 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models in Peer-Run Community Behavioral Health Services: Understanding Peer Specialists and Service Users' Perspectives on Opportunities, Risks, and Mitigation Strategies
Feb 09, 2026Peer-run organizations (PROs) provide critical, recovery-based behavioral health support rooted in lived experience. As large language models (LLMs) enter this domain, their scale, conversationality, and opacity introduce new challenges for situatedness, trust, and autonomy. Partnering with Collaborative Support Programs of New Jersey (CSPNJ), a statewide PRO in the Northeastern United States, we used comicboarding, a co-design method, to conduct workshops with 16 peer specialists and 10 service users exploring perceptions of integrating an LLM-based recommendation system into peer support. Findings show that depending on how LLMs are introduced, constrained, and co-used, they can reconfigure in-room dynamics by sustaining, undermining, or amplifying the relational authority that grounds peer support. We identify opportunities, risks, and mitigation strategies across three tensions: bridging scale and locality, protecting trust and relational dynamics, and preserving peer autonomy amid efficiency gains. We contribute design implications that center lived-experience-in-the-loop, reframe trust as co-constructed, and position LLMs not as clinical tools but as relational collaborators in high-stakes, community-led care.
RescueLens: LLM-Powered Triage and Action on Volunteer Feedback for Food Rescue
Nov 19, 2025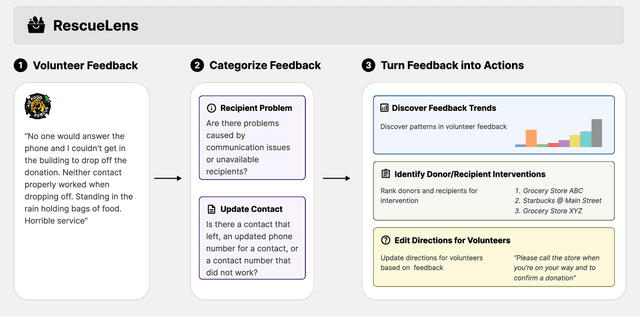
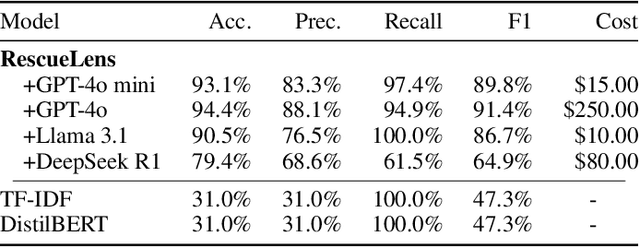
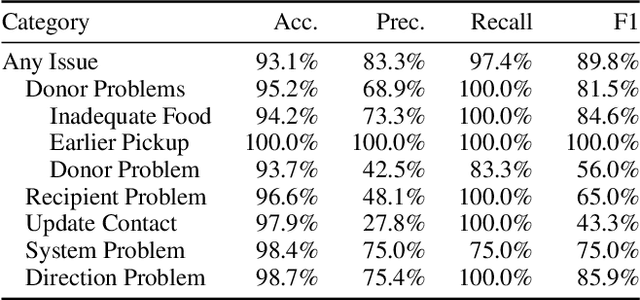
Food rescue organizations simultaneously tackle food insecurity and waste by working with volunteers to redistribute food from donors who have excess to recipients who need it. Volunteer feedback allows food rescue organizations to identify issues early and ensure volunteer satisfaction. However, food rescue organizations monitor feedback manually, which can be cumbersome and labor-intensive, making it difficult to prioritize which issues are most important. In this work, we investigate how large language models (LLMs) assist food rescue organizers in understanding and taking action based on volunteer experiences. We work with 412 Food Rescue, a large food rescue organization based in Pittsburgh, Pennsylvania, to design RescueLens, an LLM-powered tool that automatically categorizes volunteer feedback, suggests donors and recipients to follow up with, and updates volunteer directions based on feedback. We evaluate the performance of RescueLens on an annotated dataset, and show that it can recover 96% of volunteer issues at 71% precision. Moreover, by ranking donors and recipients according to their rates of volunteer issues, RescueLens allows organizers to focus on 0.5% of donors responsible for more than 30% of volunteer issues. RescueLens is now deployed at 412 Food Rescue and through semi-structured interviews with organizers, we find that RescueLens streamlines the feedback process so organizers better allocate their time.
Global Rewards in Restless Multi-Armed Bandits
Jun 02, 2024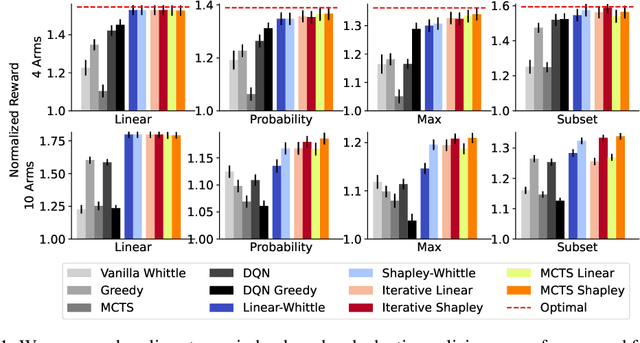
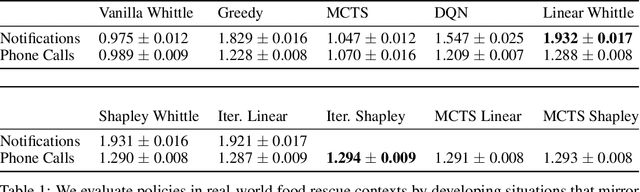
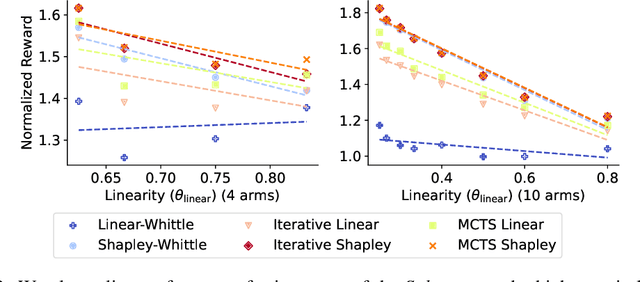
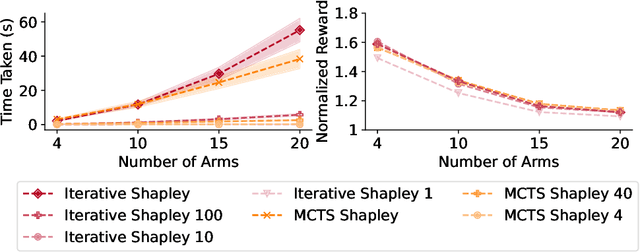
Restless multi-armed bandits (RMAB) extend multi-armed bandits so pulling an arm impacts future states. Despite the success of RMABs, a key limiting assumption is the separability of rewards into a sum across arms. We address this deficiency by proposing restless-multi-armed bandit with global rewards (RMAB-G), a generalization of RMABs to global non-separable rewards. To solve RMAB-G, we develop the Linear- and Shapley-Whittle indices, which extend Whittle indices from RMABs to RMAB-Gs. We prove approximation bounds but also point out how these indices could fail when reward functions are highly non-linear. To overcome this, we propose two sets of adaptive policies: the first computes indices iteratively, and the second combines indices with Monte-Carlo Tree Search (MCTS). Empirically, we demonstrate that our proposed policies outperform baselines and index-based policies with synthetic data and real-world data from food rescue.
Understanding Inter-Concept Relationships in Concept-Based Models
May 28, 2024

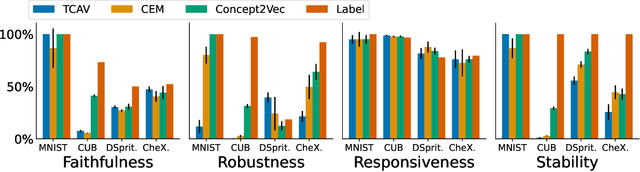
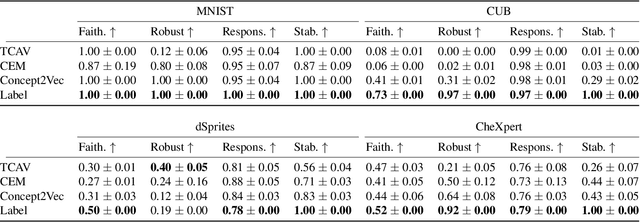
Concept-based explainability methods provide insight into deep learning systems by constructing explanations using human-understandable concepts. While the literature on human reasoning demonstrates that we exploit relationships between concepts when solving tasks, it is unclear whether concept-based methods incorporate the rich structure of inter-concept relationships. We analyse the concept representations learnt by concept-based models to understand whether these models correctly capture inter-concept relationships. First, we empirically demonstrate that state-of-the-art concept-based models produce representations that lack stability and robustness, and such methods fail to capture inter-concept relationships. Then, we develop a novel algorithm which leverages inter-concept relationships to improve concept intervention accuracy, demonstrating how correctly capturing inter-concept relationships can improve downstream tasks.
Do Concept Bottleneck Models Obey Locality?
Jan 02, 2024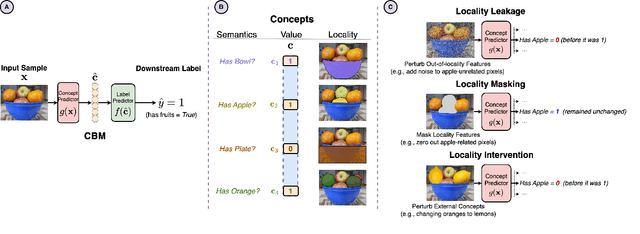
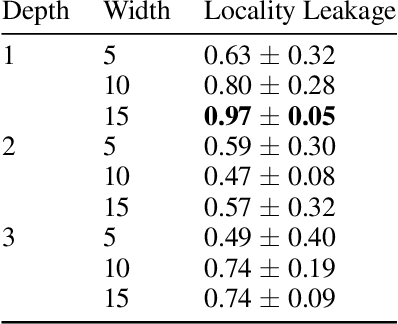
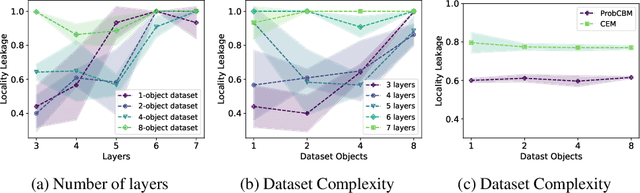
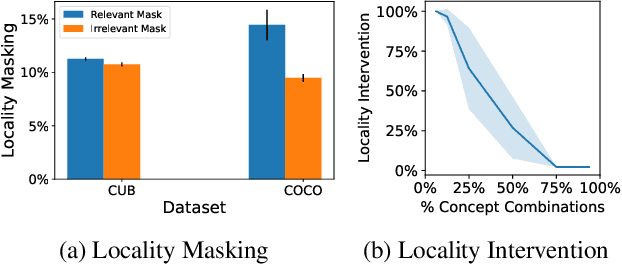
Concept-based learning improves a deep learning model's interpretability by explaining its predictions via human-understandable concepts. Deep learning models trained under this paradigm heavily rely on the assumption that neural networks can learn to predict the presence or absence of a given concept independently of other concepts. Recent work, however, strongly suggests that this assumption may fail to hold in Concept Bottleneck Models (CBMs), a quintessential family of concept-based interpretable architectures. In this paper, we investigate whether CBMs correctly capture the degree of conditional independence across concepts when such concepts are localised both spatially, by having their values entirely defined by a fixed subset of features, and semantically, by having their values correlated with only a fixed subset of predefined concepts. To understand locality, we analyse how changes to features outside of a concept's spatial or semantic locality impact concept predictions. Our results suggest that even in well-defined scenarios where the presence of a concept is localised to a fixed feature subspace, or whose semantics are correlated to a small subset of other concepts, CBMs fail to learn this locality. These results cast doubt upon the quality of concept representations learnt by CBMs and strongly suggest that concept-based explanations may be fragile to changes outside their localities.
Human Uncertainty in Concept-Based AI Systems
Mar 22, 2023Placing a human in the loop may abate the risks of deploying AI systems in safety-critical settings (e.g., a clinician working with a medical AI system). However, mitigating risks arising from human error and uncertainty within such human-AI interactions is an important and understudied issue. In this work, we study human uncertainty in the context of concept-based models, a family of AI systems that enable human feedback via concept interventions where an expert intervenes on human-interpretable concepts relevant to the task. Prior work in this space often assumes that humans are oracles who are always certain and correct. Yet, real-world decision-making by humans is prone to occasional mistakes and uncertainty. We study how existing concept-based models deal with uncertain interventions from humans using two novel datasets: UMNIST, a visual dataset with controlled simulated uncertainty based on the MNIST dataset, and CUB-S, a relabeling of the popular CUB concept dataset with rich, densely-annotated soft labels from humans. We show that training with uncertain concept labels may help mitigate weaknesses of concept-based systems when handling uncertain interventions. These results allow us to identify several open challenges, which we argue can be tackled through future multidisciplinary research on building interactive uncertainty-aware systems. To facilitate further research, we release a new elicitation platform, UElic, to collect uncertain feedback from humans in collaborative prediction tasks.
Improving Learning-to-Defer Algorithms Through Fine-Tuning
Dec 18, 2021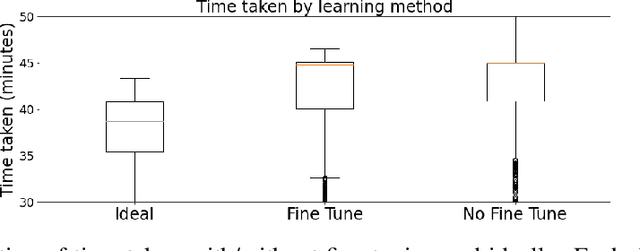
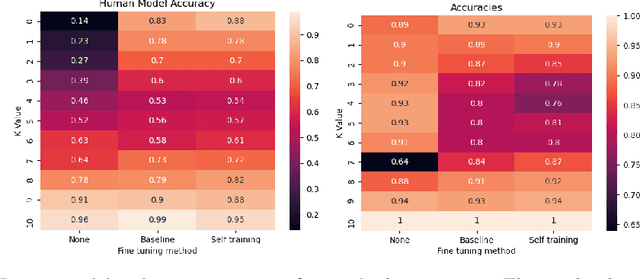
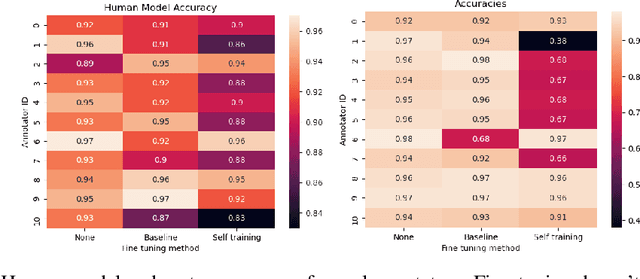
The ubiquity of AI leads to situations where humans and AI work together, creating the need for learning-to-defer algorithms that determine how to partition tasks between AI and humans. We work to improve learning-to-defer algorithms when paired with specific individuals by incorporating two fine-tuning algorithms and testing their efficacy using both synthetic and image datasets. We find that fine-tuning can pick up on simple human skill patterns, but struggles with nuance, and we suggest future work that uses robust semi-supervised to improve learning.
Data-Driven Methods for Balancing Fairness and Efficiency in Ride-Pooling
Oct 07, 2021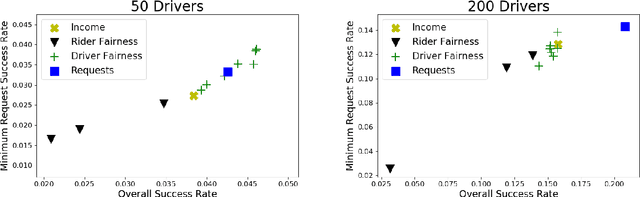
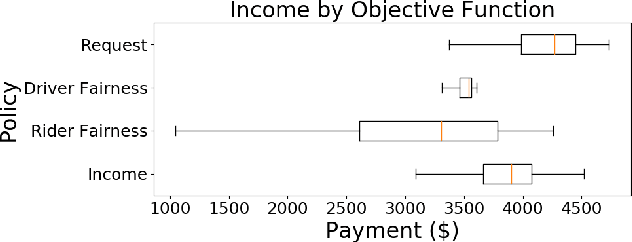
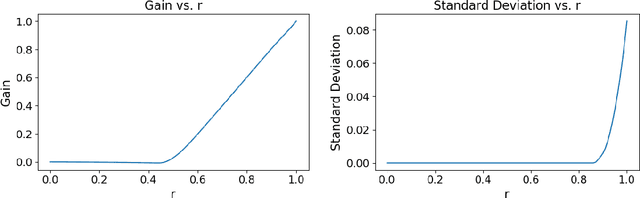
Rideshare and ride-pooling platforms use artificial intelligence-based matching algorithms to pair riders and drivers. However, these platforms can induce inequality either through an unequal income distribution or disparate treatment of riders. We investigate two methods to reduce forms of inequality in ride-pooling platforms: (1) incorporating fairness constraints into the objective function and (2) redistributing income to drivers to reduce income fluctuation and inequality. To evaluate our solutions, we use the New York City taxi data set. For the first method, we find that optimizing for driver-side fairness outperforms state-of-the-art models on the number of riders serviced, both in the worst-off neighborhood and overall, showing that optimizing for fairness can assist profitability in certain circumstances. For the second method, we explore income redistribution as a way to combat income inequality by having drivers keep an $r$ fraction of their income, and contributing the rest to a redistribution pool. For certain values of $r$, most drivers earn near their Shapley value, while still incentivizing drivers to maximize value, thereby avoiding the free-rider problem and reducing income variability. The first method can be extended to many definitions of fairness and the second method provably improves fairness without affecting profitability.