 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl and Realism: Best of Both Worlds in Layout-to-Image without Training
Jun 18, 2025Layout-to-Image generation aims to create complex scenes with precise control over the placement and arrangement of subjects. Existing works have demonstrated that pre-trained Text-to-Image diffusion models can achieve this goal without training on any specific data; however, they often face challenges with imprecise localization and unrealistic artifacts. Focusing on these drawbacks, we propose a novel training-free method, WinWinLay. At its core, WinWinLay presents two key strategies, Non-local Attention Energy Function and Adaptive Update, that collaboratively enhance control precision and realism. On one hand, we theoretically demonstrate that the commonly used attention energy function introduces inherent spatial distribution biases, hindering objects from being uniformly aligned with layout instructions. To overcome this issue, non-local attention prior is explored to redistribute attention scores, facilitating objects to better conform to the specified spatial conditions. On the other hand, we identify that the vanilla backpropagation update rule can cause deviations from the pre-trained domain, leading to out-of-distribution artifacts. We accordingly introduce a Langevin dynamics-based adaptive update scheme as a remedy that promotes in-domain updating while respecting layout constraints. Extensive experiments demonstrate that WinWinLay excels in controlling element placement and achieving photorealistic visual fidelity, outperforming the current state-of-the-art methods.
StyO: Stylize Your Face in Only One-Shot
Mar 07, 2023



This paper focuses on face stylization with a single artistic target. Existing works for this task often fail to retain the source content while achieving geometry variation. Here, we present a novel StyO model, ie. Stylize the face in only One-shot, to solve the above problem. In particular, StyO exploits a disentanglement and recombination strategy. It first disentangles the content and style of source and target images into identifiers, which are then recombined in a cross manner to derive the stylized face image. In this way, StyO decomposes complex images into independent and specific attributes, and simplifies one-shot face stylization as the combination of different attributes from input images, thus producing results better matching face geometry of target image and content of source one. StyO is implemented with latent diffusion models (LDM) and composed of two key modules: 1) Identifier Disentanglement Learner (IDL) for disentanglement phase. It represents identifiers as contrastive text prompts, ie. positive and negative descriptions. And it introduces a novel triple reconstruction loss to fine-tune the pre-trained LDM for encoding style and content into corresponding identifiers; 2) Fine-grained Content Controller (FCC) for the recombination phase. It recombines disentangled identifiers from IDL to form an augmented text prompt for generating stylized faces. In addition, FCC also constrains the cross-attention maps of latent and text features to preserve source face details in results. The extensive evaluation shows that StyO produces high-quality images on numerous paintings of various styles and outperforms the current state-of-the-art. Code will be released upon acceptance.
DropKey
Aug 08, 2022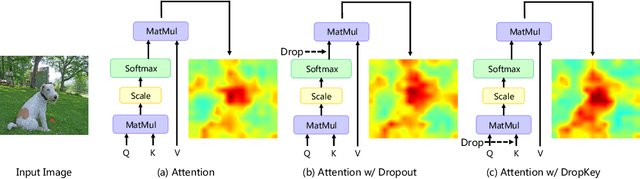

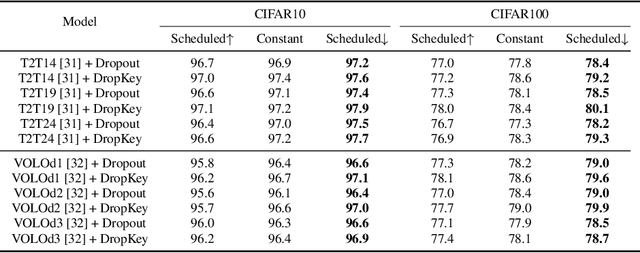
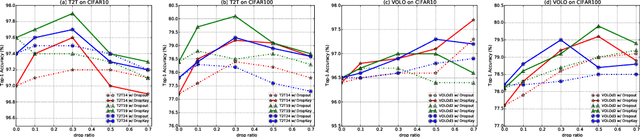
In this paper, we focus on analyzing and improving the dropout technique for self-attention layers of Vision Transformer, which is important while surprisingly ignored by prior works. In particular, we conduct researches on three core questions: First, what to drop in self-attention layers? Different from dropping attention weights in literature, we propose to move dropout operations forward ahead of attention matrix calculation and set the Key as the dropout unit, yielding a novel dropout-before-softmax scheme. We theoretically verify that this scheme helps keep both regularization and probability features of attention weights, alleviating the overfittings problem to specific patterns and enhancing the model to globally capture vital information; Second, how to schedule the drop ratio in consecutive layers? In contrast to exploit a constant drop ratio for all layers, we present a new decreasing schedule that gradually decreases the drop ratio along the stack of self-attention layers. We experimentally validate the proposed schedule can avoid overfittings in low-level features and missing in high-level semantics, thus improving the robustness and stableness of model training; Third, whether need to perform structured dropout operation as CNN? We attempt patch-based block-version of dropout operation and find that this useful trick for CNN is not essential for ViT. Given exploration on the above three questions, we present the novel DropKey method that regards Key as the drop unit and exploits decreasing schedule for drop ratio, improving ViTs in a general way. Comprehensive experiments demonstrate the effectiveness of DropKey for various ViT architectures, e.g. T2T and VOLO, as well as for various vision tasks, e.g., image classification, object detection, human-object interaction detection and human body shape recovery. Codes will be released upon acceptance.