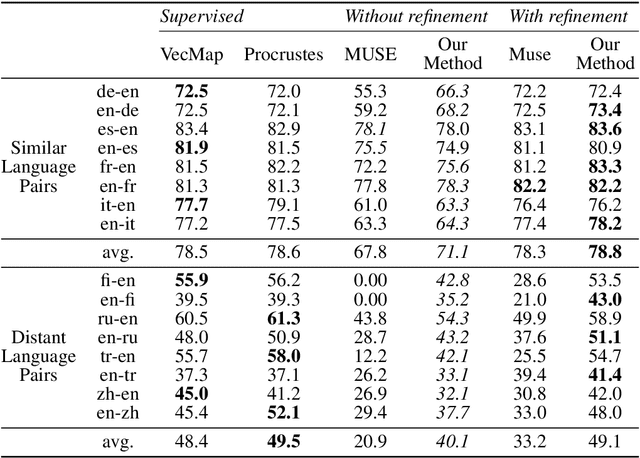
Distributed representations of words which map each word to a continuous vector have proven useful in capturing important linguistic information not only in a single language but also across different languages. Current unsupervised adversarial approaches show that it is possible to build a mapping matrix that align two sets of monolingual word embeddings together without high quality parallel data such as a dictionary or a sentence-aligned corpus. However, without post refinement, the performance of these methods' preliminary mapping is not good, leading to poor performance for typologically distant languages. In this paper, we propose a weakly-supervised adversarial training method to overcome this limitation, based on the intuition that mapping across languages is better done at the concept level than at the word level. We propose a concept-based adversarial training method which for most languages improves the performance of previous unsupervised adversarial methods, especially for typologically distant language pairs.