 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-based Automatic Lameness Detection of Dairy Cows using Pose Estimation and Multiple Locomotion Traits
Jan 10, 2024This study presents an automated lameness detection system that uses deep-learning image processing techniques to extract multiple locomotion traits associated with lameness. Using the T-LEAP pose estimation model, the motion of nine keypoints was extracted from videos of walking cows. The videos were recorded outdoors, with varying illumination conditions, and T-LEAP extracted 99.6% of correct keypoints. The trajectories of the keypoints were then used to compute six locomotion traits: back posture measurement, head bobbing, tracking distance, stride length, stance duration, and swing duration. The three most important traits were back posture measurement, head bobbing, and tracking distance. For the ground truth, we showed that a thoughtful merging of the scores of the observers could improve intra-observer reliability and agreement. We showed that including multiple locomotion traits improves the classification accuracy from 76.6% with only one trait to 79.9% with the three most important traits and to 80.1% with all six locomotion traits.
T-LEAP: occlusion-robust pose estimation of walking cows using temporal information
Apr 16, 2021


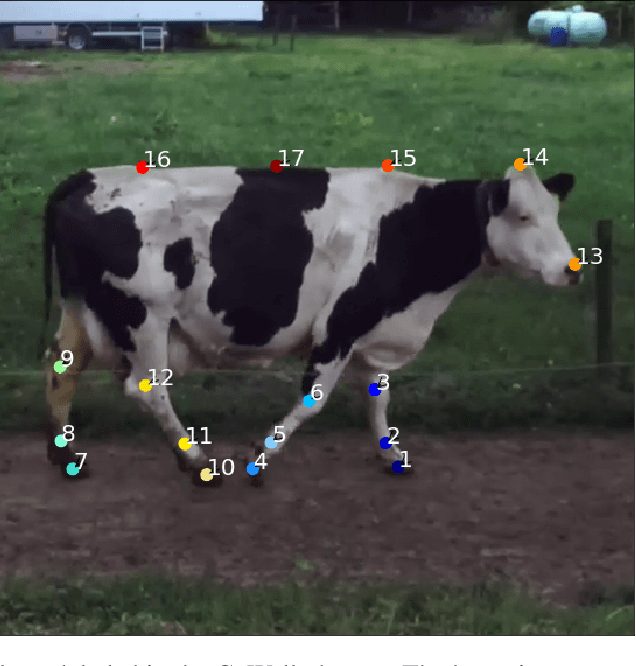
As herd size on dairy farms continue to increase, automatic health monitoring of cows has gained in interest. Lameness, a prevalent health disorder in dairy cows, is commonly detected by analyzing the gait of cows. A cow's gait can be tracked in videos using pose estimation models because models learn to automatically localize anatomical landmarks in images and videos. Most animal pose estimation models are static, that is, videos are processed frame by frame and do not use any temporal information. In this work, a static deep-learning model for animal-pose-estimation was extended to a temporal model that includes information from past frames. We compared the performance of the static and temporal pose estimation models. The data consisted of 1059 samples of 4 consecutive frames extracted from videos (30 fps) of 30 different dairy cows walking through an outdoor passageway. As farm environments are prone to occlusions, we tested the robustness of the static and temporal models by adding artificial occlusions to the videos. The experiments showed that, on non-occluded data, both static and temporal approaches achieved a Percentage of Correct Keypoints (PCKh@0.2) of 99%. On occluded data, our temporal approach outperformed the static one by up to 32.9%, suggesting that using temporal data is beneficial for pose estimation in environments prone to occlusions, such as dairy farms. The generalization capabilities of the temporal model was evaluated by testing it on data containing unknown cows (cows not present in the training set). The results showed that the average detection rate (PCKh@0.2) was of 93.8% on known cows and 87.6% on unknown cows, indicating that the model is capable of generalizing well to new cows and that they could be easily fine-tuned to new herds. Finally, we showed that with harder tasks, such as occlusions and unknown cows, a deeper architecture was more beneficial.