 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho is the richest club in the championship? Detecting and Rewriting Underspecified Questions Improve QA Performance
Feb 17, 2026Large language models (LLMs) perform well on well-posed questions, yet standard question-answering (QA) benchmarks remain far from solved. We argue that this gap is partly due to underspecified questions - queries whose interpretation cannot be uniquely determined without additional context. To test this hypothesis, we introduce an LLM-based classifier to identify underspecified questions and apply it to several widely used QA datasets, finding that 16% to over 50% of benchmark questions are underspecified and that LLMs perform significantly worse on them. To isolate the effect of underspecification, we conduct a controlled rewriting experiment that serves as an upper-bound analysis, rewriting underspecified questions into fully specified variants while holding gold answers fixed. QA performance consistently improves under this setting, indicating that many apparent QA failures stem from question underspecification rather than model limitations. Our findings highlight underspecification as an important confound in QA evaluation and motivate greater attention to question clarity in benchmark design.
Strong and Efficient Baselines for Open Domain Conversational Question Answering
Oct 23, 2023Unlike the Open Domain Question Answering (ODQA) setting, the conversational (ODConvQA) domain has received limited attention when it comes to reevaluating baselines for both efficiency and effectiveness. In this paper, we study the State-of-the-Art (SotA) Dense Passage Retrieval (DPR) retriever and Fusion-in-Decoder (FiD) reader pipeline, and show that it significantly underperforms when applied to ODConvQA tasks due to various limitations. We then propose and evaluate strong yet simple and efficient baselines, by introducing a fast reranking component between the retriever and the reader, and by performing targeted finetuning steps. Experiments on two ODConvQA tasks, namely TopiOCQA and OR-QuAC, show that our method improves the SotA results, while reducing reader's latency by 60%. Finally, we provide new and valuable insights into the development of challenging baselines that serve as a reference for future, more intricate approaches, including those that leverage Large Language Models (LLMs).
Low-Resource Dense Retrieval for Open-Domain Question Answering: A Comprehensive Survey
Aug 05, 2022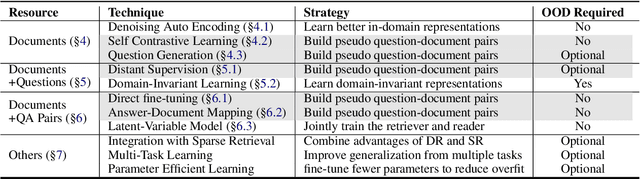
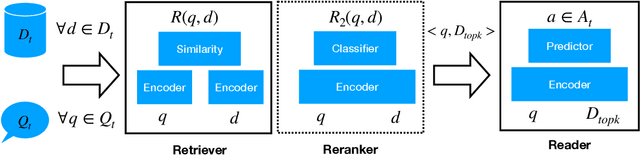
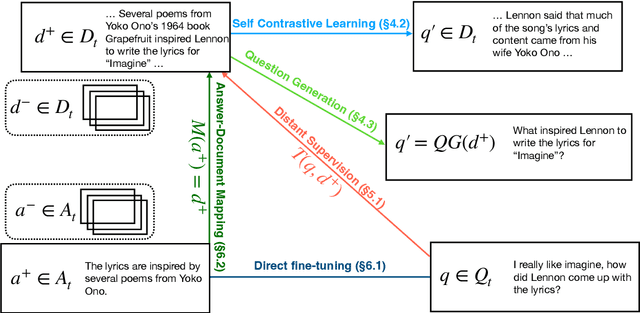

Dense retrieval (DR) approaches based on powerful pre-trained language models (PLMs) achieved significant advances and have become a key component for modern open-domain question-answering systems. However, they require large amounts of manual annotations to perform competitively, which is infeasible to scale. To address this, a growing body of research works have recently focused on improving DR performance under low-resource scenarios. These works differ in what resources they require for training and employ a diverse set of techniques. Understanding such differences is crucial for choosing the right technique under a specific low-resource scenario. To facilitate this understanding, we provide a thorough structured overview of mainstream techniques for low-resource DR. Based on their required resources, we divide the techniques into three main categories: (1) only documents are needed; (2) documents and questions are needed; and (3) documents and question-answer pairs are needed. For every technique, we introduce its general-form algorithm, highlight the open issues and pros and cons. Promising directions are outlined for future research.
From Rewriting to Remembering: Common Ground for Conversational QA Models
Apr 08, 2022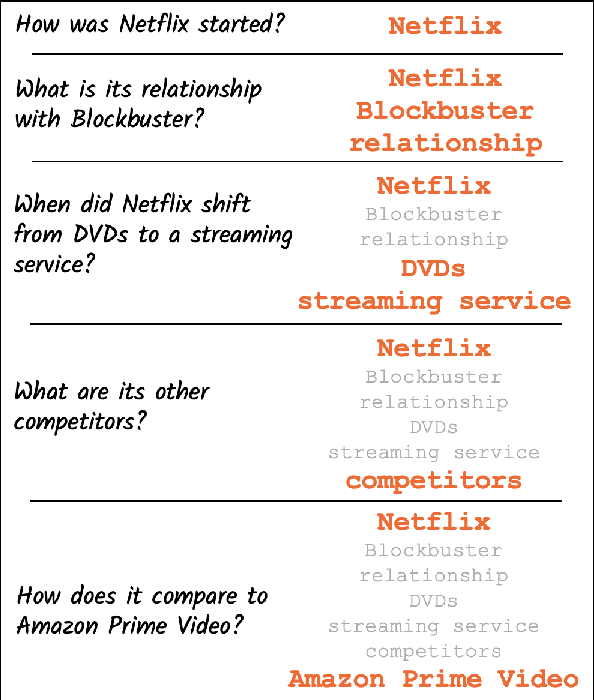
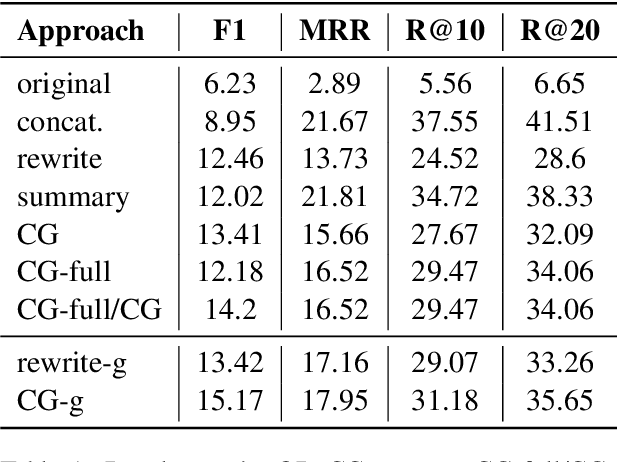


In conversational QA, models have to leverage information in previous turns to answer upcoming questions. Current approaches, such as Question Rewriting, struggle to extract relevant information as the conversation unwinds. We introduce the Common Ground (CG), an approach to accumulate conversational information as it emerges and select the relevant information at every turn. We show that CG offers a more efficient and human-like way to exploit conversational information compared to existing approaches, leading to improvements on Open Domain Conversational QA.
Trajectory Test-Train Overlap in Next-Location Prediction Datasets
Mar 07, 2022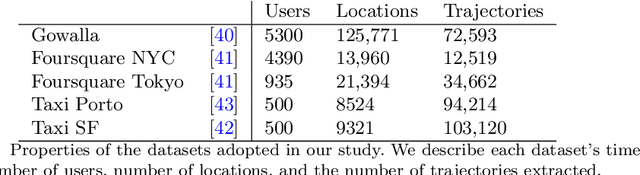
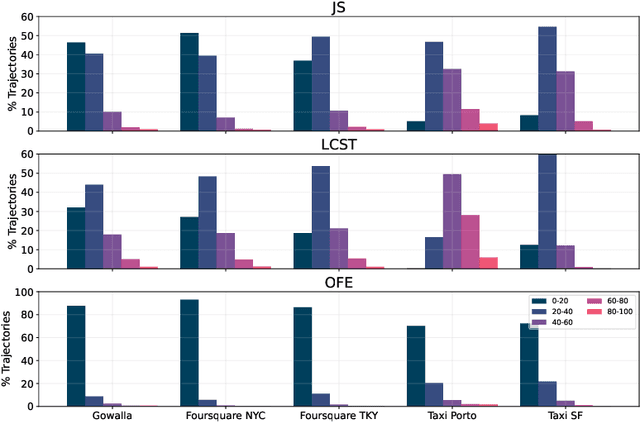
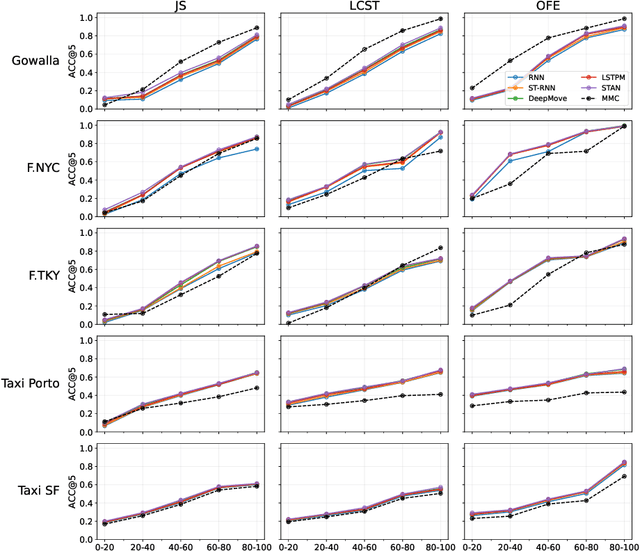
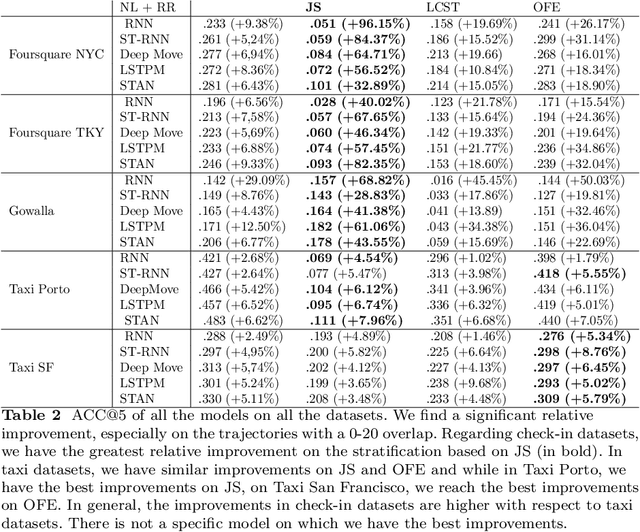
Next-location prediction, consisting of forecasting a user's location given their historical trajectories, has important implications in several fields, such as urban planning, geo-marketing, and disease spreading. Several predictors have been proposed in the last few years to address it, including last-generation ones based on deep learning. This paper tests the generalization capability of these predictors on public mobility datasets, stratifying the datasets by whether the trajectories in the test set also appear fully or partially in the training set. We consistently discover a severe problem of trajectory overlapping in all analyzed datasets, highlighting that predictors memorize trajectories while having limited generalization capacities. We thus propose a methodology to rerank the outputs of the next-location predictors based on spatial mobility patterns. With these techniques, we significantly improve the predictors' generalization capability, with a relative improvement on the accuracy up to 96.15% on the trajectories that cannot be memorized (i.e., low overlap with the training set).
Deep Gravity: enhancing mobility flows generation with deep neural networks and geographic information
Dec 30, 2020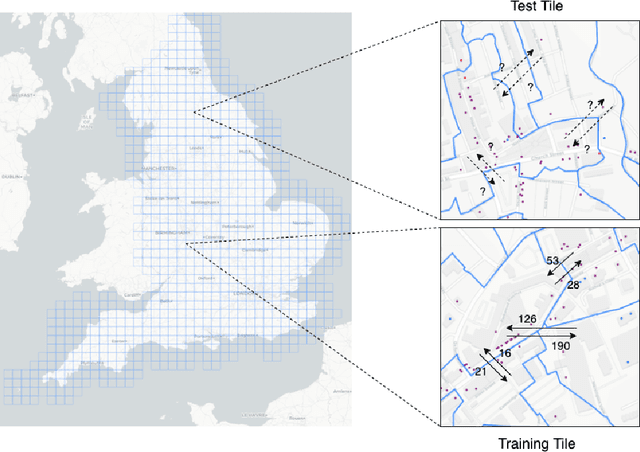

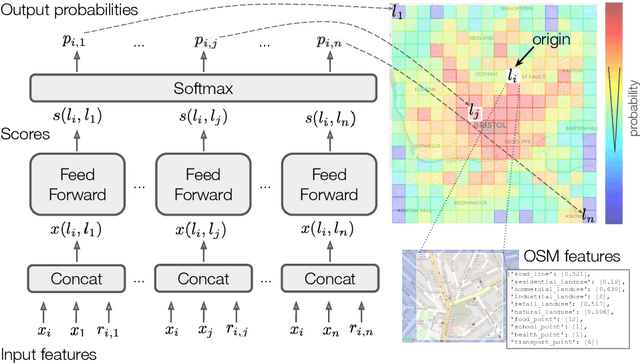
The movements of individuals within and among cities influence key aspects of our society, such as the objective and subjective well-being, the diffusion of innovations, the spreading of epidemics, and the quality of the environment. For this reason, there is increasing interest around the challenging problem of flow generation, which consists in generating the flows between a set of geographic locations, given the characteristics of the locations and without any information about the real flows. Existing solutions to flow generation are mainly based on mechanistic approaches, such as the gravity model and the radiation model, which suffer from underfitting and overdispersion, neglect important variables such as land use and the transportation network, and cannot describe non-linear relationships between these variables. In this paper, we propose the Multi-Feature Deep Gravity (MFDG) model as an effective solution to flow generation. On the one hand, the MFDG model exploits a large number of variables (e.g., characteristics of land use and the road network; transport, food, and health facilities) extracted from voluntary geographic information data (OpenStreetMap). On the other hand, our model exploits deep neural networks to describe complex non-linear relationships between those variables. Our experiments, conducted on commuting flows in England, show that the MFDG model achieves a significant increase in the performance (up to 250\% for highly populated areas) than mechanistic models that do not use deep neural networks, or that do not exploit geographic voluntary data. Our work presents a precise definition of the flow generation problem, which is a novel task for the deep learning community working with spatio-temporal data, and proposes a deep neural network model that significantly outperforms current state-of-the-art statistical models.
Deep Learning for Human Mobility: a Survey on Data and Models
Dec 04, 2020The study of human mobility is crucial due to its impact on several aspects of our society, such as disease spreading, urban planning, well-being, pollution, and more. The proliferation of digital mobility data, such as phone records, GPS traces, and social media posts, combined with the outstanding predictive power of artificial intelligence, triggered the application of deep learning to human mobility. In particular, the literature is focusing on three tasks: next-location prediction, i.e., predicting an individual's future locations; crowd flow prediction, i.e., forecasting flows on a geographic region; and trajectory generation, i.e., generating realistic individual trajectories. Existing surveys focus on single tasks, data sources, mechanistic or traditional machine learning approaches, while a comprehensive description of deep learning solutions is missing. This survey provides: (i) basic notions on mobility and deep learning; (ii) a review of data sources and public datasets; (iii) a description of deep learning models and (iv) a discussion about relevant open challenges. Our survey is a guide to the leading deep learning solutions to next-location prediction, crowd flow prediction, and trajectory generation. At the same time, it helps deep learning scientists and practitioners understand the fundamental concepts and the open challenges of the study of human mobility.
Modeling Taxi Drivers' Behaviour for the Next Destination Prediction
Jul 21, 2018
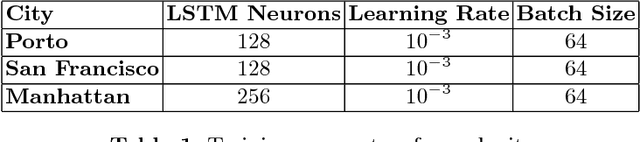
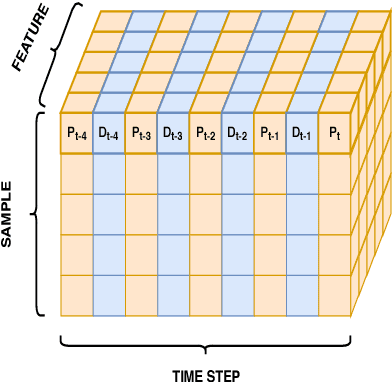
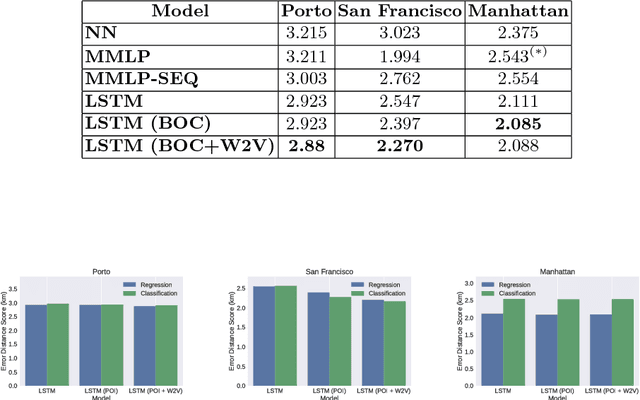
Taxi destination prediction is a very important task for optimizing the efficiency of electronic dispatching systems, thus allowing relevant advantages for both taxi companies and customers. In fact, during periods of high demand, there should be a taxi whose current ride will end near a requested pick up location from a new customer. If an electronic dispatcher is able to know in advance where all taxi drivers will end their current ride, it will also be able to better allocate its resources, identifying which taxi to assign to each call. Moreover, automatic systems for the taxi mobility monitoring collect data that, integrated with other information sources, can help in understanding daytime human mobility routines. In this paper, we introduce a novel approach for addressing the taxi destination prediction problem, based on Recurrent Neural Networks (RNNs) applied to a regression setting. RNNs are trained based on the individual drivers' history and on geographical information (i.e., points of interest), using only the starting point of each ride (with no knowledge about the whole trajectory). The proposed approach was tested on the dataset of the ECML/PKDD Discovery Challenge 2015 - based on the city of Porto - obtaining better results with respect to the competition winner, whilst using less information, and on Manhattan and San Francisco datasets.