 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLokiTalk: Learning Fine-Grained and Generalizable Correspondences to Enhance NeRF-based Talking Head Synthesis
Nov 29, 2024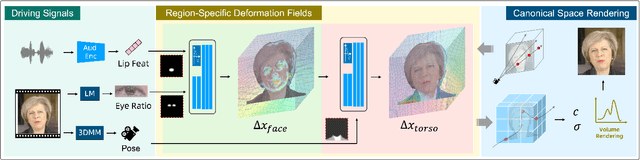
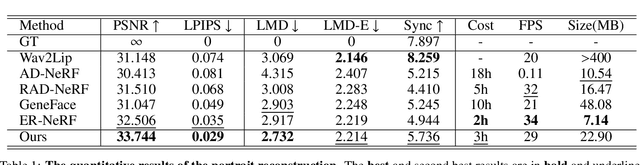
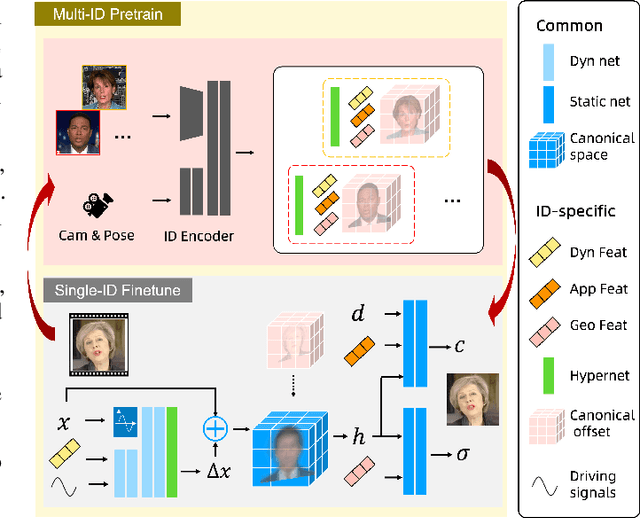

Despite significant progress in talking head synthesis since the introduction of Neural Radiance Fields (NeRF), visual artifacts and high training costs persist as major obstacles to large-scale commercial adoption. We propose that identifying and establishing fine-grained and generalizable correspondences between driving signals and generated results can simultaneously resolve both problems. Here we present LokiTalk, a novel framework designed to enhance NeRF-based talking heads with lifelike facial dynamics and improved training efficiency. To achieve fine-grained correspondences, we introduce Region-Specific Deformation Fields, which decompose the overall portrait motion into lip movements, eye blinking, head pose, and torso movements. By hierarchically modeling the driving signals and their associated regions through two cascaded deformation fields, we significantly improve dynamic accuracy and minimize synthetic artifacts. Furthermore, we propose ID-Aware Knowledge Transfer, a plug-and-play module that learns generalizable dynamic and static correspondences from multi-identity videos, while simultaneously extracting ID-specific dynamic and static features to refine the depiction of individual characters. Comprehensive evaluations demonstrate that LokiTalk delivers superior high-fidelity results and training efficiency compared to previous methods. The code will be released upon acceptance.
Ditto: Motion-Space Diffusion for Controllable Realtime Talking Head Synthesis
Nov 29, 2024Recent advances in diffusion models have revolutionized audio-driven talking head synthesis. Beyond precise lip synchronization, diffusion-based methods excel in generating subtle expressions and natural head movements that are well-aligned with the audio signal. However, these methods are confronted by slow inference speed, insufficient fine-grained control over facial motions, and occasional visual artifacts largely due to an implicit latent space derived from Variational Auto-Encoders (VAE), which prevent their adoption in realtime interaction applications. To address these issues, we introduce Ditto, a diffusion-based framework that enables controllable realtime talking head synthesis. Our key innovation lies in bridging motion generation and photorealistic neural rendering through an explicit identity-agnostic motion space, replacing conventional VAE representations. This design substantially reduces the complexity of diffusion learning while enabling precise control over the synthesized talking heads. We further propose an inference strategy that jointly optimizes three key components: audio feature extraction, motion generation, and video synthesis. This optimization enables streaming processing, realtime inference, and low first-frame delay, which are the functionalities crucial for interactive applications such as AI assistants. Extensive experimental results demonstrate that Ditto generates compelling talking head videos and substantially outperforms existing methods in both motion control and realtime performance.
Animate-X: Universal Character Image Animation with Enhanced Motion Representation
Oct 14, 2024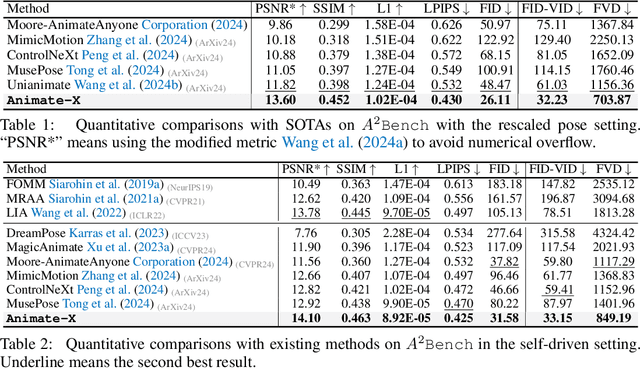
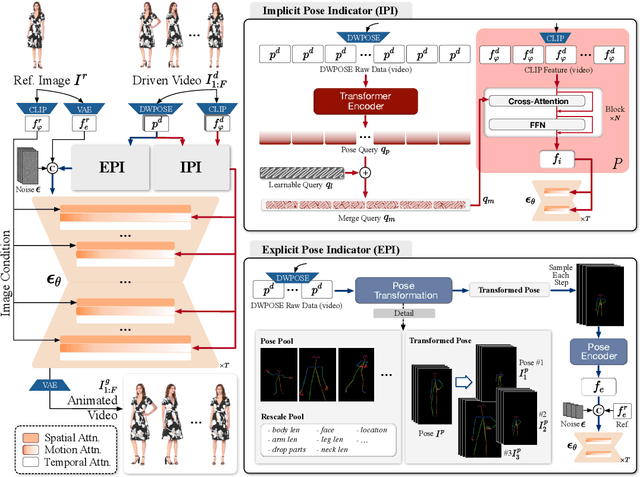


Character image animation, which generates high-quality videos from a reference image and target pose sequence, has seen significant progress in recent years. However, most existing methods only apply to human figures, which usually do not generalize well on anthropomorphic characters commonly used in industries like gaming and entertainment. Our in-depth analysis suggests to attribute this limitation to their insufficient modeling of motion, which is unable to comprehend the movement pattern of the driving video, thus imposing a pose sequence rigidly onto the target character. To this end, this paper proposes Animate-X, a universal animation framework based on LDM for various character types (collectively named X), including anthropomorphic characters. To enhance motion representation, we introduce the Pose Indicator, which captures comprehensive motion pattern from the driving video through both implicit and explicit manner. The former leverages CLIP visual features of a driving video to extract its gist of motion, like the overall movement pattern and temporal relations among motions, while the latter strengthens the generalization of LDM by simulating possible inputs in advance that may arise during inference. Moreover, we introduce a new Animated Anthropomorphic Benchmark (A^2Bench) to evaluate the performance of Animate-X on universal and widely applicable animation images. Extensive experiments demonstrate the superiority and effectiveness of Animate-X compared to state-of-the-art methods.
StyleTokenizer: Defining Image Style by a Single Instance for Controlling Diffusion Models
Sep 04, 2024



Despite the burst of innovative methods for controlling the diffusion process, effectively controlling image styles in text-to-image generation remains a challenging task. Many adapter-based methods impose image representation conditions on the denoising process to accomplish image control. However these conditions are not aligned with the word embedding space, leading to interference between image and text control conditions and the potential loss of semantic information from the text prompt. Addressing this issue involves two key challenges. Firstly, how to inject the style representation without compromising the effectiveness of text representation in control. Secondly, how to obtain the accurate style representation from a single reference image. To tackle these challenges, we introduce StyleTokenizer, a zero-shot style control image generation method that aligns style representation with text representation using a style tokenizer. This alignment effectively minimizes the impact on the effectiveness of text prompts. Furthermore, we collect a well-labeled style dataset named Style30k to train a style feature extractor capable of accurately representing style while excluding other content information. Experimental results demonstrate that our method fully grasps the style characteristics of the reference image, generating appealing images that are consistent with both the target image style and text prompt. The code and dataset are available at https://github.com/alipay/style-tokenizer.
Learning Dynamic Tetrahedra for High-Quality Talking Head Synthesis
Feb 27, 2024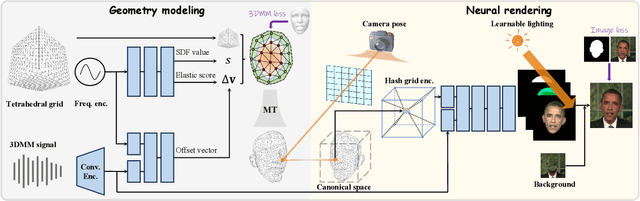
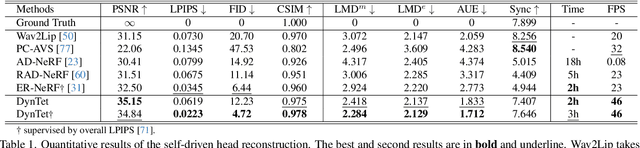

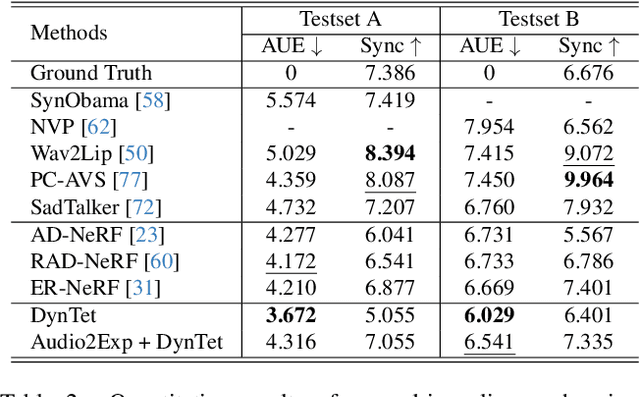
Recent works in implicit representations, such as Neural Radiance Fields (NeRF), have advanced the generation of realistic and animatable head avatars from video sequences. These implicit methods are still confronted by visual artifacts and jitters, since the lack of explicit geometric constraints poses a fundamental challenge in accurately modeling complex facial deformations. In this paper, we introduce Dynamic Tetrahedra (DynTet), a novel hybrid representation that encodes explicit dynamic meshes by neural networks to ensure geometric consistency across various motions and viewpoints. DynTet is parameterized by the coordinate-based networks which learn signed distance, deformation, and material texture, anchoring the training data into a predefined tetrahedra grid. Leveraging Marching Tetrahedra, DynTet efficiently decodes textured meshes with a consistent topology, enabling fast rendering through a differentiable rasterizer and supervision via a pixel loss. To enhance training efficiency, we incorporate classical 3D Morphable Models to facilitate geometry learning and define a canonical space for simplifying texture learning. These advantages are readily achievable owing to the effective geometric representation employed in DynTet. Compared with prior works, DynTet demonstrates significant improvements in fidelity, lip synchronization, and real-time performance according to various metrics. Beyond producing stable and visually appealing synthesis videos, our method also outputs the dynamic meshes which is promising to enable many emerging applications.
DC-Former: Diverse and Compact Transformer for Person Re-Identification
Feb 28, 2023In person re-identification (re-ID) task, it is still challenging to learn discriminative representation by deep learning, due to limited data. Generally speaking, the model will get better performance when increasing the amount of data. The addition of similar classes strengthens the ability of the classifier to identify similar identities, thereby improving the discrimination of representation. In this paper, we propose a Diverse and Compact Transformer (DC-Former) that can achieve a similar effect by splitting embedding space into multiple diverse and compact subspaces. Compact embedding subspace helps model learn more robust and discriminative embedding to identify similar classes. And the fusion of these diverse embeddings containing more fine-grained information can further improve the effect of re-ID. Specifically, multiple class tokens are used in vision transformer to represent multiple embedding spaces. Then, a self-diverse constraint (SDC) is applied to these spaces to push them away from each other, which makes each embedding space diverse and compact. Further, a dynamic weight controller(DWC) is further designed for balancing the relative importance among them during training. The experimental results of our method are promising, which surpass previous state-of-the-art methods on several commonly used person re-ID benchmarks.
HBReID: Harder Batch for Re-identification
Dec 09, 2021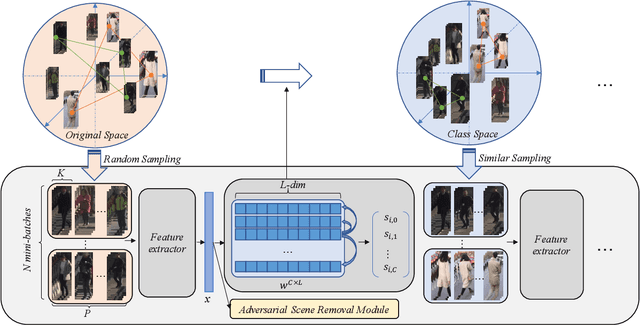
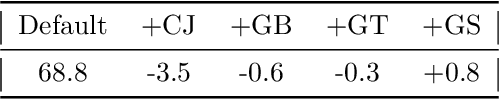

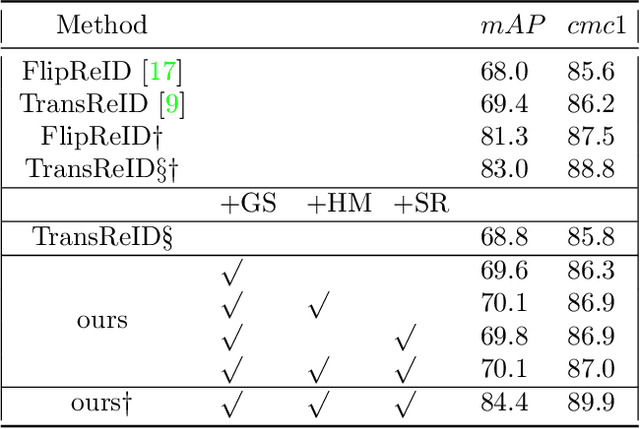
Triplet loss is a widely adopted loss function in ReID task which pulls the hardest positive pairs close and pushes the hardest negative pairs far away. However, the selected samples are not the hardest globally, but the hardest only in a mini-batch, which will affect the performance. In this report, a hard batch mining method is proposed to mine the hardest samples globally to make triplet harder. More specifically, the most similar classes are selected into a same mini-batch so that the similar classes could be pushed further away. Besides, an adversarial scene removal module composed of a scene classifier and an adversarial loss is used to learn scene invariant feature representations. Experiments are conducted on dataset MSMT17 to prove the effectiveness, and our method surpasses all of the previous methods and sets state-of-the-art result.
Photorealistic Lip Sync with Adversarial Temporal Convolutional Networks
Feb 20, 2020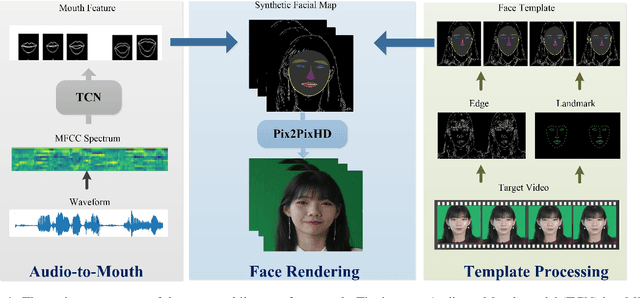

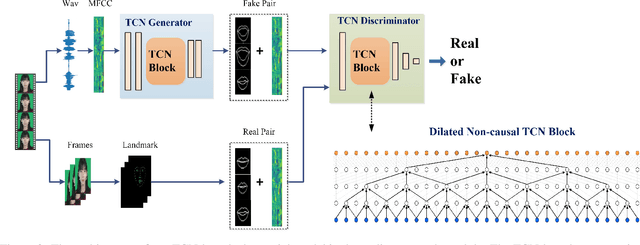

Lip sync has emerged as a promising technique to generate mouth movements on a talking head. However, synthesizing a clear, accurate and human-like performance is still challenging. In this paper, we present a novel lip-sync solution for producing a high-quality and photorealistic talking head from speech. We focus on capturing the specific lip movement and talking style of the target person. We model the seq-to-seq mapping from audio signals to mouth features by two adversarial temporal convolutional networks. Experiments show our model outperforms traditional RNN-based baselines in both accuracy and speed. We also propose an image-to-image translation-based approach for generating high-resolution photoreal face appearance from synthetic facial maps. This fully-trainable framework not only avoids the cumbersome steps like candidate-frame selection in graphics-based rendering methods but also solves some existing issues in recent neural network-based solutions. Our work will benefit related applications such as conversational agent, virtual anchor, tele-presence and gaming.
Joint Ranking SVM and Binary Relevance with Robust Low-Rank Learning for Multi-Label Classification
Nov 05, 2019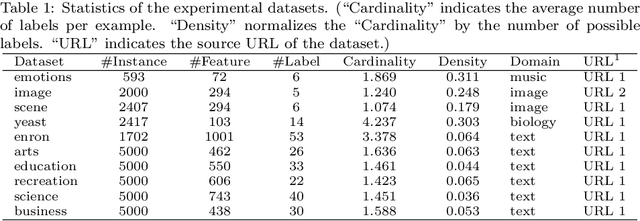
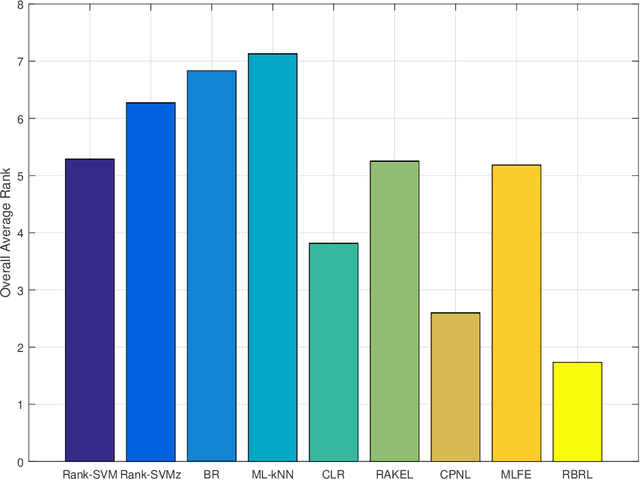

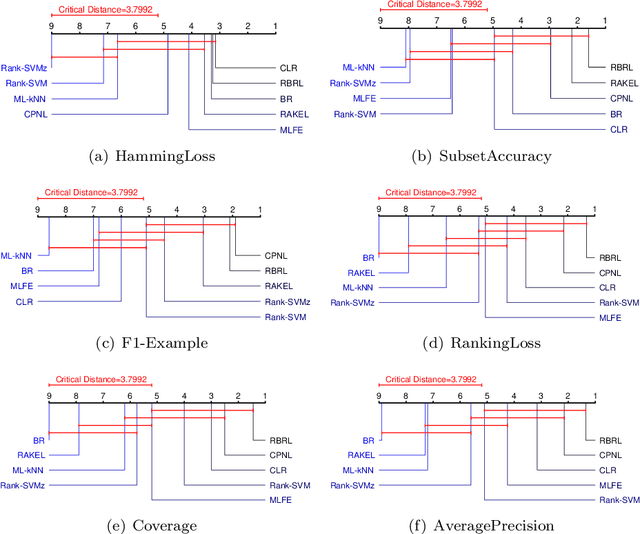
Multi-label classification studies the task where each example belongs to multiple labels simultaneously. As a representative method, Ranking Support Vector Machine (Rank-SVM) aims to minimize the Ranking Loss and can also mitigate the negative influence of the class-imbalance issue. However, due to its stacking-style way for thresholding, it may suffer error accumulation and thus reduces the final classification performance. Binary Relevance (BR) is another typical method, which aims to minimize the Hamming Loss and only needs one-step learning. Nevertheless, it might have the class-imbalance issue and does not take into account label correlations. To address the above issues, we propose a novel multi-label classification model, which joints Ranking support vector machine and Binary Relevance with robust Low-rank learning (RBRL). RBRL inherits the ranking loss minimization advantages of Rank-SVM, and thus overcomes the disadvantages of BR suffering the class-imbalance issue and ignoring the label correlations. Meanwhile, it utilizes the hamming loss minimization and one-step learning advantages of BR, and thus tackles the disadvantages of Rank-SVM including another thresholding learning step. Besides, a low-rank constraint is utilized to further exploit high-order label correlations under the assumption of low dimensional label space. Furthermore, to achieve nonlinear multi-label classifiers, we derive the kernelization RBRL. Two accelerated proximal gradient methods (APG) are used to solve the optimization problems efficiently. Extensive comparative experiments with several state-of-the-art methods illustrate a highly competitive or superior performance of our method RBRL.
* 57 pages, 5 figures, to be published in the journal of Neural Networks