 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing annotations for 5D apple pose estimation through 3D Gaussian Splatting (3DGS)
Dec 23, 2025Automating tasks in orchards is challenging because of the large amount of variation in the environment and occlusions. One of the challenges is apple pose estimation, where key points, such as the calyx, are often occluded. Recently developed pose estimation methods no longer rely on these key points, but still require them for annotations, making annotating challenging and time-consuming. Due to the abovementioned occlusions, there can be conflicting and missing annotations of the same fruit between different images. Novel 3D reconstruction methods can be used to simplify annotating and enlarge datasets. We propose a novel pipeline consisting of 3D Gaussian Splatting to reconstruct an orchard scene, simplified annotations, automated projection of the annotations to images, and the training and evaluation of a pose estimation method. Using our pipeline, 105 manual annotations were required to obtain 28,191 training labels, a reduction of 99.6%. Experimental results indicated that training with labels of fruits that are $\leq95\%$ occluded resulted in the best performance, with a neutral F1 score of 0.927 on the original images and 0.970 on the rendered images. Adjusting the size of the training dataset had small effects on the model performance in terms of F1 score and pose estimation accuracy. It was found that the least occluded fruits had the best position estimation, which worsened as the fruits became more occluded. It was also found that the tested pose estimation method was unable to correctly learn the orientation estimation of apples.
AgriGS-SLAM: Orchard Mapping Across Seasons via Multi-View Gaussian Splatting SLAM
Oct 30, 2025Autonomous robots in orchards require real-time 3D scene understanding despite repetitive row geometry, seasonal appearance changes, and wind-driven foliage motion. We present AgriGS-SLAM, a Visual--LiDAR SLAM framework that couples direct LiDAR odometry and loop closures with multi-camera 3D Gaussian Splatting (3DGS) rendering. Batch rasterization across complementary viewpoints recovers orchard structure under occlusions, while a unified gradient-driven map lifecycle executed between keyframes preserves fine details and bounds memory. Pose refinement is guided by a probabilistic LiDAR-based depth consistency term, back-propagated through the camera projection to tighten geometry-appearance coupling. We deploy the system on a field platform in apple and pear orchards across dormancy, flowering, and harvesting, using a standardized trajectory protocol that evaluates both training-view and novel-view synthesis to reduce 3DGS overfitting in evaluation. Across seasons and sites, AgriGS-SLAM delivers sharper, more stable reconstructions and steadier trajectories than recent state-of-the-art 3DGS-SLAM baselines while maintaining real-time performance on-tractor. While demonstrated in orchard monitoring, the approach can be applied to other outdoor domains requiring robust multimodal perception.
Tree-SLAM: semantic object SLAM for efficient mapping of individual trees in orchards
Jul 16, 2025Accurate mapping of individual trees is an important component for precision agriculture in orchards, as it allows autonomous robots to perform tasks like targeted operations or individual tree monitoring. However, creating these maps is challenging because GPS signals are often unreliable under dense tree canopies. Furthermore, standard Simultaneous Localization and Mapping (SLAM) approaches struggle in orchards because the repetitive appearance of trees can confuse the system, leading to mapping errors. To address this, we introduce Tree-SLAM, a semantic SLAM approach tailored for creating maps of individual trees in orchards. Utilizing RGB-D images, our method detects tree trunks with an instance segmentation model, estimates their location and re-identifies them using a cascade-graph-based data association algorithm. These re-identified trunks serve as landmarks in a factor graph framework that integrates noisy GPS signals, odometry, and trunk observations. The system produces maps of individual trees with a geo-localization error as low as 18 cm, which is less than 20\% of the planting distance. The proposed method was validated on diverse datasets from apple and pear orchards across different seasons, demonstrating high mapping accuracy and robustness in scenarios with unreliable GPS signals.
A drone that learns to efficiently find objects in agricultural fields: from simulation to the real world
May 14, 2025Drones are promising for data collection in precision agriculture, however, they are limited by their battery capacity. Efficient path planners are therefore required. This paper presents a drone path planner trained using Reinforcement Learning (RL) on an abstract simulation that uses object detections and uncertain prior knowledge. The RL agent controls the flight direction and can terminate the flight. By using the agent in combination with the drone's flight controller and a detection network to process camera images, it is possible to evaluate the performance of the agent on real-world data. In simulation, the agent yielded on average a 78% shorter flight path compared to a full coverage planner, at the cost of a 14% lower recall. On real-world data, the agent showed a 72% shorter flight path compared to a full coverage planner, however, at the cost of a 25% lower recall. The lower performance on real-world data was attributed to the real-world object distribution and the lower accuracy of prior knowledge, and shows potential for improvement. Overall, we concluded that for applications where it is not crucial to find all objects, such as weed detection, the learned-based path planner is suitable and efficient.
Adaptive path planning for efficient object search by UAVs in agricultural fields
Apr 03, 2025



This paper presents an adaptive path planner for object search in agricultural fields using UAVs. The path planner uses a high-altitude coverage flight path and plans additional low-altitude inspections when the detection network is uncertain. The path planner was evaluated in an offline simulation environment containing real-world images. We trained a YOLOv8 detection network to detect artificial plants placed in grass fields to showcase the potential of our path planner. We evaluated the effect of different detection certainty measures, optimized the path planning parameters, investigated the effects of localization errors and different numbers of objects in the field. The YOLOv8 detection confidence worked best to differentiate between true and false positive detections and was therefore used in the adaptive planner. The optimal parameters of the path planner depended on the distribution of objects in the field, when the objects were uniformly distributed, more low-altitude inspections were needed compared to a non-uniform distribution of objects, resulting in a longer path length. The adaptive planner proved to be robust against localization uncertainty. When increasing the number of objects, the flight path length increased, especially when the objects were uniformly distributed. When the objects were non-uniformly distributed, the adaptive path planner yielded a shorter path than a low-altitude coverage path, even with high number of objects. Overall, the presented adaptive path planner allowed to find non-uniformly distributed objects in a field faster than a coverage path planner and resulted in a compatible detection accuracy. The path planner is made available at https://github.com/wur-abe/uav_adaptive_planner.
Learning UAV-based path planning for efficient localization of objects using prior knowledge
Dec 16, 2024



UAV's are becoming popular for various object search applications in agriculture, however they usually use time-consuming row-by-row flight paths. This paper presents a deep-reinforcement-learning method for path planning to efficiently localize objects of interest using UAVs with a minimal flight-path length. The method uses some global prior knowledge with uncertain object locations and limited resolution in combination with a local object map created using the output of an object detection network. The search policy could be learned using deep Q-learning. We trained the agent in simulation, allowing thorough evaluation of the object distribution, typical errors in the perception system and prior knowledge, and different stopping criteria. When objects were non-uniformly distributed over the field, the agent found the objects quicker than a row-by-row flight path, showing that it learns to exploit the distribution of objects. Detection errors and quality of prior knowledge had only minor effect on the performance, indicating that the learned search policy was robust to errors in the perception system and did not need detailed prior knowledge. Without prior knowledge, the learned policy was still comparable in performance to a row-by-row flight path. Finally, we demonstrated that it is possible to learn the appropriate moment to end the search task. The applicability of the approach for object search on a real drone was comprehensively discussed and evaluated. Overall, we conclude that the learned search policy increased the efficiency of finding objects using a UAV, and can be applied in real-world conditions when the specified assumptions are met.
Improved detection of discarded fish species through BoxAL active learning
Oct 07, 2024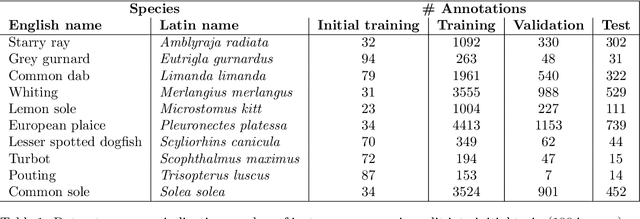

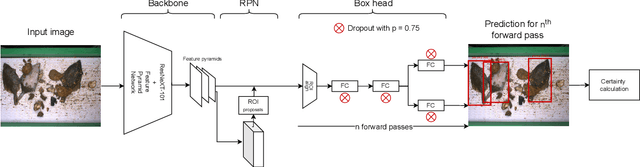
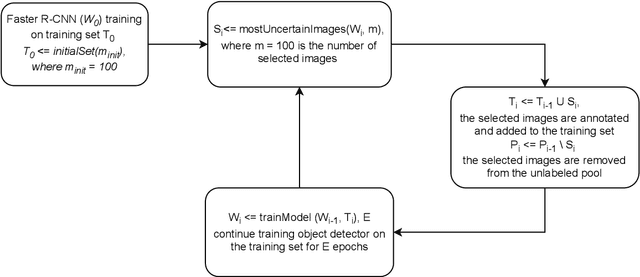
In recent years, powerful data-driven deep-learning techniques have been developed and applied for automated catch registration. However, these methods are dependent on the labelled data, which is time-consuming, labour-intensive, expensive to collect and need expert knowledge. In this study, we present an active learning technique, named BoxAL, which includes estimation of epistemic certainty of the Faster R-CNN object-detection model. The method allows selecting the most uncertain training images from an unlabeled pool, which are then used to train the object-detection model. To evaluate the method, we used an open-source image dataset obtained with a dedicated image-acquisition system developed for commercial trawlers targeting demersal species. We demonstrated, that our approach allows reaching the same object-detection performance as with the random sampling using 400 fewer labelled images. Besides, mean AP score was significantly higher at the last training iteration with 1100 training images, specifically, 39.0±1.6 and 34.8±1.8 for certainty-based sampling and random sampling, respectively. Additionally, we showed that epistemic certainty is a suitable method to sample images that the current iteration of the model cannot deal with yet. Our study additionally showed that the sampled new data is more valuable for training than the remaining unlabeled data. Our software is available on https://github.com/pieterblok/boxal.
DualLQR: Efficient Grasping of Oscillating Apples using Task Parameterized Learning from Demonstration
Sep 25, 2024Learning from Demonstration offers great potential for robots to learn to perform agricultural tasks, specifically selective harvesting. One of the challenges is that the target fruit can be oscillating while approaching. Grasping oscillating targets has two requirements: 1) close tracking of the target during the final approach for damage-free grasping, and 2) the complete path should be as short as possible for improved efficiency. We propose a new method called DualLQR. In this method, we use a finite horizon Linear Quadratic Regulator (LQR) on a moving target, without the need of refitting the LQR. To make this possible, we use a dual LQR setup, with an LQR running in two seperate reference frames. Through extensive simulation testing, it was found that the state-of-art method barely meets the required final accuracy without oscillations and drops below the required accuracy with an oscillating target. DualLQR was found to be able to meet the required final accuracy even with high oscillations, with an accuracy increase of 60% for high orientation oscillations. Further testing on a real-world apple grasping task showed that DualLQR was able to successfully grasp oscillating apples, with a success rate of 99%.
A comparison between single-stage and two-stage 3D tracking algorithms for greenhouse robotics
Apr 19, 2024



With the current demand for automation in the agro-food industry, accurately detecting and localizing relevant objects in 3D is essential for successful robotic operations. However, this is a challenge due the presence of occlusions. Multi-view perception approaches allow robots to overcome occlusions, but a tracking component is needed to associate the objects detected by the robot over multiple viewpoints. Multi-object tracking (MOT) algorithms can be categorized between two-stage and single-stage methods. Two-stage methods tend to be simpler to adapt and implement to custom applications, while single-stage methods present a more complex end-to-end tracking method that can yield better results in occluded situations at the cost of more training data. The potential advantages of single-stage methods over two-stage methods depends on the complexity of the sequence of viewpoints that a robot needs to process. In this work, we compare a 3D two-stage MOT algorithm, 3D-SORT, against a 3D single-stage MOT algorithm, MOT-DETR, in three different types of sequences with varying levels of complexity. The sequences represent simpler and more complex motions that a robot arm can perform in a tomato greenhouse. Our experiments in a tomato greenhouse show that the single-stage algorithm consistently yields better tracking accuracy, especially in the more challenging sequences where objects are fully occluded or non-visible during several viewpoints.
Video-based Automatic Lameness Detection of Dairy Cows using Pose Estimation and Multiple Locomotion Traits
Jan 10, 2024This study presents an automated lameness detection system that uses deep-learning image processing techniques to extract multiple locomotion traits associated with lameness. Using the T-LEAP pose estimation model, the motion of nine keypoints was extracted from videos of walking cows. The videos were recorded outdoors, with varying illumination conditions, and T-LEAP extracted 99.6% of correct keypoints. The trajectories of the keypoints were then used to compute six locomotion traits: back posture measurement, head bobbing, tracking distance, stride length, stance duration, and swing duration. The three most important traits were back posture measurement, head bobbing, and tracking distance. For the ground truth, we showed that a thoughtful merging of the scores of the observers could improve intra-observer reliability and agreement. We showed that including multiple locomotion traits improves the classification accuracy from 76.6% with only one trait to 79.9% with the three most important traits and to 80.1% with all six locomotion traits.