 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointRAFT: 3D deep learning for high-throughput prediction of potato tuber weight from partial point clouds
Dec 30, 2025Potato yield is a key indicator for optimizing cultivation practices in agriculture. Potato yield can be estimated on harvesters using RGB-D cameras, which capture three-dimensional (3D) information of individual tubers moving along the conveyor belt. However, point clouds reconstructed from RGB-D images are incomplete due to self-occlusion, leading to systematic underestimation of tuber weight. To address this, we introduce PointRAFT, a high-throughput point cloud regression network that directly predicts continuous 3D shape properties, such as tuber weight, from partial point clouds. Rather than reconstructing full 3D geometry, PointRAFT infers target values directly from raw 3D data. Its key architectural novelty is an object height embedding that incorporates tuber height as an additional geometric cue, improving weight prediction under practical harvesting conditions. PointRAFT was trained and evaluated on 26,688 partial point clouds collected from 859 potato tubers across four cultivars and three growing seasons on an operational harvester in Japan. On a test set of 5,254 point clouds from 172 tubers, PointRAFT achieved a mean absolute error of 12.0 g and a root mean squared error of 17.2 g, substantially outperforming a linear regression baseline and a standard PointNet++ regression network. With an average inference time of 6.3 ms per point cloud, PointRAFT supports processing rates of up to 150 tubers per second, meeting the high-throughput requirements of commercial potato harvesters. Beyond potato weight estimation, PointRAFT provides a versatile regression network applicable to a wide range of 3D phenotyping and robotic perception tasks. The code, network weights, and a subset of the dataset are publicly available at https://github.com/pieterblok/pointraft.git.
Improved detection of discarded fish species through BoxAL active learning
Oct 07, 2024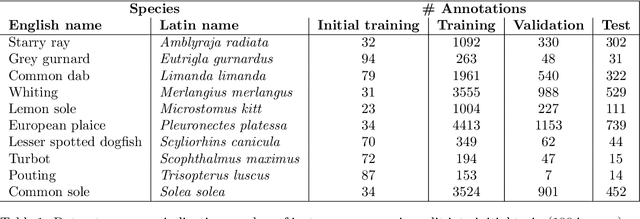

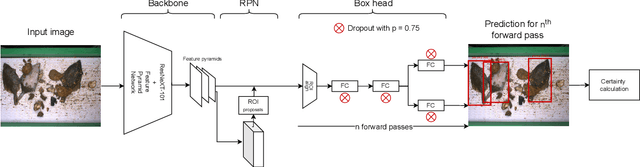
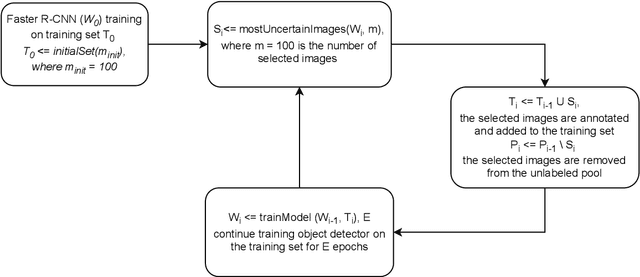
In recent years, powerful data-driven deep-learning techniques have been developed and applied for automated catch registration. However, these methods are dependent on the labelled data, which is time-consuming, labour-intensive, expensive to collect and need expert knowledge. In this study, we present an active learning technique, named BoxAL, which includes estimation of epistemic certainty of the Faster R-CNN object-detection model. The method allows selecting the most uncertain training images from an unlabeled pool, which are then used to train the object-detection model. To evaluate the method, we used an open-source image dataset obtained with a dedicated image-acquisition system developed for commercial trawlers targeting demersal species. We demonstrated, that our approach allows reaching the same object-detection performance as with the random sampling using 400 fewer labelled images. Besides, mean AP score was significantly higher at the last training iteration with 1100 training images, specifically, 39.0±1.6 and 34.8±1.8 for certainty-based sampling and random sampling, respectively. Additionally, we showed that epistemic certainty is a suitable method to sample images that the current iteration of the model cannot deal with yet. Our study additionally showed that the sampled new data is more valuable for training than the remaining unlabeled data. Our software is available on https://github.com/pieterblok/boxal.
High-throughput 3D shape completion of potato tubers on a harvester
Jul 31, 2024
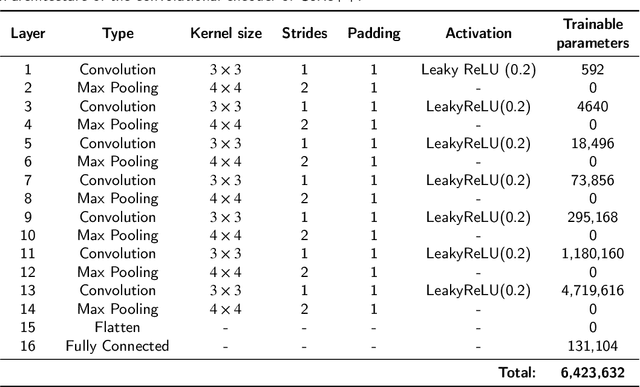


Potato yield is an important metric for farmers to further optimize their cultivation practices. Potato yield can be estimated on a harvester using an RGB-D camera that can estimate the three-dimensional (3D) volume of individual potato tubers. A challenge, however, is that the 3D shape derived from RGB-D images is only partially completed, underestimating the actual volume. To address this issue, we developed a 3D shape completion network, called CoRe++, which can complete the 3D shape from RGB-D images. CoRe++ is a deep learning network that consists of a convolutional encoder and a decoder. The encoder compresses RGB-D images into latent vectors that are used by the decoder to complete the 3D shape using the deep signed distance field network (DeepSDF). To evaluate our CoRe++ network, we collected partial and complete 3D point clouds of 339 potato tubers on an operational harvester in Japan. On the 1425 RGB-D images in the test set (representing 51 unique potato tubers), our network achieved a completion accuracy of 2.8 mm on average. For volumetric estimation, the root mean squared error (RMSE) was 22.6 ml, and this was better than the RMSE of the linear regression (31.1 ml) and the base model (36.9 ml). We found that the RMSE can be further reduced to 18.2 ml when performing the 3D shape completion in the center of the RGB-D image. With an average 3D shape completion time of 10 milliseconds per tuber, we can conclude that CoRe++ is both fast and accurate enough to be implemented on an operational harvester for high-throughput potato yield estimation. Our code, network weights and dataset are publicly available at https://github.com/UTokyo-FieldPhenomics-Lab/corepp.git.
Active learning for efficient annotation in precision agriculture: a use-case on crop-weed semantic segmentation
Apr 03, 2024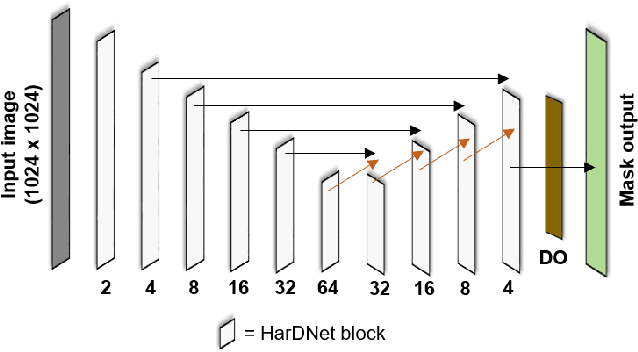



Optimizing deep learning models requires large amounts of annotated images, a process that is both time-intensive and costly. Especially for semantic segmentation models in which every pixel must be annotated. A potential strategy to mitigate annotation effort is active learning. Active learning facilitates the identification and selection of the most informative images from a large unlabelled pool. The underlying premise is that these selected images can improve the model's performance faster than random selection to reduce annotation effort. While active learning has demonstrated promising results on benchmark datasets like Cityscapes, its performance in the agricultural domain remains largely unexplored. This study addresses this research gap by conducting a comparative study of three active learning-based acquisition functions: Bayesian Active Learning by Disagreement (BALD), stochastic-based BALD (PowerBALD), and Random. The acquisition functions were tested on two agricultural datasets: Sugarbeet and Corn-Weed, both containing three semantic classes: background, crop and weed. Our results indicated that active learning, especially PowerBALD, yields a higher performance than Random sampling on both datasets. But due to the relatively large standard deviations, the differences observed were minimal; this was partly caused by high image redundancy and imbalanced classes. Specifically, more than 89\% of the pixels belonged to the background class on both datasets. The absence of significant results on both datasets indicates that further research is required for applying active learning on agricultural datasets, especially if they contain a high-class imbalance and redundant images. Recommendations and insights are provided in this paper to potentially resolve such issues.
DODA: Diffusion for Object-detection Domain Adaptation in Agriculture
Mar 27, 2024The diverse and high-quality content generated by recent generative models demonstrates the great potential of using synthetic data to train downstream models. However, in vision, especially in objection detection, related areas are not fully explored, the synthetic images are merely used to balance the long tails of existing datasets, and the accuracy of the generated labels is low, the full potential of generative models has not been exploited. In this paper, we propose DODA, a data synthesizer that can generate high-quality object detection data for new domains in agriculture. Specifically, we improve the controllability of layout-to-image through encoding layout as an image, thereby improving the quality of labels, and use a visual encoder to provide visual clues for the diffusion model to decouple visual features from the diffusion model, and empowering the model the ability to generate data in new domains. On the Global Wheat Head Detection (GWHD) Dataset, which is the largest dataset in agriculture and contains diverse domains, using the data synthesized by DODA improves the performance of the object detector by 12.74-17.76 AP$_{50}$ in the domain that was significantly shifted from the training data.
Apple scab detection in orchards using deep learning on colour and multispectral images
Feb 17, 2023


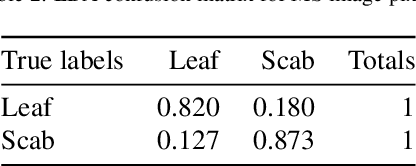
Apple scab is a fungal disease caused by Venturia inaequalis. Disease is of particular concern for growers, as it causes significant damage to fruit and leaves, leading to loss of fruit and yield. This article examines the ability of deep learning and hyperspectral imaging to accurately identify an apple symptom infection in apple trees. In total, 168 image scenes were collected using conventional RGB and Visible to Near-infrared (VIS-NIR) spectral imaging (8 channels) in infected orchards. Spectral data were preprocessed with an Artificial Neural Network (ANN) trained in segmentation to detect scab pixels based on spectral information. Linear Discriminant Analysis (LDA) was used to find the most discriminating channels in spectral data based on the healthy leaf and scab infested leaf spectra. Five combinations of false-colour images were created from the spectral data and the segmentation net results. The images were trained and evaluated with a modified version of the YOLOv5 network. Despite the promising results of deep learning using RGB images (P=0.8, mAP@50=0.73), the detection of apple scab in apple trees using multispectral imaging proved to be a difficult task. The high-light environment of the open field made it difficult to collect a balanced spectrum from the multispectral camera, since the infrared channel and the visible channels needed to be constantly balanced so that they did not overexpose in the images.
Active learning with MaskAL reduces annotation effort for training Mask R-CNN
Dec 13, 2021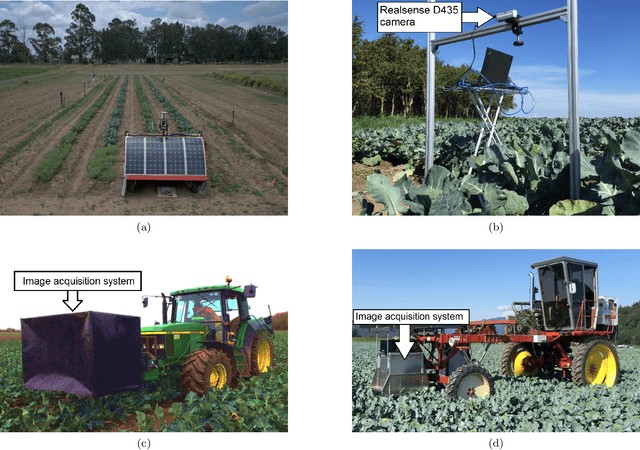

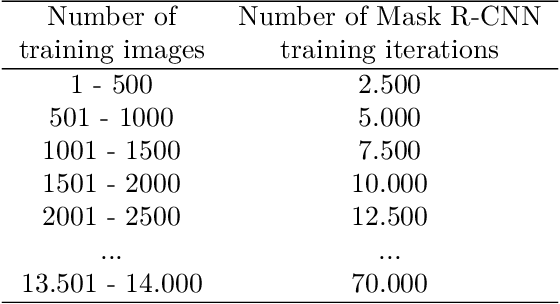
The generalisation performance of a convolutional neural network (CNN) is influenced by the quantity, quality, and variety of the training images. Training images must be annotated, and this is time consuming and expensive. The goal of our work was to reduce the number of annotated images needed to train a CNN while maintaining its performance. We hypothesised that the performance of a CNN can be improved faster by ensuring that the set of training images contains a large fraction of hard-to-classify images. The objective of our study was to test this hypothesis with an active learning method that can automatically select the hard-to-classify images. We developed an active learning method for Mask Region-based CNN (Mask R-CNN) and named this method MaskAL. MaskAL involved the iterative training of Mask R-CNN, after which the trained model was used to select a set of unlabelled images about which the model was uncertain. The selected images were then annotated and used to retrain Mask R-CNN, and this was repeated for a number of sampling iterations. In our study, Mask R-CNN was trained on 2500 broccoli images that were selected through 12 sampling iterations by either MaskAL or a random sampling method from a training set of 14,000 broccoli images. For all sampling iterations, MaskAL performed significantly better than the random sampling. Furthermore, MaskAL had the same performance after sampling 900 images as the random sampling had after 2300 images. Compared to a Mask R-CNN model that was trained on the entire training set (14,000 images), MaskAL achieved 93.9% of its performance with 17.9% of its training data. The random sampling achieved 81.9% of its performance with 16.4% of its training data. We conclude that by using MaskAL, the annotation effort can be reduced for training Mask R-CNN on a broccoli dataset. Our software is available on https://github.com/pieterblok/maskal.