 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabular Foundation Model for Generative Modelling
May 10, 2026Generative modelling is a demanding test of foundation models, because it requires robust, holistic representation learning for a given data modality, rather than optimisation for a supervised prediction target alone. While recent work on tabular foundation models has achieved remarkable progress in predictive modelling, generative tabular foundation models remain underexplored. Existing tabular foundation generators, in particular, have not yet consistently matched strong dataset-specific generators in synthetic data quality. A key reason is their misalignment with the distinctive causal structural prior of heterogeneous tabular data. In this paper, we address this gap by introducing a novel tabular foundation model, \textbf{TabFORGE}, built on pretrained \textbf{Tab}ular \textbf{FO}undational \textbf{R}epresentations for \textbf{GE}neration. TabFORGE is designed to utilise the implicitly learned causal information underlying diverse tabular datasets in a unified latent space induced by a pretrained causality-aware feature encoder. It further decouples latent modelling from decoding through a two-stage design: we first pretrain a score-based diffusion transformer, and then pretrain a denoising-aligned decoder using the denoised latent embeddings. This design elegantly mitigates the distribution shifts in latent embeddings that typically arise between training and inference. We evaluate TabFORGE comprehensively against 22 benchmark methods on 45 real-world datasets. Our results show that TabFORGE effectively learns and leverages generalisable tabular representations, enabling efficient generation of high-quality synthetic tabular data, particularly with strong structural fidelity.
How Well Does Your Tabular Generator Learn the Structure of Tabular Data?
Mar 12, 2025Heterogeneous tabular data poses unique challenges in generative modelling due to its fundamentally different underlying data structure compared to homogeneous modalities, such as images and text. Although previous research has sought to adapt the successes of generative modelling in homogeneous modalities to the tabular domain, defining an effective generator for tabular data remains an open problem. One major reason is that the evaluation criteria inherited from other modalities often fail to adequately assess whether tabular generative models effectively capture or utilise the unique structural information encoded in tabular data. In this paper, we carefully examine the limitations of the prevailing evaluation framework and introduce $\textbf{TabStruct}$, a novel evaluation benchmark that positions structural fidelity as a core evaluation dimension. Specifically, TabStruct evaluates the alignment of causal structures in real and synthetic data, providing a direct measure of how effectively tabular generative models learn the structure of tabular data. Through extensive experiments using generators from eight categories on seven datasets with expert-validated causal graphical structures, we show that structural fidelity offers a task-independent, domain-agnostic evaluation dimension. Our findings highlight the importance of tabular data structure and offer practical guidance for developing more effective and robust tabular generative models. Code is available at https://github.com/SilenceX12138/TabStruct.
LLM Embeddings for Deep Learning on Tabular Data
Feb 17, 2025Tabular deep-learning methods require embedding numerical and categorical input features into high-dimensional spaces before processing them. Existing methods deal with this heterogeneous nature of tabular data by employing separate type-specific encoding approaches. This limits the cross-table transfer potential and the exploitation of pre-trained knowledge. We propose a novel approach that first transforms tabular data into text, and then leverages pre-trained representations from LLMs to encode this data, resulting in a plug-and-play solution to improv ing deep-learning tabular methods. We demonstrate that our approach improves accuracy over competitive models, such as MLP, ResNet and FT-Transformer, by validating on seven classification datasets.
TabEBM: A Tabular Data Augmentation Method with Distinct Class-Specific Energy-Based Models
Sep 24, 2024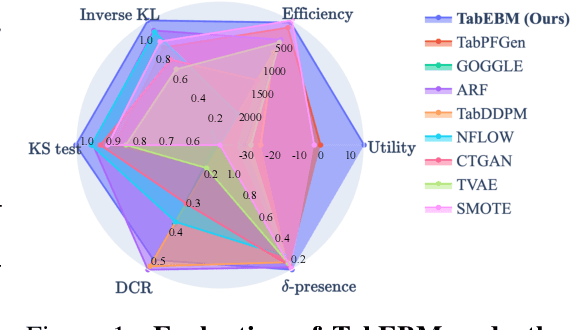
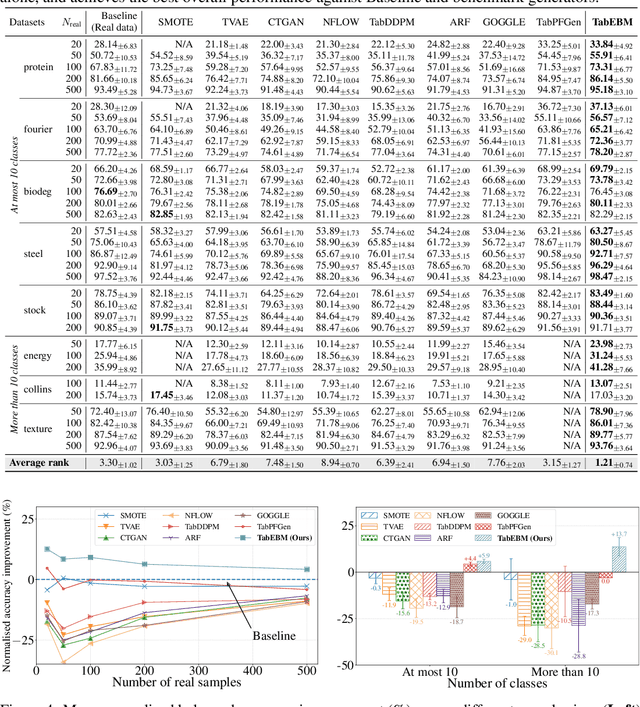
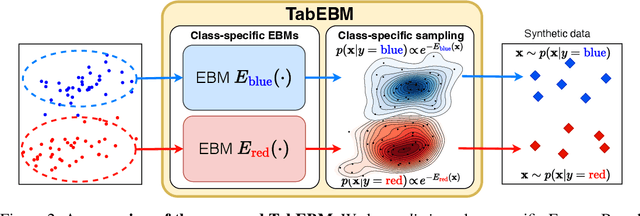
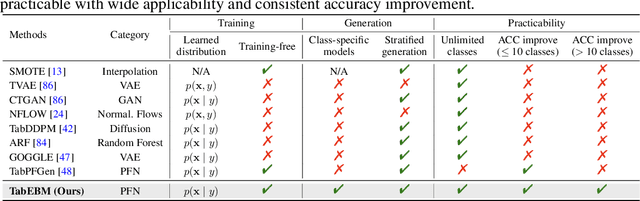
Data collection is often difficult in critical fields such as medicine, physics, and chemistry. As a result, classification methods usually perform poorly with these small datasets, leading to weak predictive performance. Increasing the training set with additional synthetic data, similar to data augmentation in images, is commonly believed to improve downstream classification performance. However, current tabular generative methods that learn either the joint distribution $ p(\mathbf{x}, y) $ or the class-conditional distribution $ p(\mathbf{x} \mid y) $ often overfit on small datasets, resulting in poor-quality synthetic data, usually worsening classification performance compared to using real data alone. To solve these challenges, we introduce TabEBM, a novel class-conditional generative method using Energy-Based Models (EBMs). Unlike existing methods that use a shared model to approximate all class-conditional densities, our key innovation is to create distinct EBM generative models for each class, each modelling its class-specific data distribution individually. This approach creates robust energy landscapes, even in ambiguous class distributions. Our experiments show that TabEBM generates synthetic data with higher quality and better statistical fidelity than existing methods. When used for data augmentation, our synthetic data consistently improves the classification performance across diverse datasets of various sizes, especially small ones.
Exploring Time Granularity on Temporal Graphs for Dynamic Link Prediction in Real-world Networks
Nov 22, 2023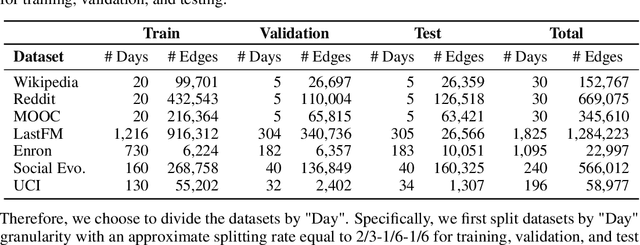

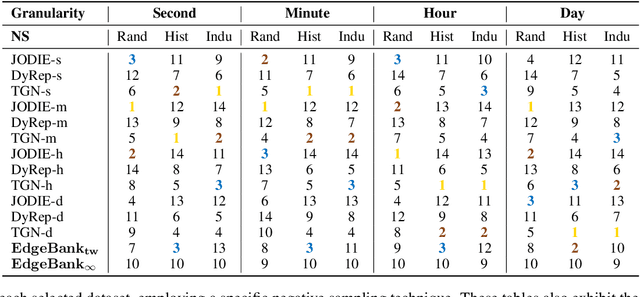

Dynamic Graph Neural Networks (DGNNs) have emerged as the predominant approach for processing dynamic graph-structured data. However, the influence of temporal information on model performance and robustness remains insufficiently explored, particularly regarding how models address prediction tasks with different time granularities. In this paper, we explore the impact of time granularity when training DGNNs on dynamic graphs through extensive experiments. We examine graphs derived from various domains and compare three different DGNNs to the baseline model across four varied time granularities. We mainly consider the interplay between time granularities, model architectures, and negative sampling strategies to obtain general conclusions. Our results reveal that a sophisticated memory mechanism and proper time granularity are crucial for a DGNN to deliver competitive and robust performance in the dynamic link prediction task. We also discuss drawbacks in considered models and datasets and propose promising directions for future research on the time granularity of temporal graphs.
ProtoGate: Prototype-based Neural Networks with Local Feature Selection for Tabular Biomedical Data
Jun 21, 2023

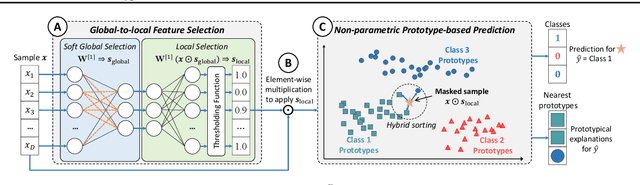
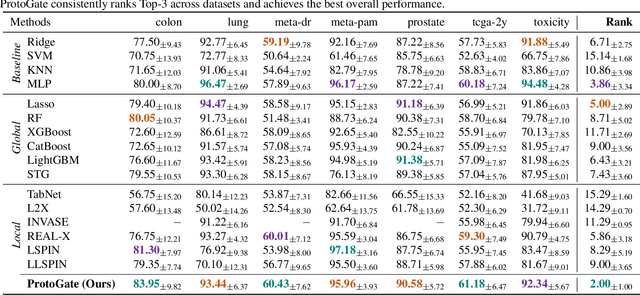
Tabular biomedical data poses challenges in machine learning because it is often high-dimensional and typically low-sample-size. Previous research has attempted to address these challenges via feature selection approaches, which can lead to unstable performance on real-world data. This suggests that current methods lack appropriate inductive biases that capture patterns common to different samples. In this paper, we propose ProtoGate, a prototype-based neural model that introduces an inductive bias by attending to both homogeneity and heterogeneity across samples. ProtoGate selects features in a global-to-local manner and leverages them to produce explainable predictions via an interpretable prototype-based model. We conduct comprehensive experiments to evaluate the performance of ProtoGate on synthetic and real-world datasets. Our results show that exploiting the homogeneous and heterogeneous patterns in the data can improve prediction accuracy while prototypes imbue interpretability.
Multi-view Human Body Mesh Translator
Oct 04, 2022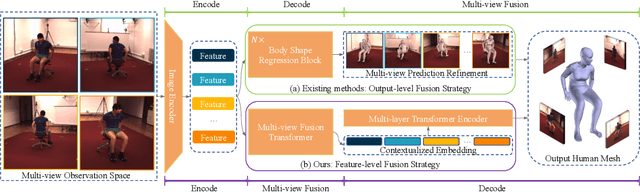
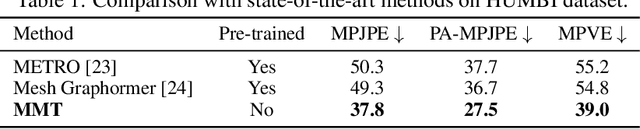
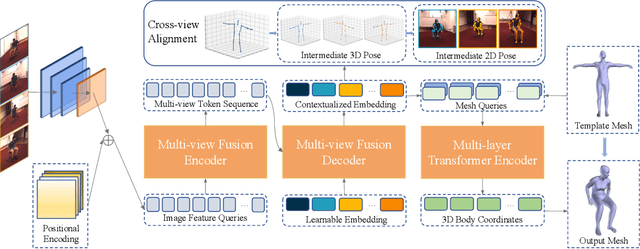

Existing methods for human mesh recovery mainly focus on single-view frameworks, but they often fail to produce accurate results due to the ill-posed setup. Considering the maturity of the multi-view motion capture system, in this paper, we propose to solve the prior ill-posed problem by leveraging multiple images from different views, thus significantly enhancing the quality of recovered meshes. In particular, we present a novel \textbf{M}ulti-view human body \textbf{M}esh \textbf{T}ranslator (MMT) model for estimating human body mesh with the help of vision transformer. Specifically, MMT takes multi-view images as input and translates them to targeted meshes in a single-forward manner. MMT fuses features of different views in both encoding and decoding phases, leading to representations embedded with global information. Additionally, to ensure the tokens are intensively focused on the human pose and shape, MMT conducts cross-view alignment at the feature level by projecting 3D keypoint positions to each view and enforcing their consistency in geometry constraints. Comprehensive experiments demonstrate that MMT outperforms existing single or multi-view models by a large margin for human mesh recovery task, notably, 28.8\% improvement in MPVE over the current state-of-the-art method on the challenging HUMBI dataset. Qualitative evaluation also verifies the effectiveness of MMT in reconstructing high-quality human mesh. Codes will be made available upon acceptance.
DropKey
Aug 08, 2022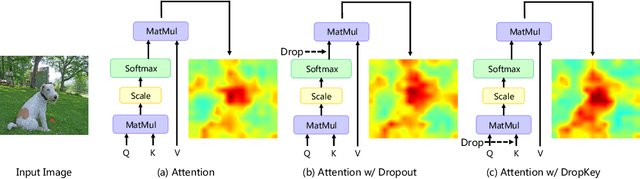

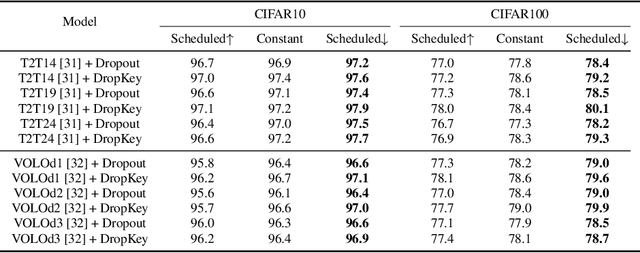
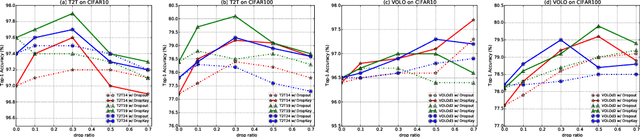
In this paper, we focus on analyzing and improving the dropout technique for self-attention layers of Vision Transformer, which is important while surprisingly ignored by prior works. In particular, we conduct researches on three core questions: First, what to drop in self-attention layers? Different from dropping attention weights in literature, we propose to move dropout operations forward ahead of attention matrix calculation and set the Key as the dropout unit, yielding a novel dropout-before-softmax scheme. We theoretically verify that this scheme helps keep both regularization and probability features of attention weights, alleviating the overfittings problem to specific patterns and enhancing the model to globally capture vital information; Second, how to schedule the drop ratio in consecutive layers? In contrast to exploit a constant drop ratio for all layers, we present a new decreasing schedule that gradually decreases the drop ratio along the stack of self-attention layers. We experimentally validate the proposed schedule can avoid overfittings in low-level features and missing in high-level semantics, thus improving the robustness and stableness of model training; Third, whether need to perform structured dropout operation as CNN? We attempt patch-based block-version of dropout operation and find that this useful trick for CNN is not essential for ViT. Given exploration on the above three questions, we present the novel DropKey method that regards Key as the drop unit and exploits decreasing schedule for drop ratio, improving ViTs in a general way. Comprehensive experiments demonstrate the effectiveness of DropKey for various ViT architectures, e.g. T2T and VOLO, as well as for various vision tasks, e.g., image classification, object detection, human-object interaction detection and human body shape recovery. Codes will be released upon acceptance.
Towards Real-world X-ray Security Inspection: A High-Quality Benchmark and Lateral Inhibition Module for Prohibited Items Detection
Aug 23, 2021
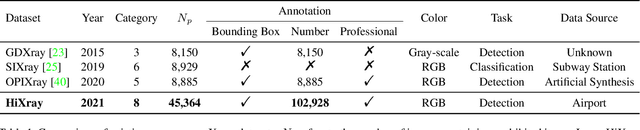
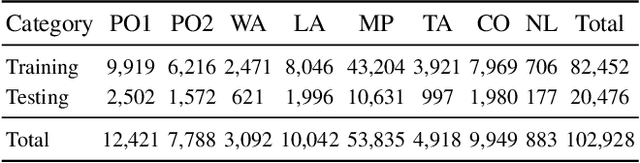

Prohibited items detection in X-ray images often plays an important role in protecting public safety, which often deals with color-monotonous and luster-insufficient objects, resulting in unsatisfactory performance. Till now, there have been rare studies touching this topic due to the lack of specialized high-quality datasets. In this work, we first present a High-quality X-ray (HiXray) security inspection image dataset, which contains 102,928 common prohibited items of 8 categories. It is the largest dataset of high quality for prohibited items detection, gathered from the real-world airport security inspection and annotated by professional security inspectors. Besides, for accurate prohibited item detection, we further propose the Lateral Inhibition Module (LIM) inspired by the fact that humans recognize these items by ignoring irrelevant information and focusing on identifiable characteristics, especially when objects are overlapped with each other. Specifically, LIM, the elaborately designed flexible additional module, suppresses the noisy information flowing maximumly by the Bidirectional Propagation (BP) module and activates the most identifiable charismatic, boundary, from four directions by Boundary Activation (BA) module. We evaluate our method extensively on HiXray and OPIXray and the results demonstrate that it outperforms SOTA detection methods.