 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Diversity Paradox revisited: Systemic Effects of Feedback Loops in Recommender Systems
Feb 18, 2026Recommender systems shape individual choices through feedback loops in which user behavior and algorithmic recommendations coevolve over time. The systemic effects of these loops remain poorly understood, in part due to unrealistic assumptions in existing simulation studies. We propose a feedback-loop model that captures implicit feedback, periodic retraining, probabilistic adoption of recommendations, and heterogeneous recommender systems. We apply the framework on online retail and music streaming data and analyze systemic effects of the feedback loop. We find that increasing recommender adoption may lead to a progressive diversification of individual consumption, while collective demand is redistributed in model- and domain-dependent ways, often amplifying popularity concentration. Temporal analyses further reveal that apparent increases in individual diversity observed in static evaluations are illusory: when adoption is fixed and time unfolds, individual diversity consistently decreases across all models. Our results highlight the need to move beyond static evaluations and explicitly account for feedback-loop dynamics when designing recommender systems.
Position: Explaining Behavioral Shifts in Large Language Models Requires a Comparative Approach
Feb 02, 2026Large-scale foundation models exhibit behavioral shifts: intervention-induced behavioral changes that appear after scaling, fine-tuning, reinforcement learning or in-context learning. While investigating these phenomena have recently received attention, explaining their appearance is still overlooked. Classic explainable AI (XAI) methods can surface failures at a single checkpoint of a model, but they are structurally ill-suited to justify what changed internally across different checkpoints and which explanatory claims are warranted about that change. We take the position that behavioral shifts should be explained comparatively: the core target should be the intervention-induced shift between a reference model and an intervened model, rather than any single model in isolation. To this aim we formulate a Comparative XAI ($Δ$-XAI) framework with a set of desiderata to be taken into account when designing proper explaining methods. To highlight how $Δ$-XAI methods work, we introduce a set of possible pipelines, relate them to the desiderata, and provide a concrete $Δ$-XAI experiment.
The Urban Impact of AI: Modeling Feedback Loops in Next-Venue Recommendation
Apr 10, 2025Next-venue recommender systems are increasingly embedded in location-based services, shaping individual mobility decisions in urban environments. While their predictive accuracy has been extensively studied, less attention has been paid to their systemic impact on urban dynamics. In this work, we introduce a simulation framework to model the human-AI feedback loop underpinning next-venue recommendation, capturing how algorithmic suggestions influence individual behavior, which in turn reshapes the data used to retrain the models. Our simulations, grounded in real-world mobility data, systematically explore the effects of algorithmic adoption across a range of recommendation strategies. We find that while recommender systems consistently increase individual-level diversity in visited venues, they may simultaneously amplify collective inequality by concentrating visits on a limited subset of popular places. This divergence extends to the structure of social co-location networks, revealing broader implications for urban accessibility and spatial segregation. Our framework operationalizes the feedback loop in next-venue recommendation and offers a novel lens through which to assess the societal impact of AI-assisted mobility-providing a computational tool to anticipate future risks, evaluate regulatory interventions, and inform the design of ethic algorithmic systems.
Characterizing User Behavior: The Interplay Between Mobility Patterns and Mobile Traffic
Jan 31, 2025Mobile devices have become essential for capturing human activity, and eXtended Data Records (XDRs) offer rich opportunities for detailed user behavior modeling, which is useful for designing personalized digital services. Previous studies have primarily focused on aggregated mobile traffic and mobility analyses, often neglecting individual-level insights. This paper introduces a novel approach that explores the dependency between traffic and mobility behaviors at the user level. By analyzing 13 individual features that encompass traffic patterns and various mobility aspects, we enhance the understanding of how these behaviors interact. Our advanced user modeling framework integrates traffic and mobility behaviors over time, allowing for fine-grained dependencies while maintaining population heterogeneity through user-specific signatures. Furthermore, we develop a Markov model that infers traffic behavior from mobility and vice versa, prioritizing significant dependencies while addressing privacy concerns. Using a week-long XDR dataset from 1,337,719 users across several provinces in Chile, we validate our approach, demonstrating its robustness and applicability in accurately inferring user behavior and matching mobility and traffic profiles across diverse urban contexts.
A linguistic analysis of undesirable outcomes in the era of generative AI
Oct 16, 2024
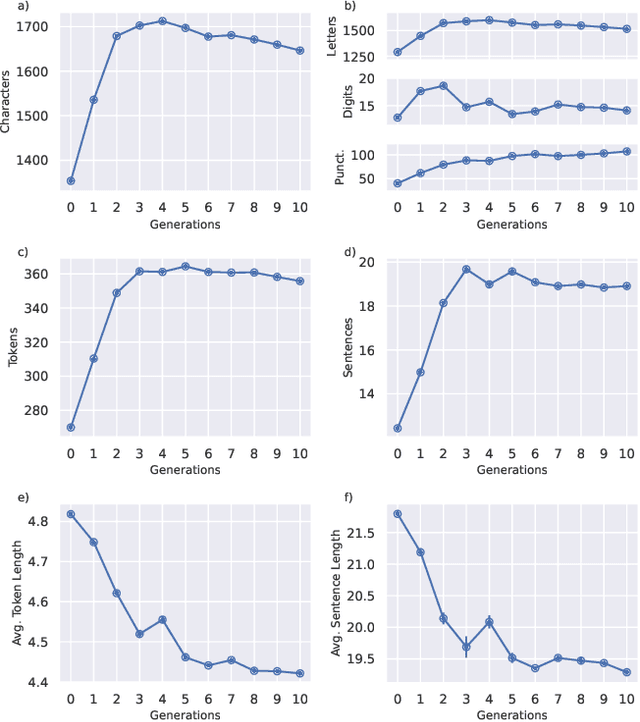
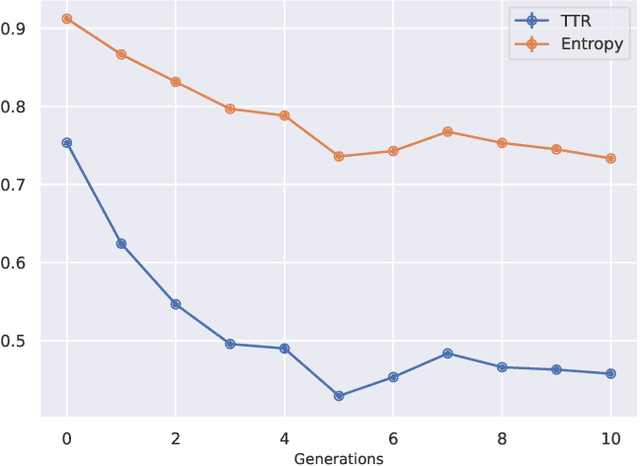
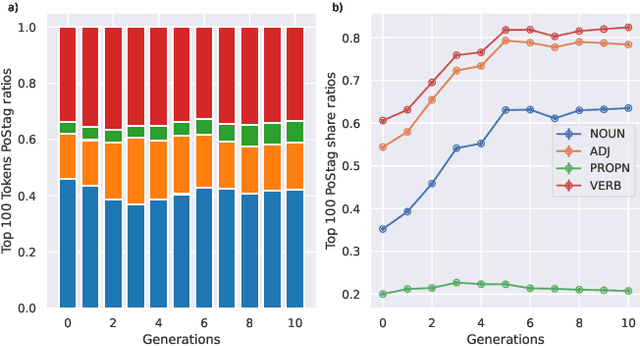
Recent research has focused on the medium and long-term impacts of generative AI, posing scientific and societal challenges mainly due to the detection and reliability of machine-generated information, which is projected to form the major content on the Web soon. Prior studies show that LLMs exhibit a lower performance in generation tasks (model collapse) as they undergo a fine-tuning process across multiple generations on their own generated content (self-consuming loop). In this paper, we present a comprehensive simulation framework built upon the chat version of LLama2, focusing particularly on the linguistic aspects of the generated content, which has not been fully examined in existing studies. Our results show that the model produces less lexical rich content across generations, reducing diversity. The lexical richness has been measured using the linguistic measures of entropy and TTR as well as calculating the POSTags frequency. The generated content has also been examined with an $n$-gram analysis, which takes into account the word order, and semantic networks, which consider the relation between different words. These findings suggest that the model collapse occurs not only by decreasing the content diversity but also by distorting the underlying linguistic patterns of the generated text, which both highlight the critical importance of carefully choosing and curating the initial input text, which can alleviate the model collapse problem. Furthermore, we conduct a qualitative analysis of the fine-tuned models of the pipeline to compare their performances on generic NLP tasks to the original model. We find that autophagy transforms the initial model into a more creative, doubtful and confused one, which might provide inaccurate answers and include conspiracy theories in the model responses, spreading false and biased information on the Web.
A survey on the impact of AI-based recommenders on human behaviours: methodologies, outcomes and future directions
Jun 29, 2024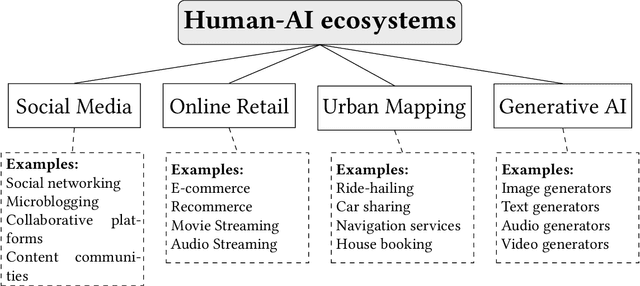
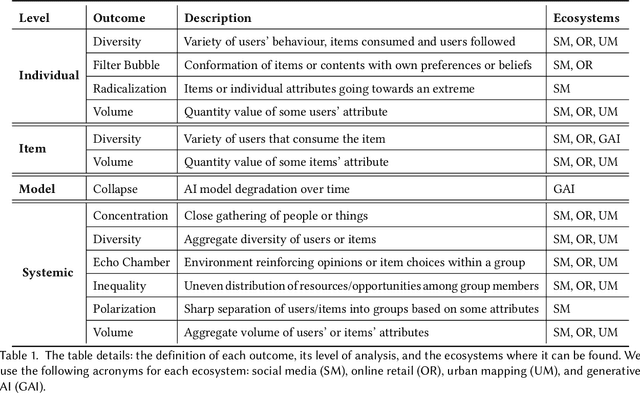
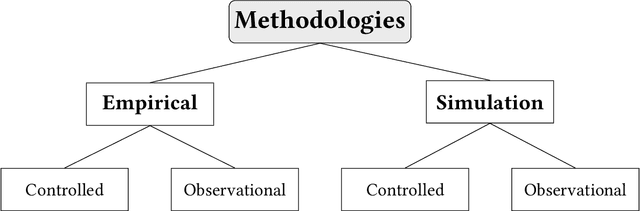
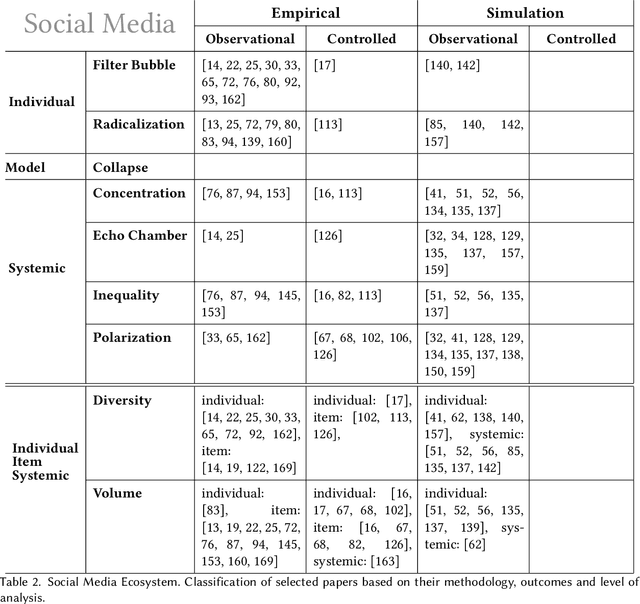
Recommendation systems and assistants (in short, recommenders) are ubiquitous in online platforms and influence most actions of our day-to-day lives, suggesting items or providing solutions based on users' preferences or requests. This survey analyses the impact of recommenders in four human-AI ecosystems: social media, online retail, urban mapping and generative AI ecosystems. Its scope is to systematise a fast-growing field in which terminologies employed to classify methodologies and outcomes are fragmented and unsystematic. We follow the customary steps of qualitative systematic review, gathering 144 articles from different disciplines to develop a parsimonious taxonomy of: methodologies employed (empirical, simulation, observational, controlled), outcomes observed (concentration, model collapse, diversity, echo chamber, filter bubble, inequality, polarisation, radicalisation, volume), and their level of analysis (individual, item, model, and systemic). We systematically discuss all findings of our survey substantively and methodologically, highlighting also potential avenues for future research. This survey is addressed to scholars and practitioners interested in different human-AI ecosystems, policymakers and institutional stakeholders who want to understand better the measurable outcomes of recommenders, and tech companies who wish to obtain a systematic view of the impact of their recommenders.
Social AI and the Challenges of the Human-AI Ecosystem
Jun 23, 2023


The rise of large-scale socio-technical systems in which humans interact with artificial intelligence (AI) systems (including assistants and recommenders, in short AIs) multiplies the opportunity for the emergence of collective phenomena and tipping points, with unexpected, possibly unintended, consequences. For example, navigation systems' suggestions may create chaos if too many drivers are directed on the same route, and personalised recommendations on social media may amplify polarisation, filter bubbles, and radicalisation. On the other hand, we may learn how to foster the "wisdom of crowds" and collective action effects to face social and environmental challenges. In order to understand the impact of AI on socio-technical systems and design next-generation AIs that team with humans to help overcome societal problems rather than exacerbate them, we propose to build the foundations of Social AI at the intersection of Complex Systems, Network Science and AI. In this perspective paper, we discuss the main open questions in Social AI, outlining possible technical and scientific challenges and suggesting research avenues.
Enhancing crowd flow prediction in various spatial and temporal granularities
Mar 12, 2022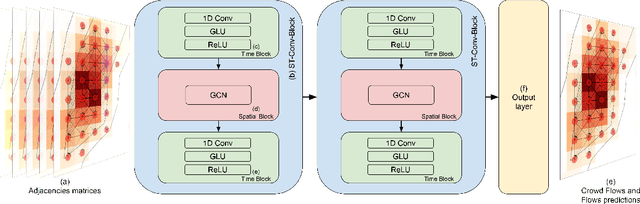
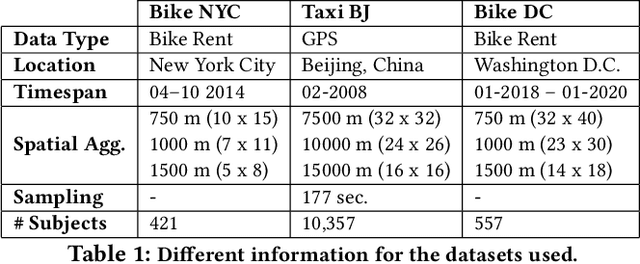
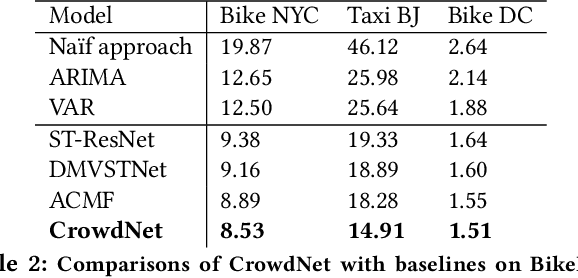
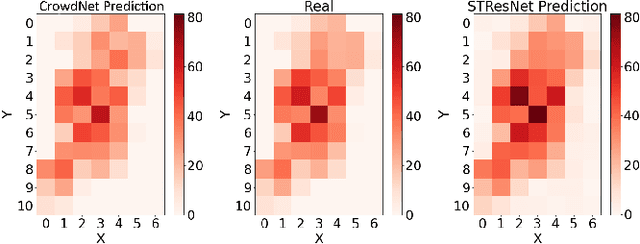
Thanks to the diffusion of the Internet of Things, nowadays it is possible to sense human mobility almost in real time using unconventional methods (e.g., number of bikes in a bike station). Due to the diffusion of such technologies, the last years have witnessed a significant growth of human mobility studies, motivated by their importance in a wide range of applications, from traffic management to public security and computational epidemiology. A mobility task that is becoming prominent is crowd flow prediction, i.e., forecasting aggregated incoming and outgoing flows in the locations of a geographic region. Although several deep learning approaches have been proposed to solve this problem, their usage is limited to specific types of spatial tessellations and cannot provide sufficient explanations of their predictions. We propose CrowdNet, a solution to crowd flow prediction based on graph convolutional networks. Compared with state-of-the-art solutions, CrowdNet can be used with regions of irregular shapes and provide meaningful explanations of the predicted crowd flows. We conduct experiments on public data varying the spatio-temporal granularity of crowd flows to show the superiority of our model with respect to existing methods, and we investigate CrowdNet's reliability to missing or noisy input data. Our model is a step forward in the design of reliable deep learning models to predict and explain human displacements in urban environments.
Trajectory Test-Train Overlap in Next-Location Prediction Datasets
Mar 07, 2022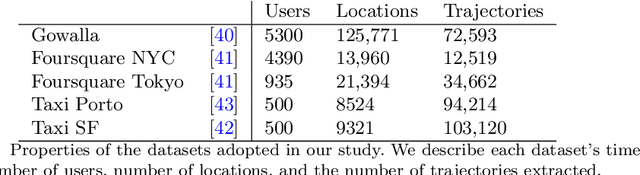
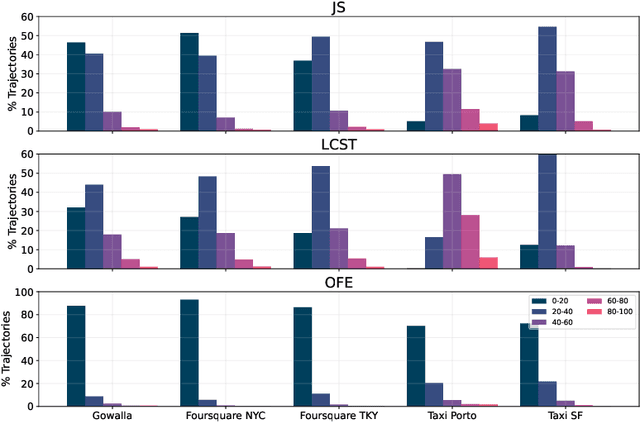
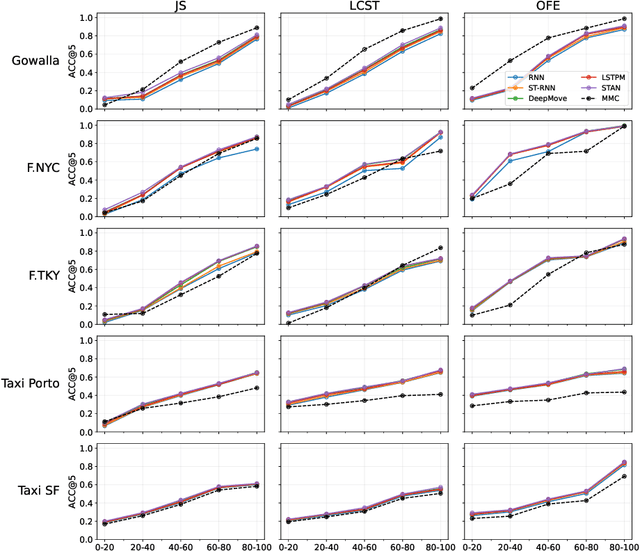
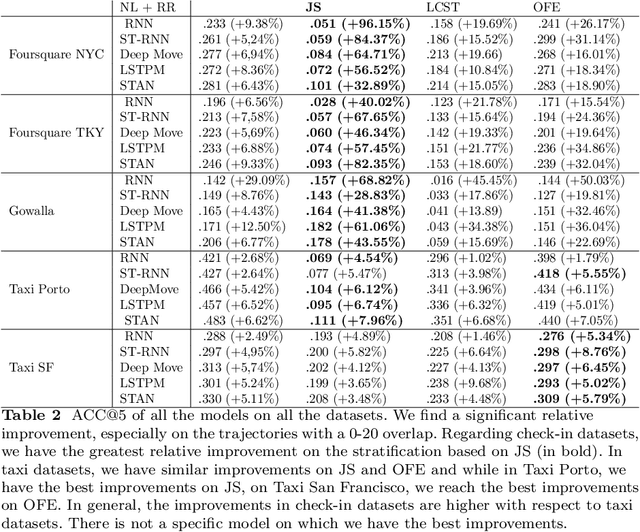
Next-location prediction, consisting of forecasting a user's location given their historical trajectories, has important implications in several fields, such as urban planning, geo-marketing, and disease spreading. Several predictors have been proposed in the last few years to address it, including last-generation ones based on deep learning. This paper tests the generalization capability of these predictors on public mobility datasets, stratifying the datasets by whether the trajectories in the test set also appear fully or partially in the training set. We consistently discover a severe problem of trajectory overlapping in all analyzed datasets, highlighting that predictors memorize trajectories while having limited generalization capacities. We thus propose a methodology to rerank the outputs of the next-location predictors based on spatial mobility patterns. With these techniques, we significantly improve the predictors' generalization capability, with a relative improvement on the accuracy up to 96.15% on the trajectories that cannot be memorized (i.e., low overlap with the training set).
Generating Synthetic Mobility Networks with Generative Adversarial Networks
Feb 22, 2022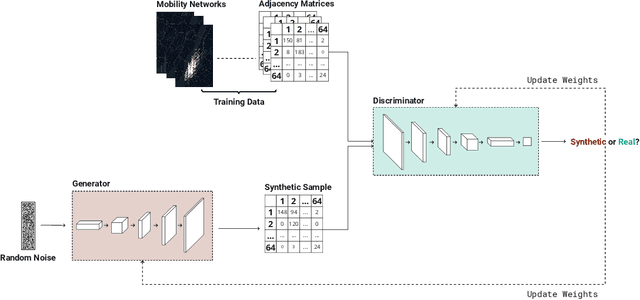
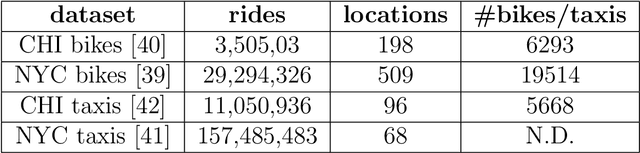
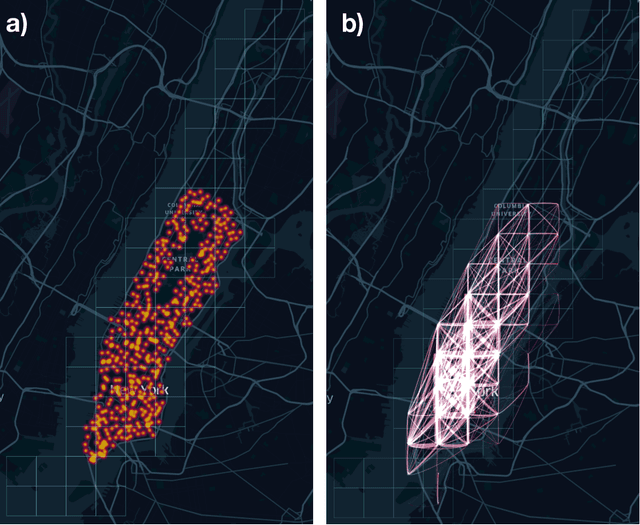
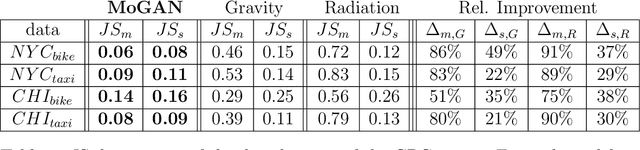
The increasingly crucial role of human displacements in complex societal phenomena, such as traffic congestion, segregation, and the diffusion of epidemics, is attracting the interest of scientists from several disciplines. In this article, we address mobility network generation, i.e., generating a city's entire mobility network, a weighted directed graph in which nodes are geographic locations and weighted edges represent people's movements between those locations, thus describing the entire mobility set flows within a city. Our solution is MoGAN, a model based on Generative Adversarial Networks (GANs) to generate realistic mobility networks. We conduct extensive experiments on public datasets of bike and taxi rides to show that MoGAN outperforms the classical Gravity and Radiation models regarding the realism of the generated networks. Our model can be used for data augmentation and performing simulations and what-if analysis.