 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Variational Differential Privacy via Embedding Parameter Clipping
Mar 10, 2026The nonparametric variational information bottleneck (NVIB) provides the foundation for nonparametric variational differential privacy (NVDP), a framework for building privacy-preserving language models. However, the learned latent representations can drift into regions with high information content, leading to poor privacy guarantees, but also low utility due to numerical instability during training. In this work, we introduce a principled parameter clipping strategy to directly address this issue. Our method is mathematically derived from the objective of minimizing the Rényi Divergence (RD) upper bound, yielding specific, theoretically grounded constraints on the posterior mean, variance, and mixture weight parameters. We apply our technique to an NVIB based model and empirically compare it against an unconstrained baseline. Our findings demonstrate that the clipped model consistently achieves tighter RD bounds, implying stronger privacy, while simultaneously attaining higher performance on several downstream tasks. This work presents a simple yet effective method for improving the privacy-utility trade-off in variational models, making them more robust and practical.
Differential Privacy for Transformer Embeddings of Text with Nonparametric Variational Information Bottleneck
Jan 05, 2026We propose a privacy-preserving method for sharing text data by sharing noisy versions of their transformer embeddings. It has been shown that hidden representations learned by deep models can encode sensitive information from the input, making it possible for adversaries to recover the input data with considerable accuracy. This problem is exacerbated in transformer embeddings because they consist of multiple vectors, one per token. To mitigate this risk, we propose Nonparametric Variational Differential Privacy (NVDP), which ensures both useful data sharing and strong privacy protection. We take a differential privacy approach, integrating a Nonparametric Variational Information Bottleneck (NVIB) layer into the transformer architecture to inject noise into its multi-vector embeddings and thereby hide information, and measuring privacy protection with Rényi divergence and its corresponding Bayesian Differential Privacy (BDP) guarantee. Training the NVIB layer calibrates the noise level according to utility. We test NVDP on the GLUE benchmark and show that varying the noise level gives us a useful tradeoff between privacy and accuracy. With lower noise levels, our model maintains high accuracy while offering strong privacy guarantees, effectively balancing privacy and utility.
Discovering Meaningful Units with Visually Grounded Semantics from Image Captions
Nov 14, 2025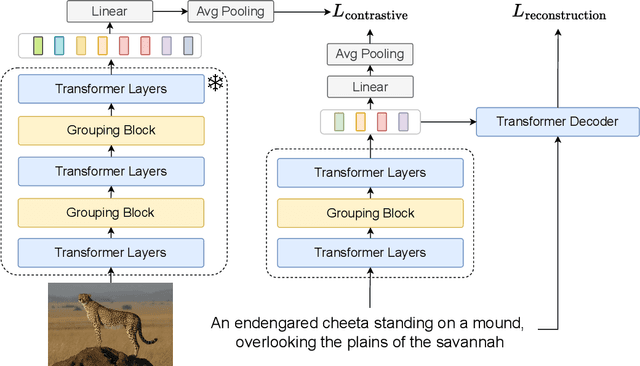
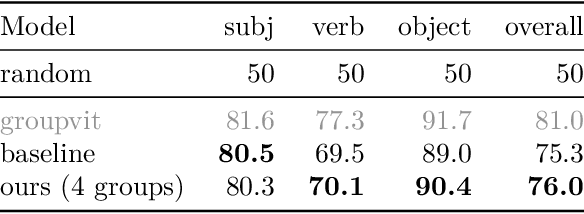

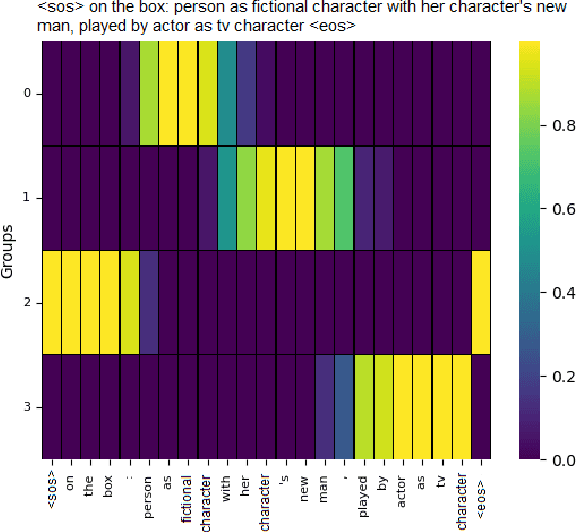
Fine-grained knowledge is crucial for vision-language models to obtain a better understanding of the real world. While there has been work trying to acquire this kind of knowledge in the space of vision and language, it has mostly focused on aligning the image patches with the tokens on the language side. However, image patches do not have any meaning to the human eye, and individual tokens do not necessarily carry groundable information in the image. It is groups of tokens which describe different aspects of the scene. In this work, we propose a model which groups the caption tokens as part of its architecture in order to capture a fine-grained representation of the language. We expect our representations to be at the level of objects present in the image, and therefore align our representations with the output of an image encoder trained to discover objects. We show that by learning to group the tokens, the vision-language model has a better fine-grained understanding of vision and language. In addition, the token groups that our model discovers are highly similar to groundable phrases in text, both qualitatively and quantitatively.
Reduction of Supervision for Biomedical Knowledge Discovery
Apr 13, 2025Knowledge discovery is hindered by the increasing volume of publications and the scarcity of extensive annotated data. To tackle the challenge of information overload, it is essential to employ automated methods for knowledge extraction and processing. Finding the right balance between the level of supervision and the effectiveness of models poses a significant challenge. While supervised techniques generally result in better performance, they have the major drawback of demanding labeled data. This requirement is labor-intensive and time-consuming and hinders scalability when exploring new domains. In this context, our study addresses the challenge of identifying semantic relationships between biomedical entities (e.g., diseases, proteins) in unstructured text while minimizing dependency on supervision. We introduce a suite of unsupervised algorithms based on dependency trees and attention mechanisms and employ a range of pointwise binary classification methods. Transitioning from weakly supervised to fully unsupervised settings, we assess the methods' ability to learn from data with noisy labels. The evaluation on biomedical benchmark datasets explores the effectiveness of the methods. Our approach tackles a central issue in knowledge discovery: balancing performance with minimal supervision. By gradually decreasing supervision, we assess the robustness of pointwise binary classification techniques in handling noisy labels, revealing their capability to shift from weakly supervised to entirely unsupervised scenarios. Comprehensive benchmarking offers insights into the effectiveness of these techniques, suggesting an encouraging direction toward adaptable knowledge discovery systems, representing progress in creating data-efficient methodologies for extracting useful insights when annotated data is limited.
Data-driven Discovery of Biophysical T Cell Receptor Co-specificity Rules
Dec 18, 2024



The biophysical interactions between the T cell receptor (TCR) and its ligands determine the specificity of the cellular immune response. However, the immense diversity of receptors and ligands has made it challenging to discover generalizable rules across the distinct binding affinity landscapes created by different ligands. Here, we present an optimization framework for discovering biophysical rules that predict whether TCRs share specificity to a ligand. Applying this framework to TCRs associated with a collection of SARS-CoV-2 peptides we establish how co-specificity depends on the type and position of amino-acid differences between receptors. We also demonstrate that the inferred rules generalize to ligands not seen during training. Our analysis reveals that matching of steric properties between substituted amino acids is important for receptor co-specificity, in contrast with the hydrophobic properties that more prominently determine evolutionary substitutability. We furthermore find that positions not in direct contact with the peptide still significantly impact specificity. These findings highlight the potential for data-driven approaches to uncover the molecular mechanisms underpinning the specificity of adaptive immune responses.
Fast-and-Frugal Text-Graph Transformers are Effective Link Predictors
Aug 13, 2024



Link prediction models can benefit from incorporating textual descriptions of entities and relations, enabling fully inductive learning and flexibility in dynamic graphs. We address the challenge of also capturing rich structured information about the local neighbourhood of entities and their relations, by introducing a Transformer-based approach that effectively integrates textual descriptions with graph structure, reducing the reliance on resource-intensive text encoders. Our experiments on three challenging datasets show that our Fast-and-Frugal Text-Graph (FnF-TG) Transformers achieve superior performance compared to the previous state-of-the-art methods, while maintaining efficiency and scalability.
Enhancing Biomedical Knowledge Discovery for Diseases: An End-To-End Open-Source Framework
Jul 18, 2024



The ever-growing volume of biomedical publications creates a critical need for efficient knowledge discovery. In this context, we introduce an open-source end-to-end framework designed to construct knowledge around specific diseases directly from raw text. To facilitate research in disease-related knowledge discovery, we create two annotated datasets focused on Rett syndrome and Alzheimer's disease, enabling the identification of semantic relations between biomedical entities. Extensive benchmarking explores various ways to represent relations and entity representations, offering insights into optimal modeling strategies for semantic relation detection and highlighting language models' competence in knowledge discovery. We also conduct probing experiments using different layer representations and attention scores to explore transformers' ability to capture semantic relations.
Contrastive learning of T cell receptor representations
Jun 10, 2024Computational prediction of the interaction of T cell receptors (TCRs) and their ligands is a grand challenge in immunology. Despite advances in high-throughput assays, specificity-labelled TCR data remains sparse. In other domains, the pre-training of language models on unlabelled data has been successfully used to address data bottlenecks. However, it is unclear how to best pre-train protein language models for TCR specificity prediction. Here we introduce a TCR language model called SCEPTR (Simple Contrastive Embedding of the Primary sequence of T cell Receptors), capable of data-efficient transfer learning. Through our model, we introduce a novel pre-training strategy combining autocontrastive learning and masked-language modelling, which enables SCEPTR to achieve its state-of-the-art performance. In contrast, existing protein language models and a variant of SCEPTR pre-trained without autocontrastive learning are outperformed by sequence alignment-based methods. We anticipate that contrastive learning will be a useful paradigm to decode the rules of TCR specificity.
Nonparametric Variational Regularisation of Pretrained Transformers
Dec 01, 2023



The current paradigm of large-scale pre-training and fine-tuning Transformer large language models has lead to significant improvements across the board in natural language processing. However, such large models are susceptible to overfitting to their training data, and as a result the models perform poorly when the domain changes. Also, due to the model's scale, the cost of fine-tuning the model to the new domain is large. Nonparametric Variational Information Bottleneck (NVIB) has been proposed as a regulariser for training cross-attention in Transformers, potentially addressing the overfitting problem. We extend the NVIB framework to replace all types of attention functions in Transformers, and show that existing pretrained Transformers can be reinterpreted as Nonparametric Variational (NV) models using a proposed identity initialisation. We then show that changing the initialisation introduces a novel, information-theoretic post-training regularisation in the attention mechanism, which improves out-of-domain generalisation without any training. This success supports the hypothesis that pretrained Transformers are implicitly NV Bayesian models.
Transformers as Graph-to-Graph Models
Oct 27, 2023We argue that Transformers are essentially graph-to-graph models, with sequences just being a special case. Attention weights are functionally equivalent to graph edges. Our Graph-to-Graph Transformer architecture makes this ability explicit, by inputting graph edges into the attention weight computations and predicting graph edges with attention-like functions, thereby integrating explicit graphs into the latent graphs learned by pretrained Transformers. Adding iterative graph refinement provides a joint embedding of input, output, and latent graphs, allowing non-autoregressive graph prediction to optimise the complete graph without any bespoke pipeline or decoding strategy. Empirical results show that this architecture achieves state-of-the-art accuracies for modelling a variety of linguistic structures, integrating very effectively with the latent linguistic representations learned by pretraining.