 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigging Deeper: Learning Multi-Level Concept Hierarchies
Mar 10, 2026Although concept-based models promise interpretability by explaining predictions with human-understandable concepts, they typically rely on exhaustive annotations and treat concepts as flat and independent. To circumvent this, recent work has introduced Hierarchical Concept Embedding Models (HiCEMs) to explicitly model concept relationships, and Concept Splitting to discover sub-concepts using only coarse annotations. However, both HiCEMs and Concept Splitting are restricted to shallow hierarchies. We overcome this limitation with Multi-Level Concept Splitting (MLCS), which discovers multi-level concept hierarchies from only top-level supervision, and Deep-HiCEMs, an architecture that represents these discovered hierarchies and enables interventions at multiple levels of abstraction. Experiments across multiple datasets show that MLCS discovers human-interpretable concepts absent during training and that Deep-HiCEMs maintain high accuracy while supporting test-time concept interventions that can improve task performance.
Hierarchical Concept-based Interpretable Models
Feb 27, 2026Modern deep neural networks remain challenging to interpret due to the opacity of their latent representations, impeding model understanding, debugging, and debiasing. Concept Embedding Models (CEMs) address this by mapping inputs to human-interpretable concept representations from which tasks can be predicted. Yet, CEMs fail to represent inter-concept relationships and require concept annotations at different granularities during training, limiting their applicability. In this paper, we introduce Hierarchical Concept Embedding Models (HiCEMs), a new family of CEMs that explicitly model concept relationships through hierarchical structures. To enable HiCEMs in real-world settings, we propose Concept Splitting, a method for automatically discovering finer-grained sub-concepts from a pretrained CEM's embedding space without requiring additional annotations. This allows HiCEMs to generate fine-grained explanations from limited concept labels, reducing annotation burdens. Our evaluation across multiple datasets, including a user study and experiments on PseudoKitchens, a newly proposed concept-based dataset of 3D kitchen renders, demonstrates that (1) Concept Splitting discovers human-interpretable sub-concepts absent during training that can be used to train highly accurate HiCEMs, and (2) HiCEMs enable powerful test-time concept interventions at different granularities, leading to improved task accuracy.
Mixture of Concept Bottleneck Experts
Feb 02, 2026Concept Bottleneck Models (CBMs) promote interpretability by grounding predictions in human-understandable concepts. However, existing CBMs typically fix their task predictor to a single linear or Boolean expression, limiting both predictive accuracy and adaptability to diverse user needs. We propose Mixture of Concept Bottleneck Experts (M-CBEs), a framework that generalizes existing CBMs along two dimensions: the number of experts and the functional form of each expert, exposing an underexplored region of the design space. We investigate this region by instantiating two novel models: Linear M-CBE, which learns a finite set of linear expressions, and Symbolic M-CBE, which leverages symbolic regression to discover expert functions from data under user-specified operator vocabularies. Empirical evaluation demonstrates that varying the mixture size and functional form provides a robust framework for navigating the accuracy-interpretability trade-off, adapting to different user and task needs.
Actionable Interpretability Must Be Defined in Terms of Symmetries
Jan 19, 2026This paper argues that interpretability research in Artificial Intelligence is fundamentally ill-posed as existing definitions of interpretability are not *actionable*: they fail to provide formal principles from which concrete modelling and inferential rules can be derived. We posit that for a definition of interpretability to be actionable, it must be given in terms of *symmetries*. We hypothesise that four symmetries suffice to (i) motivate core interpretability properties, (ii) characterize the class of interpretable models, and (iii) derive a unified formulation of interpretable inference (e.g., alignment, interventions, and counterfactuals) as a form of Bayesian inversion.
Addressing Concept Mislabeling in Concept Bottleneck Models Through Preference Optimization
Apr 25, 2025Concept Bottleneck Models (CBMs) propose to enhance the trustworthiness of AI systems by constraining their decisions on a set of human understandable concepts. However, CBMs typically assume that datasets contains accurate concept labels an assumption often violated in practice, which we show can significantly degrade performance (by 25% in some cases). To address this, we introduce the Concept Preference Optimization (CPO) objective, a new loss function based on Direct Preference Optimization, which effectively mitigates the negative impact of concept mislabeling on CBM performance. We provide an analysis on some key properties of the CPO objective showing it directly optimizes for the concept's posterior distribution, and contrast it against Binary Cross Entropy (BCE) where we show CPO is inherently less sensitive to concept noise. We empirically confirm our analysis finding that CPO consistently outperforms BCE in three real world datasets with and without added label noise.
Avoiding Leakage Poisoning: Concept Interventions Under Distribution Shifts
Apr 24, 2025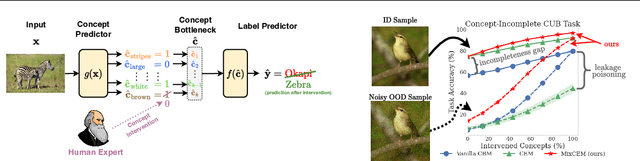
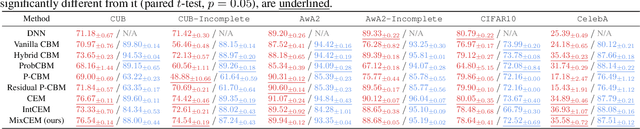
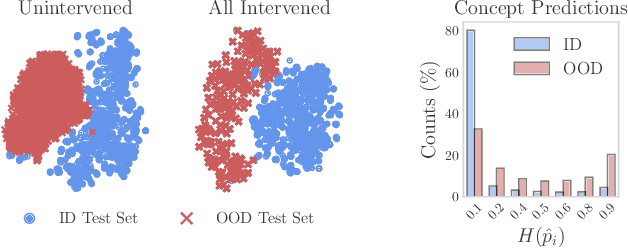

In this paper, we investigate how concept-based models (CMs) respond to out-of-distribution (OOD) inputs. CMs are interpretable neural architectures that first predict a set of high-level concepts (e.g., stripes, black) and then predict a task label from those concepts. In particular, we study the impact of concept interventions (i.e., operations where a human expert corrects a CM's mispredicted concepts at test time) on CMs' task predictions when inputs are OOD. Our analysis reveals a weakness in current state-of-the-art CMs, which we term leakage poisoning, that prevents them from properly improving their accuracy when intervened on for OOD inputs. To address this, we introduce MixCEM, a new CM that learns to dynamically exploit leaked information missing from its concepts only when this information is in-distribution. Our results across tasks with and without complete sets of concept annotations demonstrate that MixCEMs outperform strong baselines by significantly improving their accuracy for both in-distribution and OOD samples in the presence and absence of concept interventions.
Deferring Concept Bottleneck Models: Learning to Defer Interventions to Inaccurate Experts
Mar 20, 2025Concept Bottleneck Models (CBMs) are machine learning models that improve interpretability by grounding their predictions on human-understandable concepts, allowing for targeted interventions in their decision-making process. However, when intervened on, CBMs assume the availability of humans that can identify the need to intervene and always provide correct interventions. Both assumptions are unrealistic and impractical, considering labor costs and human error-proneness. In contrast, Learning to Defer (L2D) extends supervised learning by allowing machine learning models to identify cases where a human is more likely to be correct than the model, thus leading to deferring systems with improved performance. In this work, we gain inspiration from L2D and propose Deferring CBMs (DCBMs), a novel framework that allows CBMs to learn when an intervention is needed. To this end, we model DCBMs as a composition of deferring systems and derive a consistent L2D loss to train them. Moreover, by relying on a CBM architecture, DCBMs can explain why defer occurs on the final task. Our results show that DCBMs achieve high predictive performance and interpretability at the cost of deferring more to humans.
Neural Interpretable Reasoning
Feb 17, 2025

We formalize a novel modeling framework for achieving interpretability in deep learning, anchored in the principle of inference equivariance. While the direct verification of interpretability scales exponentially with the number of variables of the system, we show that this complexity can be mitigated by treating interpretability as a Markovian property and employing neural re-parametrization techniques. Building on these insights, we propose a new modeling paradigm -- neural generation and interpretable execution -- that enables scalable verification of equivariance. This paradigm provides a general approach for designing Neural Interpretable Reasoners that are not only expressive but also transparent.
Efficient Bias Mitigation Without Privileged Information
Sep 26, 2024Deep neural networks trained via empirical risk minimisation often exhibit significant performance disparities across groups, particularly when group and task labels are spuriously correlated (e.g., "grassy background" and "cows"). Existing bias mitigation methods that aim to address this issue often either rely on group labels for training or validation, or require an extensive hyperparameter search. Such data and computational requirements hinder the practical deployment of these methods, especially when datasets are too large to be group-annotated, computational resources are limited, and models are trained through already complex pipelines. In this paper, we propose Targeted Augmentations for Bias Mitigation (TAB), a simple hyperparameter-free framework that leverages the entire training history of a helper model to identify spurious samples, and generate a group-balanced training set from which a robust model can be trained. We show that TAB improves worst-group performance without any group information or model selection, outperforming existing methods while maintaining overall accuracy.
Causal Concept Embedding Models: Beyond Causal Opacity in Deep Learning
May 28, 2024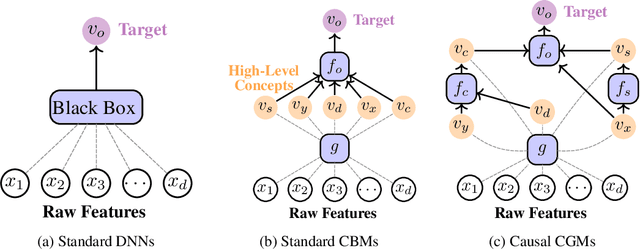



Causal opacity denotes the difficulty in understanding the "hidden" causal structure underlying a deep neural network's (DNN) reasoning. This leads to the inability to rely on and verify state-of-the-art DNN-based systems especially in high-stakes scenarios. For this reason, causal opacity represents a key open challenge at the intersection of deep learning, interpretability, and causality. This work addresses this gap by introducing Causal Concept Embedding Models (Causal CEMs), a class of interpretable models whose decision-making process is causally transparent by design. The results of our experiments show that Causal CEMs can: (i) match the generalization performance of causally-opaque models, (ii) support the analysis of interventional and counterfactual scenarios, thereby improving the model's causal interpretability and supporting the effective verification of its reliability and fairness, and (iii) enable human-in-the-loop corrections to mispredicted intermediate reasoning steps, boosting not just downstream accuracy after corrections but also accuracy of the explanation provided for a specific instance.