 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl and Realism: Best of Both Worlds in Layout-to-Image without Training
Jun 18, 2025Layout-to-Image generation aims to create complex scenes with precise control over the placement and arrangement of subjects. Existing works have demonstrated that pre-trained Text-to-Image diffusion models can achieve this goal without training on any specific data; however, they often face challenges with imprecise localization and unrealistic artifacts. Focusing on these drawbacks, we propose a novel training-free method, WinWinLay. At its core, WinWinLay presents two key strategies, Non-local Attention Energy Function and Adaptive Update, that collaboratively enhance control precision and realism. On one hand, we theoretically demonstrate that the commonly used attention energy function introduces inherent spatial distribution biases, hindering objects from being uniformly aligned with layout instructions. To overcome this issue, non-local attention prior is explored to redistribute attention scores, facilitating objects to better conform to the specified spatial conditions. On the other hand, we identify that the vanilla backpropagation update rule can cause deviations from the pre-trained domain, leading to out-of-distribution artifacts. We accordingly introduce a Langevin dynamics-based adaptive update scheme as a remedy that promotes in-domain updating while respecting layout constraints. Extensive experiments demonstrate that WinWinLay excels in controlling element placement and achieving photorealistic visual fidelity, outperforming the current state-of-the-art methods.
LokiTalk: Learning Fine-Grained and Generalizable Correspondences to Enhance NeRF-based Talking Head Synthesis
Nov 29, 2024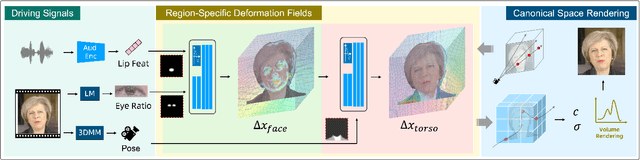
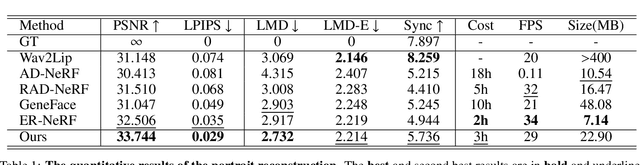
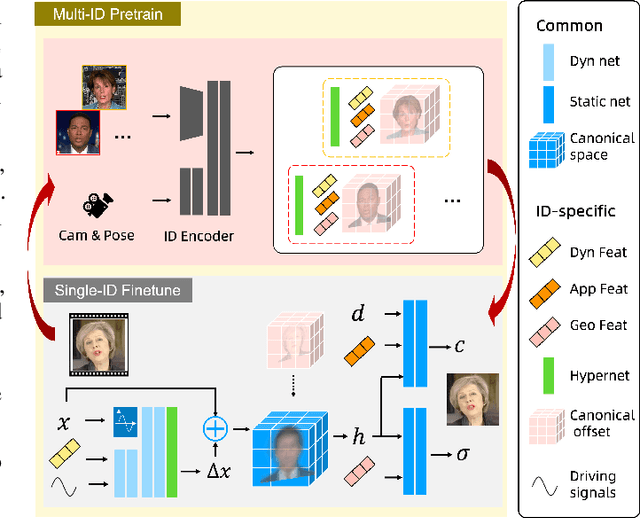

Despite significant progress in talking head synthesis since the introduction of Neural Radiance Fields (NeRF), visual artifacts and high training costs persist as major obstacles to large-scale commercial adoption. We propose that identifying and establishing fine-grained and generalizable correspondences between driving signals and generated results can simultaneously resolve both problems. Here we present LokiTalk, a novel framework designed to enhance NeRF-based talking heads with lifelike facial dynamics and improved training efficiency. To achieve fine-grained correspondences, we introduce Region-Specific Deformation Fields, which decompose the overall portrait motion into lip movements, eye blinking, head pose, and torso movements. By hierarchically modeling the driving signals and their associated regions through two cascaded deformation fields, we significantly improve dynamic accuracy and minimize synthetic artifacts. Furthermore, we propose ID-Aware Knowledge Transfer, a plug-and-play module that learns generalizable dynamic and static correspondences from multi-identity videos, while simultaneously extracting ID-specific dynamic and static features to refine the depiction of individual characters. Comprehensive evaluations demonstrate that LokiTalk delivers superior high-fidelity results and training efficiency compared to previous methods. The code will be released upon acceptance.
DR-BFR: Degradation Representation with Diffusion Models for Blind Face Restoration
Nov 15, 2024



Blind face restoration (BFR) is fundamentally challenged by the extensive range of degradation types and degrees that impact model generalization. Recent advancements in diffusion models have made considerable progress in this field. Nevertheless, a critical limitation is their lack of awareness of specific degradation, leading to potential issues such as unnatural details and inaccurate textures. In this paper, we equip diffusion models with the capability to decouple various degradation as a degradation prompt from low-quality (LQ) face images via unsupervised contrastive learning with reconstruction loss, and demonstrate that this capability significantly improves performance, particularly in terms of the naturalness of the restored images. Our novel restoration scheme, named DR-BFR, guides the denoising of Latent Diffusion Models (LDM) by incorporating Degradation Representation (DR) and content features from LQ images. DR-BFR comprises two modules: 1) Degradation Representation Module (DRM): This module extracts degradation representation with content-irrelevant features from LQ faces and estimates a reasonable distribution in the degradation space through contrastive learning and a specially designed LQ reconstruction. 2) Latent Diffusion Restoration Module (LDRM): This module perceives both degradation features and content features in the latent space, enabling the restoration of high-quality images from LQ inputs. Our experiments demonstrate that the proposed DR-BFR significantly outperforms state-of-the-art methods quantitatively and qualitatively across various datasets. The DR effectively distinguishes between various degradations in blind face inverse problems and provides a reasonably powerful prompt to LDM.
Focus on Neighbors and Know the Whole: Towards Consistent Dense Multiview Text-to-Image Generator for 3D Creation
Aug 26, 2024



Generating dense multiview images from text prompts is crucial for creating high-fidelity 3D assets. Nevertheless, existing methods struggle with space-view correspondences, resulting in sparse and low-quality outputs. In this paper, we introduce CoSER, a novel consistent dense Multiview Text-to-Image Generator for Text-to-3D, achieving both efficiency and quality by meticulously learning neighbor-view coherence and further alleviating ambiguity through the swift traversal of all views. For achieving neighbor-view consistency, each viewpoint densely interacts with adjacent viewpoints to perceive the global spatial structure, and aggregates information along motion paths explicitly defined by physical principles to refine details. To further enhance cross-view consistency and alleviate content drift, CoSER rapidly scan all views in spiral bidirectional manner to aware holistic information and then scores each point based on semantic material. Subsequently, we conduct weighted down-sampling along the spatial dimension based on scores, thereby facilitating prominent information fusion across all views with lightweight computation. Technically, the core module is built by integrating the attention mechanism with a selective state space model, exploiting the robust learning capabilities of the former and the low overhead of the latter. Extensive evaluation shows that CoSER is capable of producing dense, high-fidelity, content-consistent multiview images that can be flexibly integrated into various 3D generation models.
Blaze3DM: Marry Triplane Representation with Diffusion for 3D Medical Inverse Problem Solving
May 24, 2024



Solving 3D medical inverse problems such as image restoration and reconstruction is crucial in modern medical field. However, the curse of dimensionality in 3D medical data leads mainstream volume-wise methods to suffer from high resource consumption and challenges models to successfully capture the natural distribution, resulting in inevitable volume inconsistency and artifacts. Some recent works attempt to simplify generation in the latent space but lack the capability to efficiently model intricate image details. To address these limitations, we present Blaze3DM, a novel approach that enables fast and high-fidelity generation by integrating compact triplane neural field and powerful diffusion model. In technique, Blaze3DM begins by optimizing data-dependent triplane embeddings and a shared decoder simultaneously, reconstructing each triplane back to the corresponding 3D volume. To further enhance 3D consistency, we introduce a lightweight 3D aware module to model the correlation of three vertical planes. Then, diffusion model is trained on latent triplane embeddings and achieves both unconditional and conditional triplane generation, which is finally decoded to arbitrary size volume. Extensive experiments on zero-shot 3D medical inverse problem solving, including sparse-view CT, limited-angle CT, compressed-sensing MRI, and MRI isotropic super-resolution, demonstrate that Blaze3DM not only achieves state-of-the-art performance but also markedly improves computational efficiency over existing methods (22~40x faster than previous work).
BlazeBVD: Make Scale-Time Equalization Great Again for Blind Video Deflickering
Mar 10, 2024



Developing blind video deflickering (BVD) algorithms to enhance video temporal consistency, is gaining importance amid the flourish of image processing and video generation. However, the intricate nature of video data complicates the training of deep learning methods, leading to high resource consumption and instability, notably under severe lighting flicker. This underscores the critical need for a compact representation beyond pixel values to advance BVD research and applications. Inspired by the classic scale-time equalization (STE), our work introduces the histogram-assisted solution, called BlazeBVD, for high-fidelity and rapid BVD. Compared with STE, which directly corrects pixel values by temporally smoothing color histograms, BlazeBVD leverages smoothed illumination histograms within STE filtering to ease the challenge of learning temporal data using neural networks. In technique, BlazeBVD begins by condensing pixel values into illumination histograms that precisely capture flickering and local exposure variations. These histograms are then smoothed to produce singular frames set, filtered illumination maps, and exposure maps. Resorting to these deflickering priors, BlazeBVD utilizes a 2D network to restore faithful and consistent texture impacted by lighting changes or localized exposure issues. BlazeBVD also incorporates a lightweight 3D network to amend slight temporal inconsistencies, avoiding the resource consumption issue. Comprehensive experiments on synthetic, real-world and generated videos, showcase the superior qualitative and quantitative results of BlazeBVD, achieving inference speeds up to 10x faster than state-of-the-arts.
Learning Dynamic Tetrahedra for High-Quality Talking Head Synthesis
Feb 27, 2024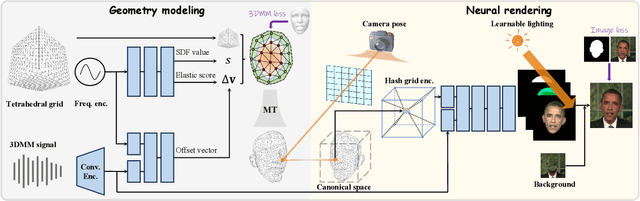
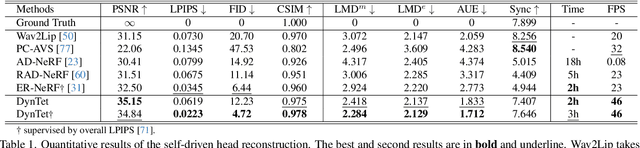

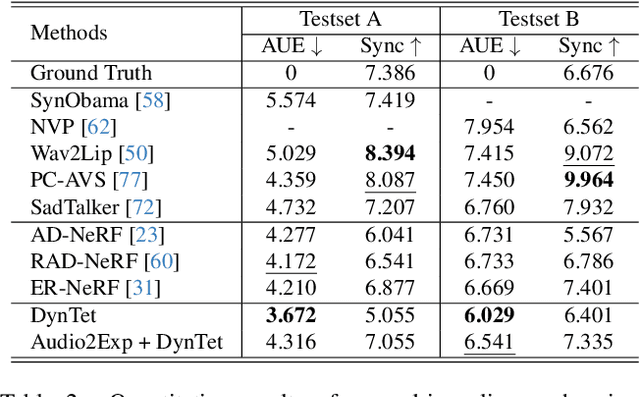
Recent works in implicit representations, such as Neural Radiance Fields (NeRF), have advanced the generation of realistic and animatable head avatars from video sequences. These implicit methods are still confronted by visual artifacts and jitters, since the lack of explicit geometric constraints poses a fundamental challenge in accurately modeling complex facial deformations. In this paper, we introduce Dynamic Tetrahedra (DynTet), a novel hybrid representation that encodes explicit dynamic meshes by neural networks to ensure geometric consistency across various motions and viewpoints. DynTet is parameterized by the coordinate-based networks which learn signed distance, deformation, and material texture, anchoring the training data into a predefined tetrahedra grid. Leveraging Marching Tetrahedra, DynTet efficiently decodes textured meshes with a consistent topology, enabling fast rendering through a differentiable rasterizer and supervision via a pixel loss. To enhance training efficiency, we incorporate classical 3D Morphable Models to facilitate geometry learning and define a canonical space for simplifying texture learning. These advantages are readily achievable owing to the effective geometric representation employed in DynTet. Compared with prior works, DynTet demonstrates significant improvements in fidelity, lip synchronization, and real-time performance according to various metrics. Beyond producing stable and visually appealing synthesis videos, our method also outputs the dynamic meshes which is promising to enable many emerging applications.
General Method for Solving Four Types of SAT Problems
Dec 27, 2023Existing methods provide varying algorithms for different types of Boolean satisfiability problems (SAT), lacking a general solution framework. Accordingly, this study proposes a unified framework DCSAT based on integer programming and reinforcement learning (RL) algorithm to solve different types of SAT problems such as MaxSAT, Weighted MaxSAT, PMS, WPMS. Specifically, we first construct a consolidated integer programming representation for four types of SAT problems by adjusting objective function coefficients. Secondly, we construct an appropriate reinforcement learning models based on the 0-1 integer programming for SAT problems. Based on the binary tree search structure, we apply the Monte Carlo tree search (MCTS) method on SAT problems. Finally, we prove that this method can find all optimal Boolean assignments based on Wiener-khinchin law of large Numbers. We experimentally verify that this paradigm can prune the unnecessary search space to find the optimal Boolean assignments for the problem. Furthermore, the proposed method can provide diverse labels for supervised learning methods for SAT problems.
Towards Consistent Video Editing with Text-to-Image Diffusion Models
May 27, 2023
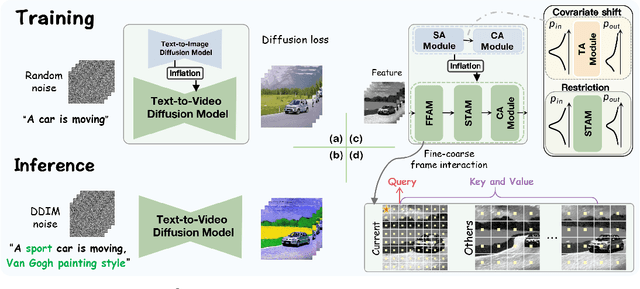


Existing works have advanced Text-to-Image (TTI) diffusion models for video editing in a one-shot learning manner. Despite their low requirements of data and computation, these methods might produce results of unsatisfied consistency with text prompt as well as temporal sequence, limiting their applications in the real world. In this paper, we propose to address the above issues with a novel EI$^2$ model towards \textbf{E}nhancing v\textbf{I}deo \textbf{E}diting cons\textbf{I}stency of TTI-based frameworks. Specifically, we analyze and find that the inconsistent problem is caused by newly added modules into TTI models for learning temporal information. These modules lead to covariate shift in the feature space, which harms the editing capability. Thus, we design EI$^2$ to tackle the above drawbacks with two classical modules: Shift-restricted Temporal Attention Module (STAM) and Fine-coarse Frame Attention Module (FFAM). First, through theoretical analysis, we demonstrate that covariate shift is highly related to Layer Normalization, thus STAM employs a \textit{Instance Centering} layer replacing it to preserve the distribution of temporal features. In addition, {STAM} employs an attention layer with normalized mapping to transform temporal features while constraining the variance shift. As the second part, we incorporate {STAM} with a novel {FFAM}, which efficiently leverages fine-coarse spatial information of overall frames to further enhance temporal consistency. Extensive experiments demonstrate the superiority of the proposed EI$^2$ model for text-driven video editing.
DiffBFR: Bootstrapping Diffusion Model Towards Blind Face Restoration
May 08, 2023
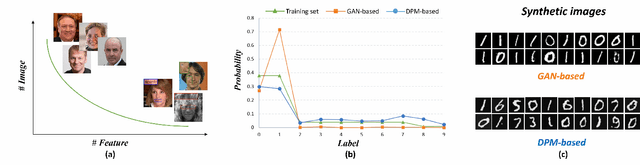
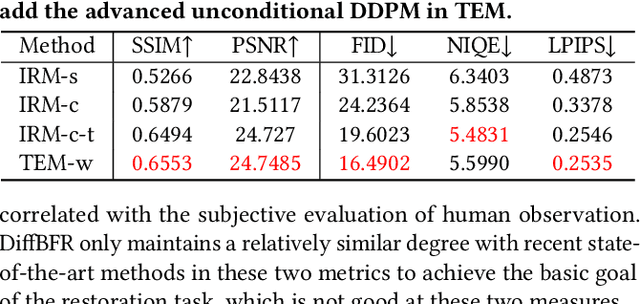
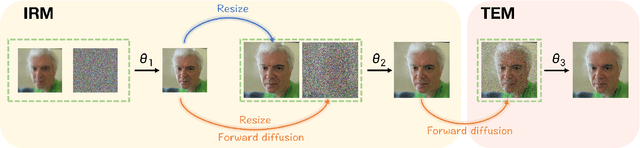
Blind face restoration (BFR) is important while challenging. Prior works prefer to exploit GAN-based frameworks to tackle this task due to the balance of quality and efficiency. However, these methods suffer from poor stability and adaptability to long-tail distribution, failing to simultaneously retain source identity and restore detail. We propose DiffBFR to introduce Diffusion Probabilistic Model (DPM) for BFR to tackle the above problem, given its superiority over GAN in aspects of avoiding training collapse and generating long-tail distribution. DiffBFR utilizes a two-step design, that first restores identity information from low-quality images and then enhances texture details according to the distribution of real faces. This design is implemented with two key components: 1) Identity Restoration Module (IRM) for preserving the face details in results. Instead of denoising from pure Gaussian random distribution with LQ images as the condition during the reverse process, we propose a novel truncated sampling method which starts from LQ images with part noise added. We theoretically prove that this change shrinks the evidence lower bound of DPM and then restores more original details. With theoretical proof, two cascade conditional DPMs with different input sizes are introduced to strengthen this sampling effect and reduce training difficulty in the high-resolution image generated directly. 2) Texture Enhancement Module (TEM) for polishing the texture of the image. Here an unconditional DPM, a LQ-free model, is introduced to further force the restorations to appear realistic. We theoretically proved that this unconditional DPM trained on pure HQ images contributes to justifying the correct distribution of inference images output from IRM in pixel-level space. Truncated sampling with fractional time step is utilized to polish pixel-level textures while preserving identity information.