 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-and-Frugal Text-Graph Transformers are Effective Link Predictors
Aug 13, 2024



Link prediction models can benefit from incorporating textual descriptions of entities and relations, enabling fully inductive learning and flexibility in dynamic graphs. We address the challenge of also capturing rich structured information about the local neighbourhood of entities and their relations, by introducing a Transformer-based approach that effectively integrates textual descriptions with graph structure, reducing the reliance on resource-intensive text encoders. Our experiments on three challenging datasets show that our Fast-and-Frugal Text-Graph (FnF-TG) Transformers achieve superior performance compared to the previous state-of-the-art methods, while maintaining efficiency and scalability.
Transformers as Graph-to-Graph Models
Oct 27, 2023We argue that Transformers are essentially graph-to-graph models, with sequences just being a special case. Attention weights are functionally equivalent to graph edges. Our Graph-to-Graph Transformer architecture makes this ability explicit, by inputting graph edges into the attention weight computations and predicting graph edges with attention-like functions, thereby integrating explicit graphs into the latent graphs learned by pretrained Transformers. Adding iterative graph refinement provides a joint embedding of input, output, and latent graphs, allowing non-autoregressive graph prediction to optimise the complete graph without any bespoke pipeline or decoding strategy. Empirical results show that this architecture achieves state-of-the-art accuracies for modelling a variety of linguistic structures, integrating very effectively with the latent linguistic representations learned by pretraining.
Strong and Efficient Baselines for Open Domain Conversational Question Answering
Oct 23, 2023Unlike the Open Domain Question Answering (ODQA) setting, the conversational (ODConvQA) domain has received limited attention when it comes to reevaluating baselines for both efficiency and effectiveness. In this paper, we study the State-of-the-Art (SotA) Dense Passage Retrieval (DPR) retriever and Fusion-in-Decoder (FiD) reader pipeline, and show that it significantly underperforms when applied to ODConvQA tasks due to various limitations. We then propose and evaluate strong yet simple and efficient baselines, by introducing a fast reranking component between the retriever and the reader, and by performing targeted finetuning steps. Experiments on two ODConvQA tasks, namely TopiOCQA and OR-QuAC, show that our method improves the SotA results, while reducing reader's latency by 60%. Finally, we provide new and valuable insights into the development of challenging baselines that serve as a reference for future, more intricate approaches, including those that leverage Large Language Models (LLMs).
GADePo: Graph-Assisted Declarative Pooling Transformers for Document-Level Relation Extraction
Aug 28, 2023Document-level relation extraction aims to identify relationships between entities within a document. Current methods rely on text-based encoders and employ various hand-coded pooling heuristics to aggregate information from entity mentions and associated contexts. In this paper, we replace these rigid pooling functions with explicit graph relations by leveraging the intrinsic graph processing capabilities of the Transformer model. We propose a joint text-graph Transformer model, and a graph-assisted declarative pooling (GADePo) specification of the input which provides explicit and high-level instructions for information aggregation. This allows the pooling process to be guided by domain-specific knowledge or desired outcomes but still learned by the Transformer, leading to more flexible and customizable pooling strategies. We extensively evaluate our method across diverse datasets and models, and show that our approach yields promising results that are comparable to those achieved by the hand-coded pooling functions.
Imposing Relation Structure in Language-Model Embeddings Using Contrastive Learning
Sep 04, 2021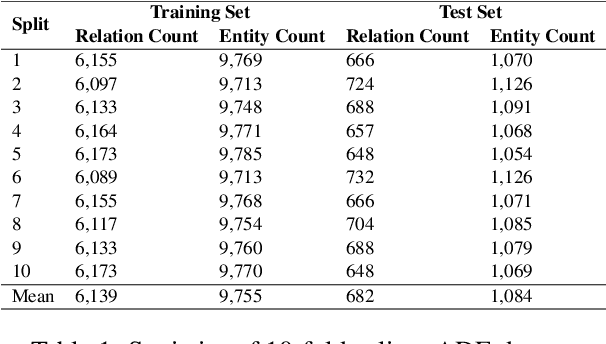
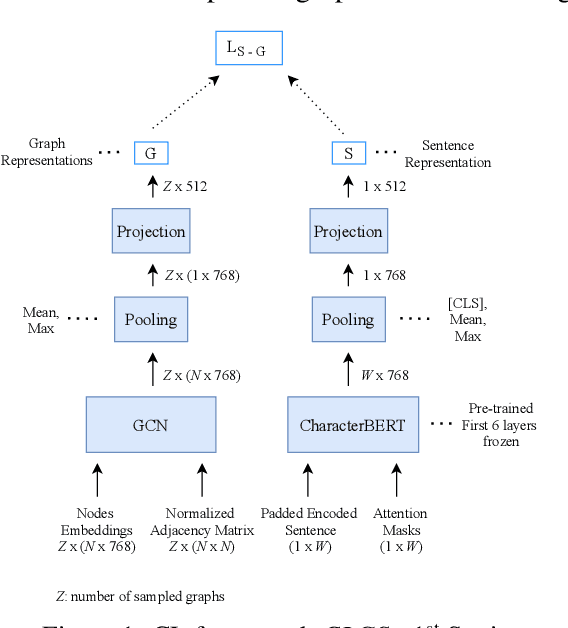
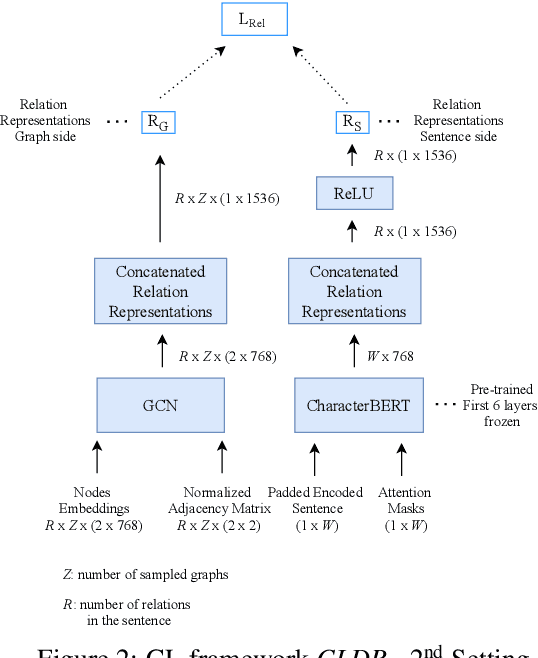
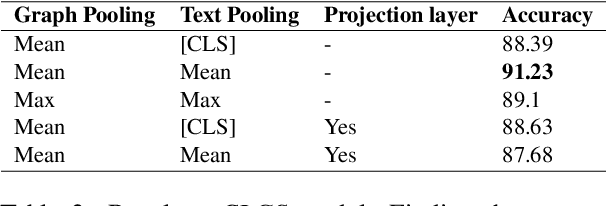
Though language model text embeddings have revolutionized NLP research, their ability to capture high-level semantic information, such as relations between entities in text, is limited. In this paper, we propose a novel contrastive learning framework that trains sentence embeddings to encode the relations in a graph structure. Given a sentence (unstructured text) and its graph, we use contrastive learning to impose relation-related structure on the token-level representations of the sentence obtained with a CharacterBERT (El Boukkouri et al.,2020) model. The resulting relation-aware sentence embeddings achieve state-of-the-art results on the relation extraction task using only a simple KNN classifier, thereby demonstrating the success of the proposed method. Additional visualization by a tSNE analysis shows the effectiveness of the learned representation space compared to baselines. Furthermore, we show that we can learn a different space for named entity recognition, again using a contrastive learning objective, and demonstrate how to successfully combine both representation spaces in an entity-relation task.
An Incremental Turn-Taking Model For Task-Oriented Dialog Systems
May 28, 2019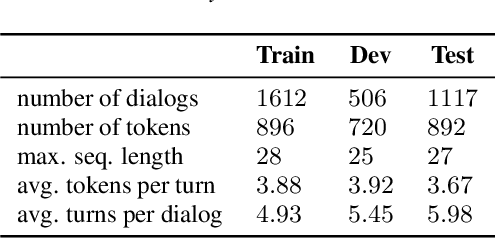
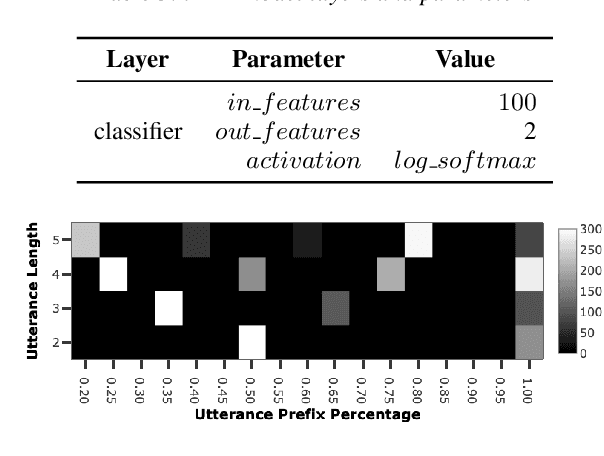
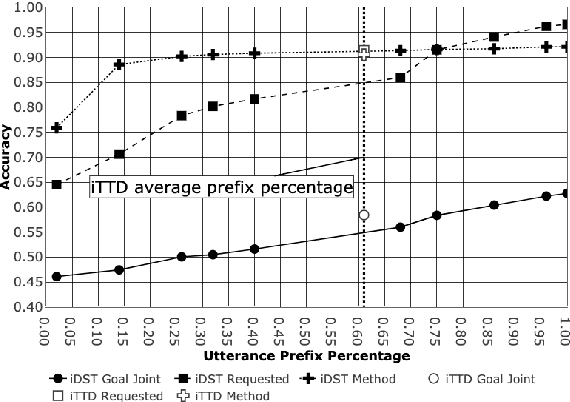

In a human-machine dialog scenario, deciding the appropriate time for the machine to take the turn is an open research problem. In contrast, humans engaged in conversations are able to timely decide when to interrupt the speaker for competitive or non-competitive reasons. In state-of-the-art turn-by-turn dialog systems the decision on the next dialog action is taken at the end of the utterance. In this paper, we propose a token-by-token prediction of the dialog state from incremental transcriptions of the user utterance. To identify the point of maximal understanding in an ongoing utterance, we a) implement an incremental Dialog State Tracker which is updated on a token basis (iDST) b) re-label the Dialog State Tracking Challenge 2 (DSTC2) dataset and c) adapt it to the incremental turn-taking experimental scenario. The re-labeling consists of assigning a binary value to each token in the user utterance that allows to identify the appropriate point for taking the turn. Finally, we implement an incremental Turn Taking Decider (iTTD) that is trained on these new labels for the turn-taking decision. We show that the proposed model can achieve a better performance compared to a deterministic handcrafted turn-taking algorithm.