 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparison between single-stage and two-stage 3D tracking algorithms for greenhouse robotics
Apr 19, 2024



With the current demand for automation in the agro-food industry, accurately detecting and localizing relevant objects in 3D is essential for successful robotic operations. However, this is a challenge due the presence of occlusions. Multi-view perception approaches allow robots to overcome occlusions, but a tracking component is needed to associate the objects detected by the robot over multiple viewpoints. Multi-object tracking (MOT) algorithms can be categorized between two-stage and single-stage methods. Two-stage methods tend to be simpler to adapt and implement to custom applications, while single-stage methods present a more complex end-to-end tracking method that can yield better results in occluded situations at the cost of more training data. The potential advantages of single-stage methods over two-stage methods depends on the complexity of the sequence of viewpoints that a robot needs to process. In this work, we compare a 3D two-stage MOT algorithm, 3D-SORT, against a 3D single-stage MOT algorithm, MOT-DETR, in three different types of sequences with varying levels of complexity. The sequences represent simpler and more complex motions that a robot arm can perform in a tomato greenhouse. Our experiments in a tomato greenhouse show that the single-stage algorithm consistently yields better tracking accuracy, especially in the more challenging sequences where objects are fully occluded or non-visible during several viewpoints.
Gradient-based Local Next-best-view Planning for Improved Perception of Targeted Plant Nodes
Nov 28, 2023Robots are increasingly used in tomato greenhouses to automate labour-intensive tasks such as selective harvesting and de-leafing. To perform these tasks, robots must be able to accurately and efficiently perceive the plant nodes that need to be cut, despite the high levels of occlusion from other plant parts. We formulate this problem as a local next-best-view (NBV) planning task where the robot has to plan an efficient set of camera viewpoints to overcome occlusion and improve the quality of perception. Our formulation focuses on quickly improving the perception accuracy of a single target node to maximise its chances of being cut. Previous methods of NBV planning mostly focused on global view planning and used random sampling of candidate viewpoints for exploration, which could suffer from high computational costs, ineffective view selection due to poor candidates, or non-smooth trajectories due to inefficient sampling. We propose a gradient-based NBV planner using differential ray sampling, which directly estimates the local gradient direction for viewpoint planning to overcome occlusion and improve perception. Through simulation experiments, we showed that our planner can handle occlusions and improve the 3D reconstruction and position estimation of nodes equally well as a sampling-based NBV planner, while taking ten times less computation and generating 28% more efficient trajectories.
3D Pose Estimation of Tomato Peduncle Nodes using Deep Keypoint Detection and Point Cloud
Nov 08, 2023Greenhouse production of fruits and vegetables in developed countries is challenged by labor 12 scarcity and high labor costs. Robots offer a good solution for sustainable and cost-effective 13 production. Acquiring accurate spatial information about relevant plant parts is vital for 14 successful robot operation. Robot perception in greenhouses is challenging due to variations in 15 plant appearance, viewpoints, and illumination. This paper proposes a keypoint-detection-based 16 method using data from an RGB-D camera to estimate the 3D pose of peduncle nodes, which 17 provides essential information to harvest the tomato bunches. 18 19 Specifically, this paper proposes a method that detects four anatomical landmarks in the color 20 image and then integrates 3D point-cloud information to determine the 3D pose. A 21 comprehensive evaluation was conducted in a commercial greenhouse to gain insight into the 22 performance of different parts of the method. The results showed: (1) high accuracy in object 23 detection, achieving an Average Precision (AP) of AP@0.5=0.96; (2) an average Percentage of 24 Detected Joints (PDJ) of the keypoints of PhDJ@0.2=94.31%; and (3) 3D pose estimation 25 accuracy with mean absolute errors (MAE) of 11.38o and 9.93o for the relative upper and lower 26 angles between the peduncle and main stem, respectively. Furthermore, the capability to handle 27 variations in viewpoint was investigated, demonstrating the method was robust to view changes. 28 However, canonical and higher views resulted in slightly higher performance compared to other 29 views. Although tomato was selected as a use case, the proposed method is also applicable to 30 other greenhouse crops like pepper.
Efficient Search and Detection of Relevant Plant Parts using Semantics-Aware Active Vision
Jun 16, 2023



To automate harvesting and de-leafing of tomato plants using robots, it is important to search and detect the relevant plant parts, namely tomatoes, peduncles, and petioles. This is challenging due to high levels of occlusion in tomato greenhouses. Active vision is a promising approach which helps robots to deliberately plan camera viewpoints to overcome occlusion and improve perception accuracy. However, current active-vision algorithms cannot differentiate between relevant and irrelevant plant parts, making them inefficient for targeted perception of specific plant parts. We propose a semantic active-vision strategy that uses semantic information to identify the relevant plant parts and prioritises them during view planning using an attention mechanism. We evaluated our strategy using 3D models of tomato plants with varying structural complexity, which closely represented occlusions in the real world. We used a simulated environment to gain insights into our strategy, while ensuring repeatability and statistical significance. At the end of ten viewpoints, our strategy was able to correctly detect 85.5% of the plant parts, about 4 parts more on average per plant compared to a volumetric active-vision strategy. Also, it detected 5 and 9 parts more compared to two predefined strategies and 11 parts more compared to a random strategy. It also performed reliably with a median of 88.9% correctly-detected objects per plant in 96 experiments. Our strategy was also robust to uncertainty in plant and plant-part position, plant complexity, and different viewpoint sampling strategies. We believe that our work could significantly improve the speed and robustness of automated harvesting and de-leafing in tomato crop production.
Attention-driven Active Vision for Efficient Reconstruction of Plants and Targeted Plant Parts
Jun 21, 2022


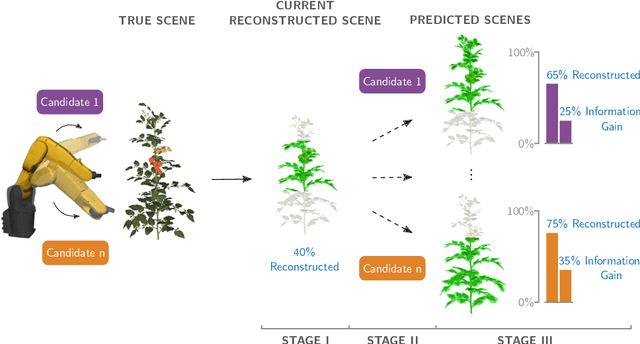
Visual reconstruction of tomato plants by a robot is extremely challenging due to the high levels of variation and occlusion in greenhouse environments. The paradigm of active-vision helps overcome these challenges by reasoning about previously acquired information and systematically planning camera viewpoints to gather novel information about the plant. However, existing active-vision algorithms cannot perform well on targeted perception objectives, such as the 3D reconstruction of leaf nodes, because they do not distinguish between the plant-parts that need to be reconstructed and the rest of the plant. In this paper, we propose an attention-driven active-vision algorithm that considers only the relevant plant-parts according to the task-at-hand. The proposed approach was evaluated in a simulated environment on the task of 3D reconstruction of tomato plants at varying levels of attention, namely the whole plant, the main stem and the leaf nodes. Compared to pre-defined and random approaches, our approach improves the accuracy of 3D reconstruction by 9.7% and 5.3% for the whole plant, 14.2% and 7.9% for the main stem, and 25.9% and 17.3% for the leaf nodes respectively within the first 3 viewpoints. Also, compared to pre-defined and random approaches, our approach reconstructs 80% of the whole plant and the main stem in 1 less viewpoint and 80% of the leaf nodes in 3 less viewpoints. We also demonstrated that the attention-driven NBV planner works effectively despite changes to the plant models, the amount of occlusion, the number of candidate viewpoints and the resolutions of reconstruction. By adding an attention mechanism to active-vision, it is possible to efficiently reconstruct the whole plant and targeted plant parts. We conclude that an attention mechanism for active-vision is necessary to significantly improve the quality of perception in complex agro-food environments.