 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Explaining Behavioral Shifts in Large Language Models Requires a Comparative Approach
Feb 02, 2026Large-scale foundation models exhibit behavioral shifts: intervention-induced behavioral changes that appear after scaling, fine-tuning, reinforcement learning or in-context learning. While investigating these phenomena have recently received attention, explaining their appearance is still overlooked. Classic explainable AI (XAI) methods can surface failures at a single checkpoint of a model, but they are structurally ill-suited to justify what changed internally across different checkpoints and which explanatory claims are warranted about that change. We take the position that behavioral shifts should be explained comparatively: the core target should be the intervention-induced shift between a reference model and an intervened model, rather than any single model in isolation. To this aim we formulate a Comparative XAI ($Δ$-XAI) framework with a set of desiderata to be taken into account when designing proper explaining methods. To highlight how $Δ$-XAI methods work, we introduce a set of possible pipelines, relate them to the desiderata, and provide a concrete $Δ$-XAI experiment.
Bridging the Gap: In-Context Learning for Modeling Human Disagreement
Jun 06, 2025Large Language Models (LLMs) have shown strong performance on NLP classification tasks. However, they typically rely on aggregated labels-often via majority voting-which can obscure the human disagreement inherent in subjective annotations. This study examines whether LLMs can capture multiple perspectives and reflect annotator disagreement in subjective tasks such as hate speech and offensive language detection. We use in-context learning (ICL) in zero-shot and few-shot settings, evaluating four open-source LLMs across three label modeling strategies: aggregated hard labels, and disaggregated hard and soft labels. In few-shot prompting, we assess demonstration selection methods based on textual similarity (BM25, PLM-based), annotation disagreement (entropy), a combined ranking, and example ordering strategies (random vs. curriculum-based). Results show that multi-perspective generation is viable in zero-shot settings, while few-shot setups often fail to capture the full spectrum of human judgments. Prompt design and demonstration selection notably affect performance, though example ordering has limited impact. These findings highlight the challenges of modeling subjectivity with LLMs and the importance of building more perspective-aware, socially intelligent models.
Explanations Go Linear: Interpretable and Individual Latent Encoding for Post-hoc Explainability
Apr 29, 2025



Post-hoc explainability is essential for understanding black-box machine learning models. Surrogate-based techniques are widely used for local and global model-agnostic explanations but have significant limitations. Local surrogates capture non-linearities but are computationally expensive and sensitive to parameters, while global surrogates are more efficient but struggle with complex local behaviors. In this paper, we present ILLUME, a flexible and interpretable framework grounded in representation learning, that can be integrated with various surrogate models to provide explanations for any black-box classifier. Specifically, our approach combines a globally trained surrogate with instance-specific linear transformations learned with a meta-encoder to generate both local and global explanations. Through extensive empirical evaluations, we demonstrate the effectiveness of ILLUME in producing feature attributions and decision rules that are not only accurate but also robust and faithful to the black-box, thus providing a unified explanation framework that effectively addresses the limitations of traditional surrogate methods.
Interpretable and Fair Mechanisms for Abstaining Classifiers
Mar 24, 2025Abstaining classifiers have the option to refrain from providing a prediction for instances that are difficult to classify. The abstention mechanism is designed to trade off the classifier's performance on the accepted data while ensuring a minimum number of predictions. In this setting, often fairness concerns arise when the abstention mechanism solely reduces errors for the majority groups of the data, resulting in increased performance differences across demographic groups. While there exist a bunch of methods that aim to reduce discrimination when abstaining, there is no mechanism that can do so in an explainable way. In this paper, we fill this gap by introducing Interpretable and Fair Abstaining Classifier IFAC, an algorithm that can reject predictions both based on their uncertainty and their unfairness. By rejecting possibly unfair predictions, our method reduces error and positive decision rate differences across demographic groups of the non-rejected data. Since the unfairness-based rejections are based on an interpretable-by-design method, i.e., rule-based fairness checks and situation testing, we create a transparent process that can empower human decision-makers to review the unfair predictions and make more just decisions for them. This explainable aspect is especially important in light of recent AI regulations, mandating that any high-risk decision task should be overseen by human experts to reduce discrimination risks.
Deferring Concept Bottleneck Models: Learning to Defer Interventions to Inaccurate Experts
Mar 20, 2025Concept Bottleneck Models (CBMs) are machine learning models that improve interpretability by grounding their predictions on human-understandable concepts, allowing for targeted interventions in their decision-making process. However, when intervened on, CBMs assume the availability of humans that can identify the need to intervene and always provide correct interventions. Both assumptions are unrealistic and impractical, considering labor costs and human error-proneness. In contrast, Learning to Defer (L2D) extends supervised learning by allowing machine learning models to identify cases where a human is more likely to be correct than the model, thus leading to deferring systems with improved performance. In this work, we gain inspiration from L2D and propose Deferring CBMs (DCBMs), a novel framework that allows CBMs to learn when an intervention is needed. To this end, we model DCBMs as a composition of deferring systems and derive a consistent L2D loss to train them. Moreover, by relying on a CBM architecture, DCBMs can explain why defer occurs on the final task. Our results show that DCBMs achieve high predictive performance and interpretability at the cost of deferring more to humans.
Mathematical Foundation of Interpretable Equivariant Surrogate Models
Mar 03, 2025This paper introduces a rigorous mathematical framework for neural network explainability, and more broadly for the explainability of equivariant operators called Group Equivariant Operators (GEOs) based on Group Equivariant Non-Expansive Operators (GENEOs) transformations. The central concept involves quantifying the distance between GEOs by measuring the non-commutativity of specific diagrams. Additionally, the paper proposes a definition of interpretability of GEOs according to a complexity measure that can be defined according to each user preferences. Moreover, we explore the formal properties of this framework and show how it can be applied in classical machine learning scenarios, like image classification with convolutional neural networks.
Multi-Perspective Stance Detection
Nov 13, 2024

Subjective NLP tasks usually rely on human annotations provided by multiple annotators, whose judgments may vary due to their diverse backgrounds and life experiences. Traditional methods often aggregate multiple annotations into a single ground truth, disregarding the diversity in perspectives that arises from annotator disagreement. In this preliminary study, we examine the effect of including multiple annotations on model accuracy in classification. Our methodology investigates the performance of perspective-aware classification models in stance detection task and further inspects if annotator disagreement affects the model confidence. The results show that multi-perspective approach yields better classification performance outperforming the baseline which uses the single label. This entails that designing more inclusive perspective-aware AI models is not only an essential first step in implementing responsible and ethical AI, but it can also achieve superior results than using the traditional approaches.
A linguistic analysis of undesirable outcomes in the era of generative AI
Oct 16, 2024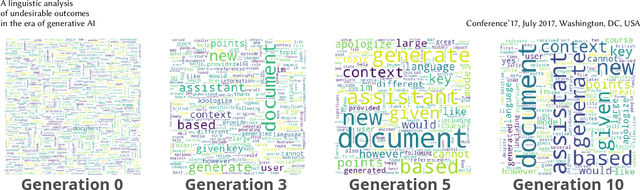
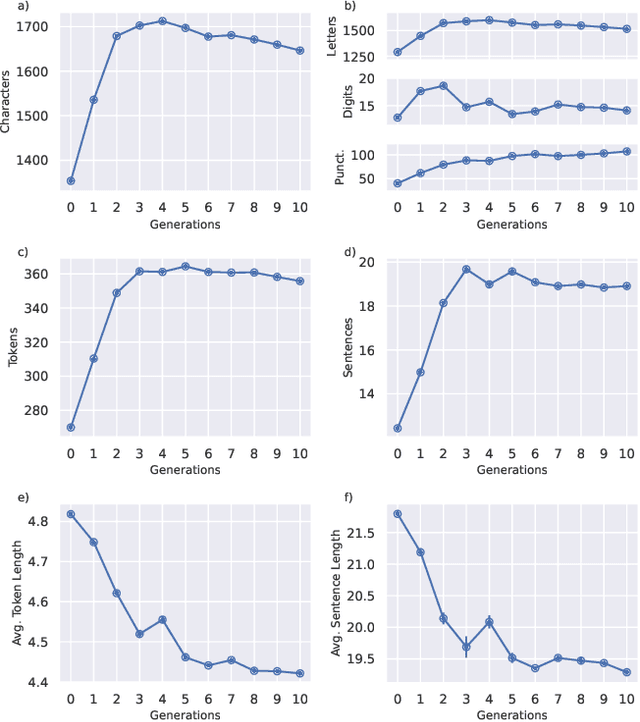
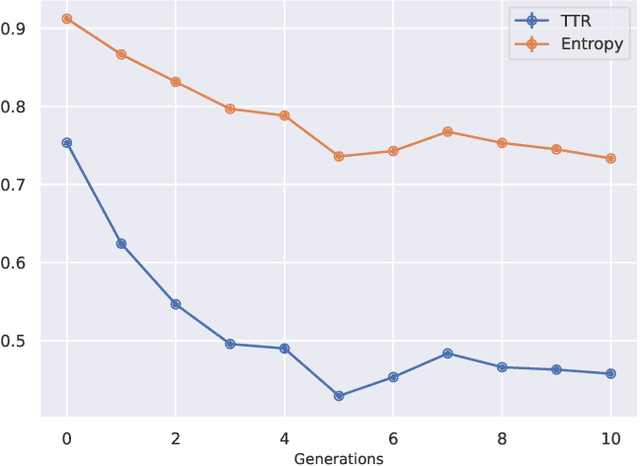
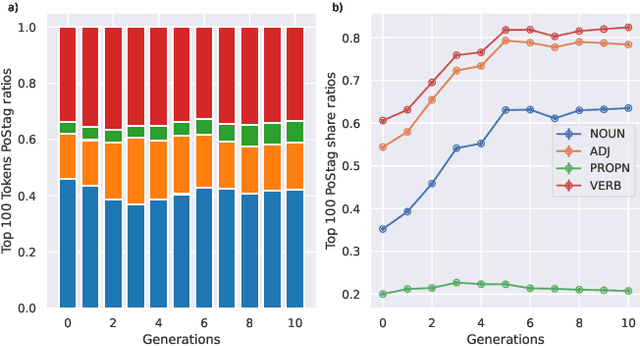
Recent research has focused on the medium and long-term impacts of generative AI, posing scientific and societal challenges mainly due to the detection and reliability of machine-generated information, which is projected to form the major content on the Web soon. Prior studies show that LLMs exhibit a lower performance in generation tasks (model collapse) as they undergo a fine-tuning process across multiple generations on their own generated content (self-consuming loop). In this paper, we present a comprehensive simulation framework built upon the chat version of LLama2, focusing particularly on the linguistic aspects of the generated content, which has not been fully examined in existing studies. Our results show that the model produces less lexical rich content across generations, reducing diversity. The lexical richness has been measured using the linguistic measures of entropy and TTR as well as calculating the POSTags frequency. The generated content has also been examined with an $n$-gram analysis, which takes into account the word order, and semantic networks, which consider the relation between different words. These findings suggest that the model collapse occurs not only by decreasing the content diversity but also by distorting the underlying linguistic patterns of the generated text, which both highlight the critical importance of carefully choosing and curating the initial input text, which can alleviate the model collapse problem. Furthermore, we conduct a qualitative analysis of the fine-tuned models of the pipeline to compare their performances on generic NLP tasks to the original model. We find that autophagy transforms the initial model into a more creative, doubtful and confused one, which might provide inaccurate answers and include conspiracy theories in the model responses, spreading false and biased information on the Web.
A survey on the impact of AI-based recommenders on human behaviours: methodologies, outcomes and future directions
Jun 29, 2024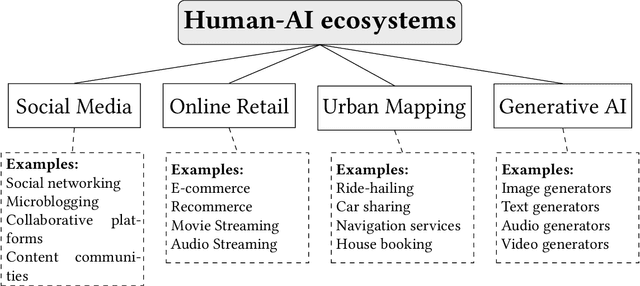
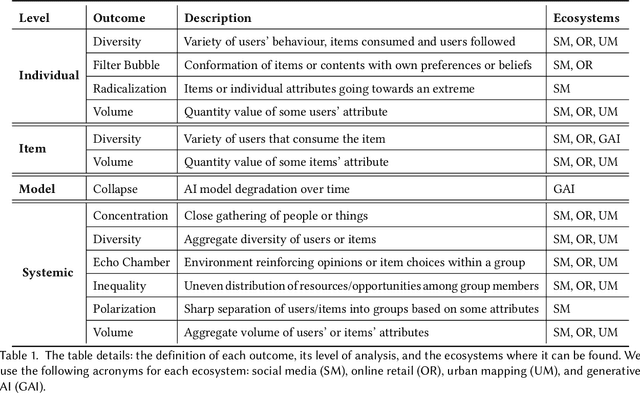
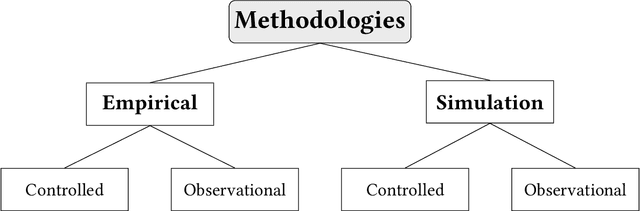
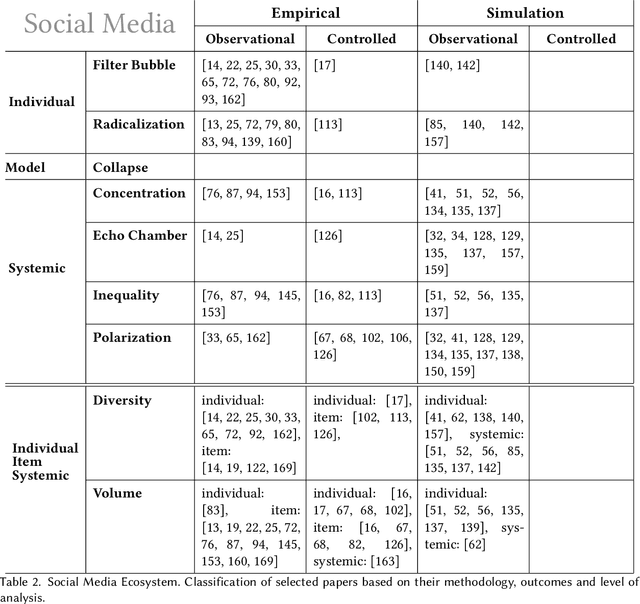
Recommendation systems and assistants (in short, recommenders) are ubiquitous in online platforms and influence most actions of our day-to-day lives, suggesting items or providing solutions based on users' preferences or requests. This survey analyses the impact of recommenders in four human-AI ecosystems: social media, online retail, urban mapping and generative AI ecosystems. Its scope is to systematise a fast-growing field in which terminologies employed to classify methodologies and outcomes are fragmented and unsystematic. We follow the customary steps of qualitative systematic review, gathering 144 articles from different disciplines to develop a parsimonious taxonomy of: methodologies employed (empirical, simulation, observational, controlled), outcomes observed (concentration, model collapse, diversity, echo chamber, filter bubble, inequality, polarisation, radicalisation, volume), and their level of analysis (individual, item, model, and systemic). We systematically discuss all findings of our survey substantively and methodologically, highlighting also potential avenues for future research. This survey is addressed to scholars and practitioners interested in different human-AI ecosystems, policymakers and institutional stakeholders who want to understand better the measurable outcomes of recommenders, and tech companies who wish to obtain a systematic view of the impact of their recommenders.
AI, Meet Human: Learning Paradigms for Hybrid Decision Making Systems
Feb 09, 2024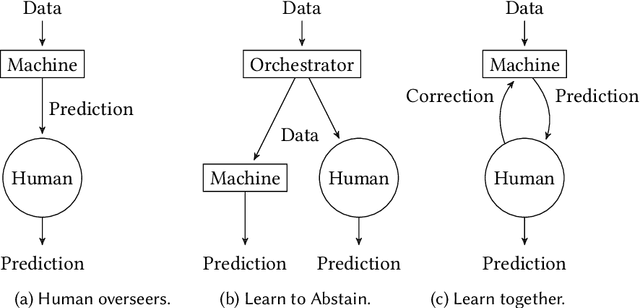



Everyday we increasingly rely on machine learning models to automate and support high-stake tasks and decisions. This growing presence means that humans are now constantly interacting with machine learning-based systems, training and using models everyday. Several different techniques in computer science literature account for the human interaction with machine learning systems, but their classification is sparse and the goals varied. This survey proposes a taxonomy of Hybrid Decision Making Systems, providing both a conceptual and technical framework for understanding how current computer science literature models interaction between humans and machines.