 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Guarantees on Automated Precision Weeding using Conformal Prediction
Jan 13, 2025Precision agriculture in general, and precision weeding in particular, have greatly benefited from the major advancements in deep learning and computer vision. A large variety of commercial robotic solutions are already available and deployed. However, the adoption by farmers of such solutions is still low for many reasons, an important one being the lack of trust in these systems. This is in great part due to the opaqueness and complexity of deep neural networks and the manufacturers' inability to provide valid guarantees on their performance. Conformal prediction, a well-established methodology in the machine learning community, is an efficient and reliable strategy for providing trustworthy guarantees on the predictions of any black-box model under very minimal constraints. Bridging the gap between the safe machine learning and precision agriculture communities, this article showcases conformal prediction in action on the task of precision weeding through deep learning-based image classification. After a detailed presentation of the conformal prediction methodology and the development of a precision spraying pipeline based on a ''conformalized'' neural network and well-defined spraying decision rules, the article evaluates this pipeline on two real-world scenarios: one under in-distribution conditions, the other reflecting a near out-of-distribution setting. The results show that we are able to provide formal, i.e. certifiable, guarantees on spraying at least 90% of the weeds.
The Penalized Inverse Probability Measure for Conformal Classification
Jun 13, 2024The deployment of safe and trustworthy machine learning systems, and particularly complex black box neural networks, in real-world applications requires reliable and certified guarantees on their performance. The conformal prediction framework offers such formal guarantees by transforming any point into a set predictor with valid, finite-set, guarantees on the coverage of the true at a chosen level of confidence. Central to this methodology is the notion of the nonconformity score function that assigns to each example a measure of ''strangeness'' in comparison with the previously seen observations. While the coverage guarantees are maintained regardless of the nonconformity measure, the point predictor and the dataset, previous research has shown that the performance of a conformal model, as measured by its efficiency (the average size of the predicted sets) and its informativeness (the proportion of prediction sets that are singletons), is influenced by the choice of the nonconformity score function. The current work introduces the Penalized Inverse Probability (PIP) nonconformity score, and its regularized version RePIP, that allow the joint optimization of both efficiency and informativeness. Through toy examples and empirical results on the task of crop and weed image classification in agricultural robotics, the current work shows how PIP-based conformal classifiers exhibit precisely the desired behavior in comparison with other nonconformity measures and strike a good balance between informativeness and efficiency.
Active learning for efficient annotation in precision agriculture: a use-case on crop-weed semantic segmentation
Apr 03, 2024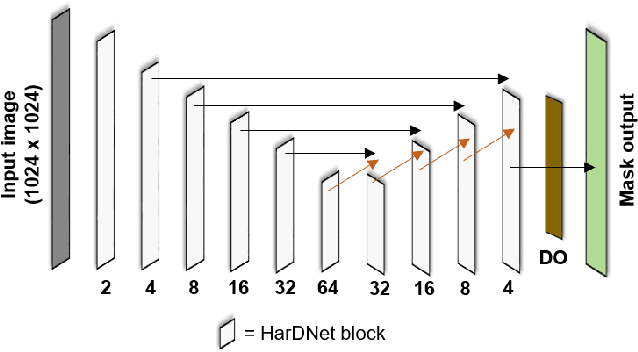



Optimizing deep learning models requires large amounts of annotated images, a process that is both time-intensive and costly. Especially for semantic segmentation models in which every pixel must be annotated. A potential strategy to mitigate annotation effort is active learning. Active learning facilitates the identification and selection of the most informative images from a large unlabelled pool. The underlying premise is that these selected images can improve the model's performance faster than random selection to reduce annotation effort. While active learning has demonstrated promising results on benchmark datasets like Cityscapes, its performance in the agricultural domain remains largely unexplored. This study addresses this research gap by conducting a comparative study of three active learning-based acquisition functions: Bayesian Active Learning by Disagreement (BALD), stochastic-based BALD (PowerBALD), and Random. The acquisition functions were tested on two agricultural datasets: Sugarbeet and Corn-Weed, both containing three semantic classes: background, crop and weed. Our results indicated that active learning, especially PowerBALD, yields a higher performance than Random sampling on both datasets. But due to the relatively large standard deviations, the differences observed were minimal; this was partly caused by high image redundancy and imbalanced classes. Specifically, more than 89\% of the pixels belonged to the background class on both datasets. The absence of significant results on both datasets indicates that further research is required for applying active learning on agricultural datasets, especially if they contain a high-class imbalance and redundant images. Recommendations and insights are provided in this paper to potentially resolve such issues.
Group-Conditional Conformal Prediction via Quantile Regression Calibration for Crop and Weed Classification
Aug 29, 2023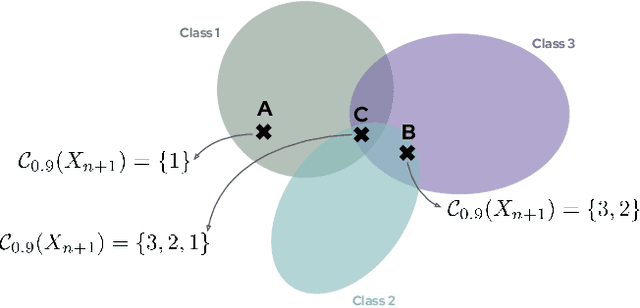

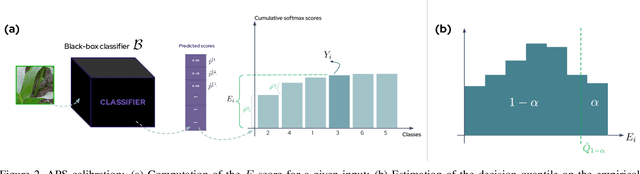
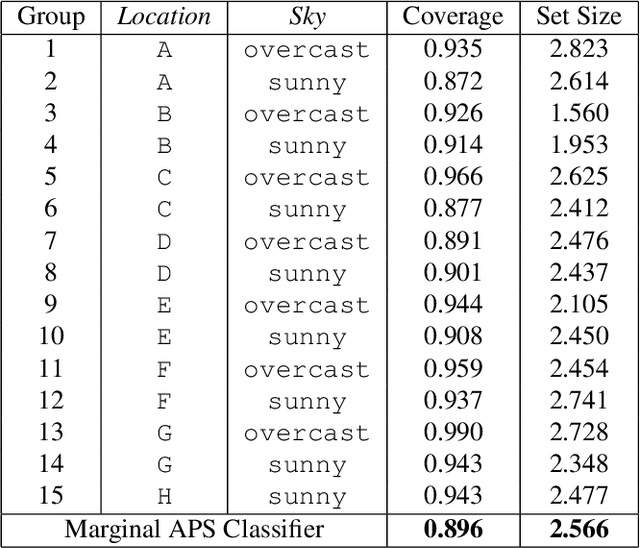
As deep learning predictive models become an integral part of a large spectrum of precision agricultural systems, a barrier to the adoption of such automated solutions is the lack of user trust in these highly complex, opaque and uncertain models. Indeed, deep neural networks are not equipped with any explicit guarantees that can be used to certify the system's performance, especially in highly varying uncontrolled environments such as the ones typically faced in computer vision for agriculture.Fortunately, certain methods developed in other communities can prove to be important for agricultural applications. This article presents the conformal prediction framework that provides valid statistical guarantees on the predictive performance of any black box prediction machine, with almost no assumptions, applied to the problem of deep visual classification of weeds and crops in real-world conditions. The framework is exposed with a focus on its practical aspects and special attention accorded to the Adaptive Prediction Sets (APS) approach that delivers marginal guarantees on the model's coverage. Marginal results are then shown to be insufficient to guarantee performance on all groups of individuals in the population as characterized by their environmental and pedo-climatic auxiliary data gathered during image acquisition.To tackle this shortcoming, group-conditional conformal approaches are presented: the ''classical'' method that consists of iteratively applying the APS procedure on all groups, and a proposed elegant reformulation and implementation of the procedure using quantile regression on group membership indicators. Empirical results showing the validity of the proposed approach are presented and compared to the marginal APS then discussed.
Active learning with MaskAL reduces annotation effort for training Mask R-CNN
Dec 13, 2021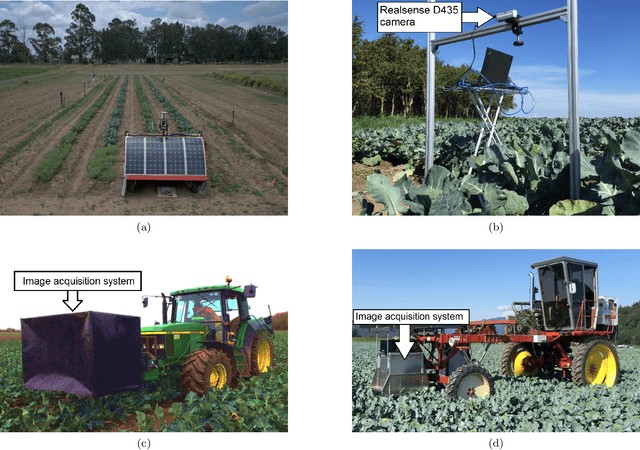
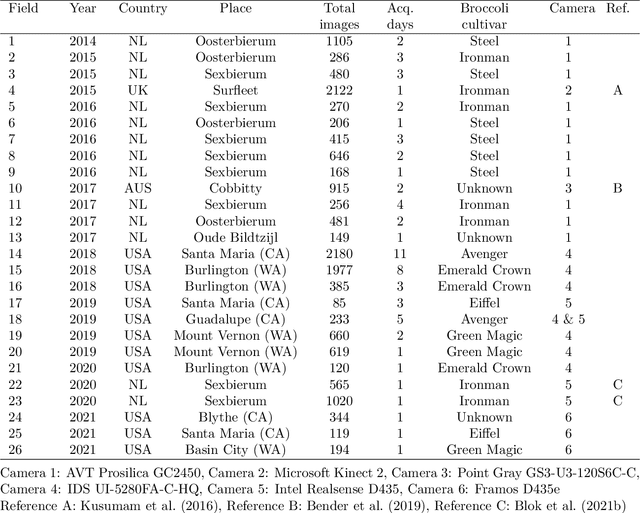

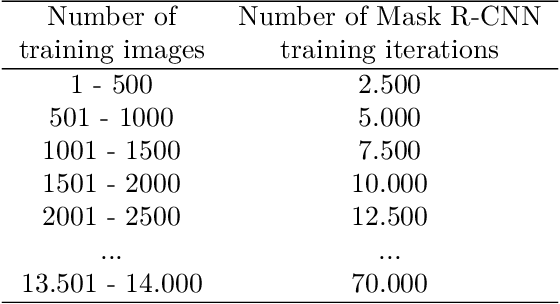
The generalisation performance of a convolutional neural network (CNN) is influenced by the quantity, quality, and variety of the training images. Training images must be annotated, and this is time consuming and expensive. The goal of our work was to reduce the number of annotated images needed to train a CNN while maintaining its performance. We hypothesised that the performance of a CNN can be improved faster by ensuring that the set of training images contains a large fraction of hard-to-classify images. The objective of our study was to test this hypothesis with an active learning method that can automatically select the hard-to-classify images. We developed an active learning method for Mask Region-based CNN (Mask R-CNN) and named this method MaskAL. MaskAL involved the iterative training of Mask R-CNN, after which the trained model was used to select a set of unlabelled images about which the model was uncertain. The selected images were then annotated and used to retrain Mask R-CNN, and this was repeated for a number of sampling iterations. In our study, Mask R-CNN was trained on 2500 broccoli images that were selected through 12 sampling iterations by either MaskAL or a random sampling method from a training set of 14,000 broccoli images. For all sampling iterations, MaskAL performed significantly better than the random sampling. Furthermore, MaskAL had the same performance after sampling 900 images as the random sampling had after 2300 images. Compared to a Mask R-CNN model that was trained on the entire training set (14,000 images), MaskAL achieved 93.9% of its performance with 17.9% of its training data. The random sampling achieved 81.9% of its performance with 16.4% of its training data. We conclude that by using MaskAL, the annotation effort can be reduced for training Mask R-CNN on a broccoli dataset. Our software is available on https://github.com/pieterblok/maskal.