 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffBFR: Bootstrapping Diffusion Model Towards Blind Face Restoration
May 08, 2023
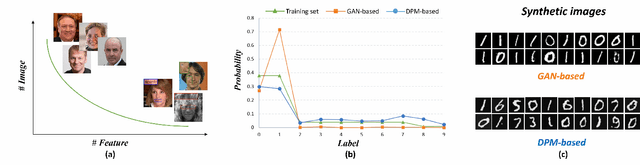
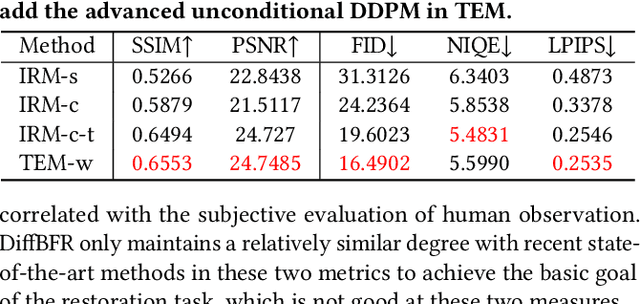
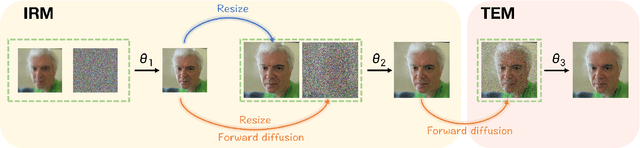
Blind face restoration (BFR) is important while challenging. Prior works prefer to exploit GAN-based frameworks to tackle this task due to the balance of quality and efficiency. However, these methods suffer from poor stability and adaptability to long-tail distribution, failing to simultaneously retain source identity and restore detail. We propose DiffBFR to introduce Diffusion Probabilistic Model (DPM) for BFR to tackle the above problem, given its superiority over GAN in aspects of avoiding training collapse and generating long-tail distribution. DiffBFR utilizes a two-step design, that first restores identity information from low-quality images and then enhances texture details according to the distribution of real faces. This design is implemented with two key components: 1) Identity Restoration Module (IRM) for preserving the face details in results. Instead of denoising from pure Gaussian random distribution with LQ images as the condition during the reverse process, we propose a novel truncated sampling method which starts from LQ images with part noise added. We theoretically prove that this change shrinks the evidence lower bound of DPM and then restores more original details. With theoretical proof, two cascade conditional DPMs with different input sizes are introduced to strengthen this sampling effect and reduce training difficulty in the high-resolution image generated directly. 2) Texture Enhancement Module (TEM) for polishing the texture of the image. Here an unconditional DPM, a LQ-free model, is introduced to further force the restorations to appear realistic. We theoretically proved that this unconditional DPM trained on pure HQ images contributes to justifying the correct distribution of inference images output from IRM in pixel-level space. Truncated sampling with fractional time step is utilized to polish pixel-level textures while preserving identity information.
ExSinGAN: Learning an Explainable Generative Model from a Single Image
May 16, 2021
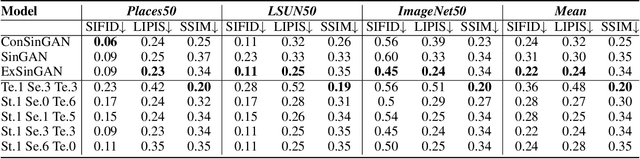
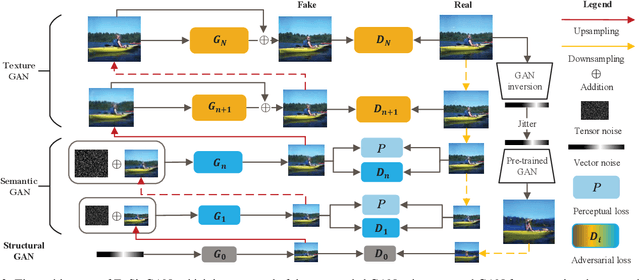
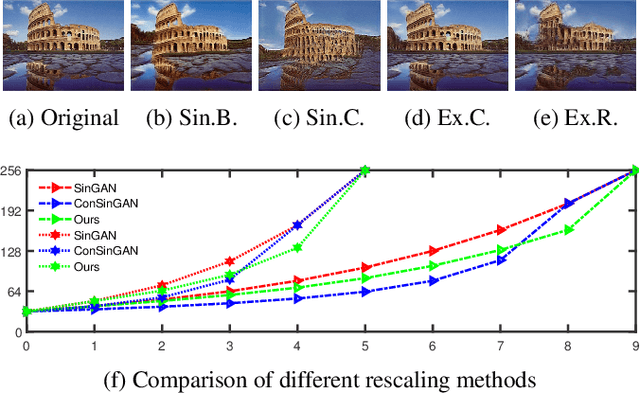
Generating images from a single sample, as a newly developing branch of image synthesis, has attracted extensive attention. In this paper, we formulate this problem as sampling from the conditional distribution of a single image, and propose a hierarchical framework that simplifies the learning of the intricate conditional distributions through the successive learning of the distributions about structure, semantics and texture, making the process of learning and generation comprehensible. On this basis, we design ExSinGAN composed of three cascaded GANs for learning an explainable generative model from a given image, where the cascaded GANs model the distributions about structure, semantics and texture successively. ExSinGAN is learned not only from the internal patches of the given image as the previous works did, but also from the external prior obtained by the GAN inversion technique. Benefiting from the appropriate combination of internal and external information, ExSinGAN has a more powerful capability of generation and competitive generalization ability for the image manipulation tasks compared with prior works.