 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaping the Future of Mathematics in the Age of AI
Mar 26, 2026Artificial intelligence is transforming mathematics at a speed and scale that demand active engagement from the mathematical community. We examine five areas where this transformation is particularly pressing: values, practice, teaching, technology, and ethics. We offer recommendations on safeguarding our intellectual autonomy, rethinking our practice, broadening curricula, building academically oriented infrastructure, and developing shared ethical principles - with the aim of ensuring that the future of mathematics is shaped by the community itself.
Digging Deeper: Learning Multi-Level Concept Hierarchies
Mar 10, 2026Although concept-based models promise interpretability by explaining predictions with human-understandable concepts, they typically rely on exhaustive annotations and treat concepts as flat and independent. To circumvent this, recent work has introduced Hierarchical Concept Embedding Models (HiCEMs) to explicitly model concept relationships, and Concept Splitting to discover sub-concepts using only coarse annotations. However, both HiCEMs and Concept Splitting are restricted to shallow hierarchies. We overcome this limitation with Multi-Level Concept Splitting (MLCS), which discovers multi-level concept hierarchies from only top-level supervision, and Deep-HiCEMs, an architecture that represents these discovered hierarchies and enables interventions at multiple levels of abstraction. Experiments across multiple datasets show that MLCS discovers human-interpretable concepts absent during training and that Deep-HiCEMs maintain high accuracy while supporting test-time concept interventions that can improve task performance.
Hierarchical Concept-based Interpretable Models
Feb 27, 2026Modern deep neural networks remain challenging to interpret due to the opacity of their latent representations, impeding model understanding, debugging, and debiasing. Concept Embedding Models (CEMs) address this by mapping inputs to human-interpretable concept representations from which tasks can be predicted. Yet, CEMs fail to represent inter-concept relationships and require concept annotations at different granularities during training, limiting their applicability. In this paper, we introduce Hierarchical Concept Embedding Models (HiCEMs), a new family of CEMs that explicitly model concept relationships through hierarchical structures. To enable HiCEMs in real-world settings, we propose Concept Splitting, a method for automatically discovering finer-grained sub-concepts from a pretrained CEM's embedding space without requiring additional annotations. This allows HiCEMs to generate fine-grained explanations from limited concept labels, reducing annotation burdens. Our evaluation across multiple datasets, including a user study and experiments on PseudoKitchens, a newly proposed concept-based dataset of 3D kitchen renders, demonstrates that (1) Concept Splitting discovers human-interpretable sub-concepts absent during training that can be used to train highly accurate HiCEMs, and (2) HiCEMs enable powerful test-time concept interventions at different granularities, leading to improved task accuracy.
Towards Spatial Transcriptomics-driven Pathology Foundation Models
Feb 15, 2026Spatial transcriptomics (ST) provides spatially resolved measurements of gene expression, enabling characterization of the molecular landscape of human tissue beyond histological assessment as well as localized readouts that can be aligned with morphology. Concurrently, the success of multimodal foundation models that integrate vision with complementary modalities suggests that morphomolecular coupling between local expression and morphology can be systematically used to improve histological representations themselves. We introduce Spatial Expression-Aligned Learning (SEAL), a vision-omics self-supervised learning framework that infuses localized molecular information into pathology vision encoders. Rather than training new encoders from scratch, SEAL is designed as a parameter-efficient vision-omics finetuning method that can be flexibly applied to widely used pathology foundation models. We instantiate SEAL by training on over 700,000 paired gene expression spot-tissue region examples spanning tumor and normal samples from 14 organs. Tested across 38 slide-level and 15 patch-level downstream tasks, SEAL provides a drop-in replacement for pathology foundation models that consistently improves performance over widely used vision-only and ST prediction baselines on slide-level molecular status, pathway activity, and treatment response prediction, as well as patch-level gene expression prediction tasks. Additionally, SEAL encoders exhibit robust domain generalization on out-of-distribution evaluations and enable new cross-modal capabilities such as gene-to-image retrieval. Our work proposes a general framework for ST-guided finetuning of pathology foundation models, showing that augmenting existing models with localized molecular supervision is an effective and practical step for improving visual representations and expanding their cross-modal utility.
Actionable Interpretability Must Be Defined in Terms of Symmetries
Jan 19, 2026This paper argues that interpretability research in Artificial Intelligence is fundamentally ill-posed as existing definitions of interpretability are not *actionable*: they fail to provide formal principles from which concrete modelling and inferential rules can be derived. We posit that for a definition of interpretability to be actionable, it must be given in terms of *symmetries*. We hypothesise that four symmetries suffice to (i) motivate core interpretability properties, (ii) characterize the class of interpretable models, and (iii) derive a unified formulation of interpretable inference (e.g., alignment, interventions, and counterfactuals) as a form of Bayesian inversion.
An AI Monkey Gets Grapes for Sure -- Sphere Neural Networks for Reliable Decision-Making
Jan 01, 2026This paper compares three methodological categories of neural reasoning: LLM reasoning, supervised learning-based reasoning, and explicit model-based reasoning. LLMs remain unreliable and struggle with simple decision-making that animals can master without extensive corpora training. Through disjunctive syllogistic reasoning testing, we show that reasoning via supervised learning is less appealing than reasoning via explicit model construction. Concretely, we show that an Euler Net trained to achieve 100.00% in classic syllogistic reasoning can be trained to reach 100.00% accuracy in disjunctive syllogistic reasoning. However, the retrained Euler Net suffers severely from catastrophic forgetting (its performance drops to 6.25% on already-learned classic syllogistic reasoning), and its reasoning competence is limited to the pattern level. We propose a new version of Sphere Neural Networks that embeds concepts as circles on the surface of an n-dimensional sphere. These Sphere Neural Networks enable the representation of the negation operator via complement circles and achieve reliable decision-making by filtering out illogical statements that form unsatisfiable circular configurations. We demonstrate that the Sphere Neural Network can master 16 syllogistic reasoning tasks, including rigorous disjunctive syllogistic reasoning, while preserving the rigour of classical syllogistic reasoning. We conclude that neural reasoning with explicit model construction is the most reliable among the three methodological categories of neural reasoning.
A Matter of Interest: Understanding Interestingness of Math Problems in Humans and Language Models
Nov 11, 2025The evolution of mathematics has been guided in part by interestingness. From researchers choosing which problems to tackle next, to students deciding which ones to engage with, people's choices are often guided by judgments about how interesting or challenging problems are likely to be. As AI systems, such as LLMs, increasingly participate in mathematics with people -- whether for advanced research or education -- it becomes important to understand how well their judgments align with human ones. Our work examines this alignment through two empirical studies of human and LLM assessment of mathematical interestingness and difficulty, spanning a range of mathematical experience. We study two groups: participants from a crowdsourcing platform and International Math Olympiad competitors. We show that while many LLMs appear to broadly agree with human notions of interestingness, they mostly do not capture the distribution observed in human judgments. Moreover, most LLMs only somewhat align with why humans find certain math problems interesting, showing weak correlation with human-selected interestingness rationales. Together, our findings highlight both the promises and limitations of current LLMs in capturing human interestingness judgments for mathematical AI thought partnerships.
Oruga: An Avatar of Representational Systems Theory
Sep 04, 2025Humans use representations flexibly. We draw diagrams, change representations and exploit creative analogies across different domains. We want to harness this kind of power and endow machines with it to make them more compatible with human use. Previously we developed Representational Systems Theory (RST) to study the structure and transformations of representations. In this paper we present Oruga (caterpillar in Spanish; a symbol of transformation), an implementation of various aspects of RST. Oruga consists of a core of data structures corresponding to concepts in RST, a language for communicating with the core, and an engine for producing transformations using a method we call structure transfer. In this paper we present an overview of the core and language of Oruga, with a brief example of the kind of transformation that structure transfer can execute.
Avoiding Leakage Poisoning: Concept Interventions Under Distribution Shifts
Apr 24, 2025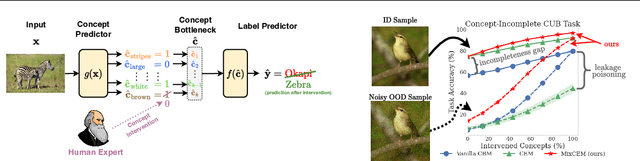
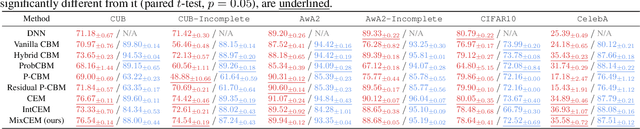
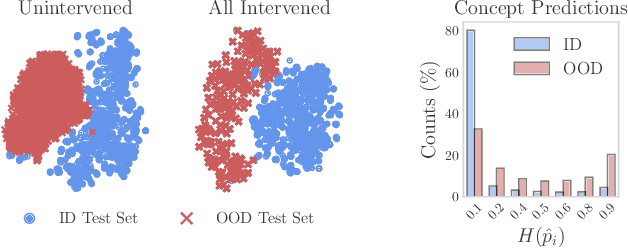

In this paper, we investigate how concept-based models (CMs) respond to out-of-distribution (OOD) inputs. CMs are interpretable neural architectures that first predict a set of high-level concepts (e.g., stripes, black) and then predict a task label from those concepts. In particular, we study the impact of concept interventions (i.e., operations where a human expert corrects a CM's mispredicted concepts at test time) on CMs' task predictions when inputs are OOD. Our analysis reveals a weakness in current state-of-the-art CMs, which we term leakage poisoning, that prevents them from properly improving their accuracy when intervened on for OOD inputs. To address this, we introduce MixCEM, a new CM that learns to dynamically exploit leaked information missing from its concepts only when this information is in-distribution. Our results across tasks with and without complete sets of concept annotations demonstrate that MixCEMs outperform strong baselines by significantly improving their accuracy for both in-distribution and OOD samples in the presence and absence of concept interventions.
RO-FIGS: Efficient and Expressive Tree-Based Ensembles for Tabular Data
Apr 09, 2025
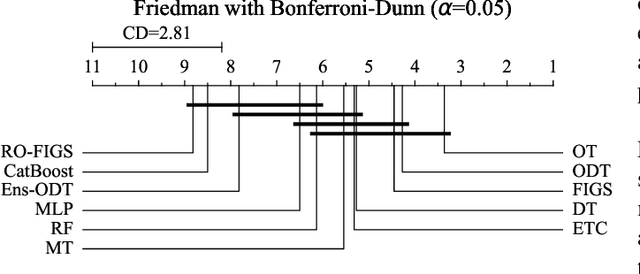
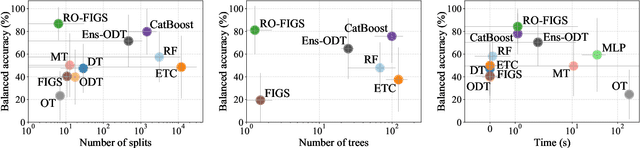
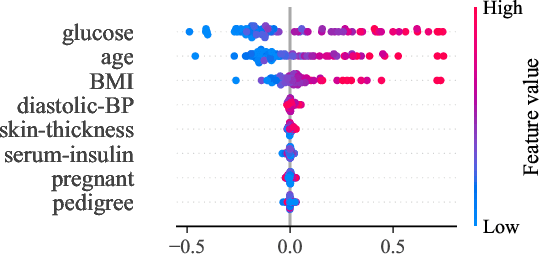
Tree-based models are often robust to uninformative features and can accurately capture non-smooth, complex decision boundaries. Consequently, they often outperform neural network-based models on tabular datasets at a significantly lower computational cost. Nevertheless, the capability of traditional tree-based ensembles to express complex relationships efficiently is limited by using a single feature to make splits. To improve the efficiency and expressiveness of tree-based methods, we propose Random Oblique Fast Interpretable Greedy-Tree Sums (RO-FIGS). RO-FIGS builds on Fast Interpretable Greedy-Tree Sums, and extends it by learning trees with oblique or multivariate splits, where each split consists of a linear combination learnt from random subsets of features. This helps uncover interactions between features and improves performance. The proposed method is suitable for tabular datasets with both numerical and categorical features. We evaluate RO-FIGS on 22 real-world tabular datasets, demonstrating superior performance and much smaller models over other tree- and neural network-based methods. Additionally, we analyse their splits to reveal valuable insights into feature interactions, enriching the information learnt from SHAP summary plots, and thereby demonstrating the enhanced interpretability of RO-FIGS models. The proposed method is well-suited for applications, where balance between accuracy and interpretability is essential.