 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDraw Like an Artist: Complex Scene Generation with Diffusion Model via Composition, Painting, and Retouching
Aug 25, 2024
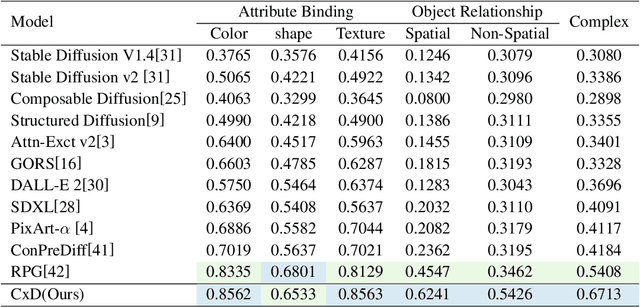
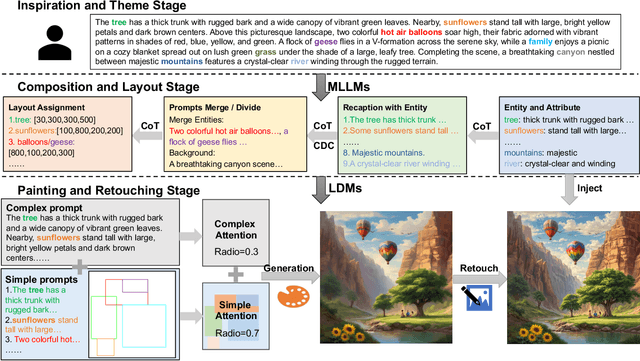
Recent advances in text-to-image diffusion models have demonstrated impressive capabilities in image quality. However, complex scene generation remains relatively unexplored, and even the definition of `complex scene' itself remains unclear. In this paper, we address this gap by providing a precise definition of complex scenes and introducing a set of Complex Decomposition Criteria (CDC) based on this definition. Inspired by the artists painting process, we propose a training-free diffusion framework called Complex Diffusion (CxD), which divides the process into three stages: composition, painting, and retouching. Our method leverages the powerful chain-of-thought capabilities of large language models (LLMs) to decompose complex prompts based on CDC and to manage composition and layout. We then develop an attention modulation method that guides simple prompts to specific regions to complete the complex scene painting. Finally, we inject the detailed output of the LLM into a retouching model to enhance the image details, thus implementing the retouching stage. Extensive experiments demonstrate that our method outperforms previous SOTA approaches, significantly improving the generation of high-quality, semantically consistent, and visually diverse images for complex scenes, even with intricate prompts.
D$^4$M: Dataset Distillation via Disentangled Diffusion Model
Jul 21, 2024



Dataset distillation offers a lightweight synthetic dataset for fast network training with promising test accuracy. To imitate the performance of the original dataset, most approaches employ bi-level optimization and the distillation space relies on the matching architecture. Nevertheless, these approaches either suffer significant computational costs on large-scale datasets or experience performance decline on cross-architectures. We advocate for designing an economical dataset distillation framework that is independent of the matching architectures. With empirical observations, we argue that constraining the consistency of the real and synthetic image spaces will enhance the cross-architecture generalization. Motivated by this, we introduce Dataset Distillation via Disentangled Diffusion Model (D$^4$M), an efficient framework for dataset distillation. Compared to architecture-dependent methods, D$^4$M employs latent diffusion model to guarantee consistency and incorporates label information into category prototypes. The distilled datasets are versatile, eliminating the need for repeated generation of distinct datasets for various architectures. Through comprehensive experiments, D$^4$M demonstrates superior performance and robust generalization, surpassing the SOTA methods across most aspects.
Message-passing selection: Towards interpretable GNNs for graph classification
Jun 08, 2023In this paper, we strive to develop an interpretable GNNs' inference paradigm, termed MSInterpreter, which can serve as a plug-and-play scheme readily applicable to various GNNs' baselines. Unlike the most existing explanation methods, MSInterpreter provides a Message-passing Selection scheme(MSScheme) to select the critical paths for GNNs' message aggregations, which aims at reaching the self-explaination instead of post-hoc explanations. In detail, the elaborate MSScheme is designed to calculate weight factors of message aggregation paths by considering the vanilla structure and node embedding components, where the structure base aims at weight factors among node-induced substructures; on the other hand, the node embedding base focuses on weight factors via node embeddings obtained by one-layer GNN.Finally, we demonstrate the effectiveness of our approach on graph classification benchmarks.
Multi-Prompt with Depth Partitioned Cross-Modal Learning
May 25, 2023In recent years, soft prompt learning methods have been proposed to fine-tune large-scale vision-language pre-trained models for various downstream tasks. These methods typically combine learnable textual tokens with class tokens as input for models with frozen parameters. However, they often employ a single prompt to describe class contexts, failing to capture categories' diverse attributes adequately. This study introduces the Partitioned Multi-modal Prompt (PMPO), a multi-modal prompting technique that extends the soft prompt from a single learnable prompt to multiple prompts. Our method divides the visual encoder depths and connects learnable prompts to the separated visual depths, enabling different prompts to capture the hierarchical contextual depths of visual representations. Furthermore, to maximize the advantages of multi-prompt learning, we incorporate prior information from manually designed templates and learnable multi-prompts, thus improving the generalization capabilities of our approach. We evaluate the effectiveness of our approach on three challenging tasks: new class generalization, cross-dataset evaluation, and domain generalization. For instance, our method achieves a $79.28$ harmonic mean, averaged over 11 diverse image recognition datasets ($+7.62$ compared to CoOp), demonstrating significant competitiveness compared to state-of-the-art prompting methods.
Learning to Incorporate Texture Saliency Adaptive Attention to Image Cartoonization
Aug 02, 2022
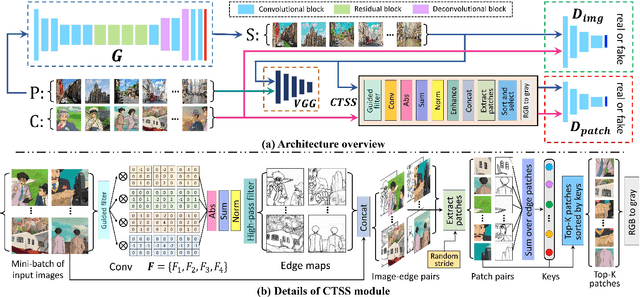
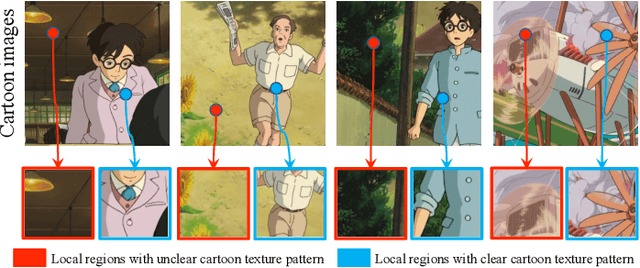
Image cartoonization is recently dominated by generative adversarial networks (GANs) from the perspective of unsupervised image-to-image translation, in which an inherent challenge is to precisely capture and sufficiently transfer characteristic cartoon styles (e.g., clear edges, smooth color shading, abstract fine structures, etc.). Existing advanced models try to enhance cartoonization effect by learning to promote edges adversarially, introducing style transfer loss, or learning to align style from multiple representation space. This paper demonstrates that more distinct and vivid cartoonization effect could be easily achieved with only basic adversarial loss. Observing that cartoon style is more evident in cartoon-texture-salient local image regions, we build a region-level adversarial learning branch in parallel with the normal image-level one, which constrains adversarial learning on cartoon-texture-salient local patches for better perceiving and transferring cartoon texture features. To this end, a novel cartoon-texture-saliency-sampler (CTSS) module is proposed to dynamically sample cartoon-texture-salient patches from training data. With extensive experiments, we demonstrate that texture saliency adaptive attention in adversarial learning, as a missing ingredient of related methods in image cartoonization, is of significant importance in facilitating and enhancing image cartoon stylization, especially for high-resolution input pictures.
* Proceedings of the 39th International Conference on Machine Learning, PMLR 162:7183-7207, 2022
Multi-view Feature Augmentation with Adaptive Class Activation Mapping
Jul 04, 2022
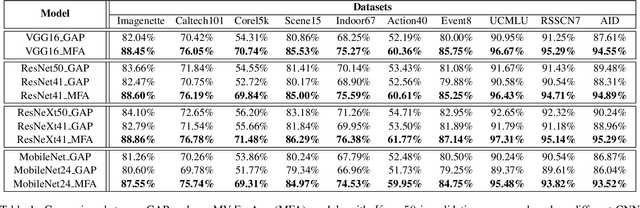
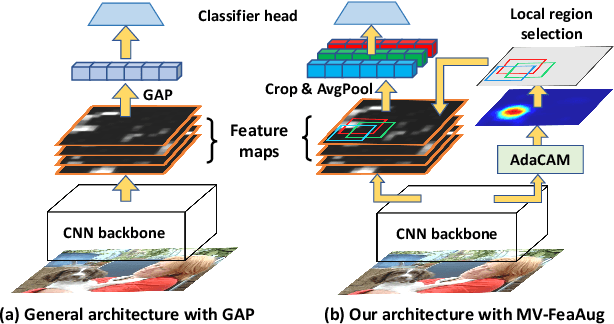
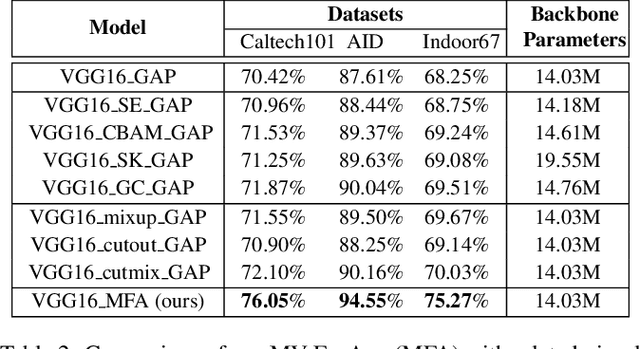
We propose an end-to-end-trainable feature augmentation module built for image classification that extracts and exploits multi-view local features to boost model performance. Different from using global average pooling (GAP) to extract vectorized features from only the global view, we propose to sample and ensemble diverse multi-view local features to improve model robustness. To sample class-representative local features, we incorporate a simple auxiliary classifier head (comprising only one 1$\times$1 convolutional layer) which efficiently and adaptively attends to class-discriminative local regions of feature maps via our proposed AdaCAM (Adaptive Class Activation Mapping). Extensive experiments demonstrate consistent and noticeable performance gains achieved by our multi-view feature augmentation module.
* Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI-21)
CarNet: A Lightweight and Efficient Encoder-Decoder Architecture for High-quality Road Crack Detection
Sep 13, 2021
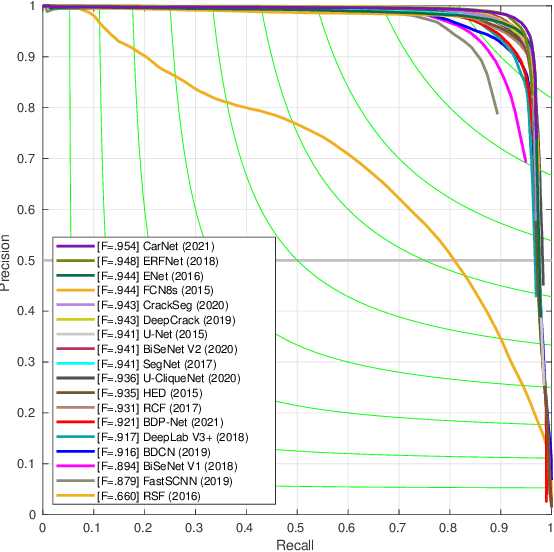
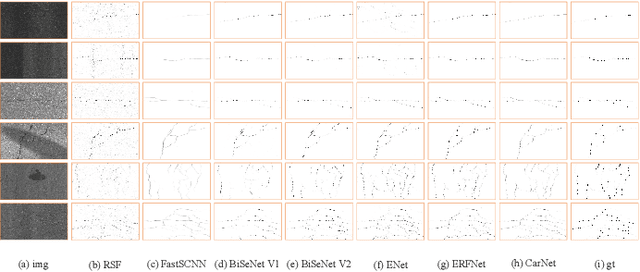
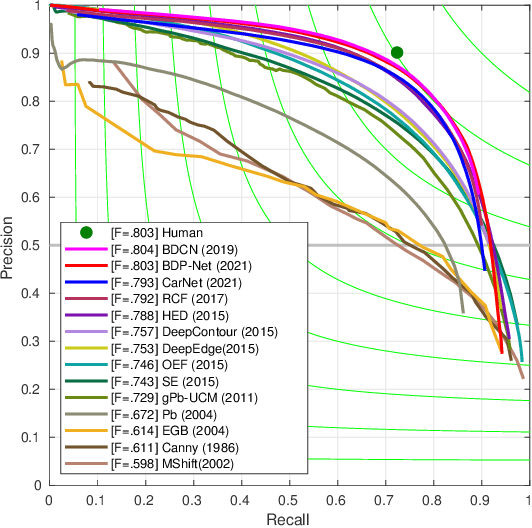
Pixel-wise crack detection is a challenging task because of poor continuity and low contrast in cracks. The existing frameworks usually employ complex models leading to good accuracy and yet low inference efficiency. In this paper, we present a lightweight encoder-decoder architecture, CarNet, for efficient and high-quality crack detection. To this end, we first propose that the ideal encoder should present an olive-type distribution about the number of convolutional layers at different stages. Specifically, as the network stages deepen in the encoder, the number of convolutional layers shows a downward trend after the model input is compressed in the initial network stage. Meanwhile, in the decoder, we introduce a lightweight up-sampling feature pyramid module to learn rich hierarchical features for crack detection. In particular, we compress the feature maps of the last three network stages to the same channels and then employ up-sampling with different multiples to resize them to the same resolutions for information fusion. Finally, extensive experiments on four public databases, i.e., Sun520, Rain365, BJN260, and Crack360, demonstrate that our CarNet gains a good trade-off between inference efficiency and test accuracy over the existing state-of-the-art methods.
Fast and Accurate Road Crack Detection Based on Adaptive Cost-Sensitive Loss Function
Jun 29, 2021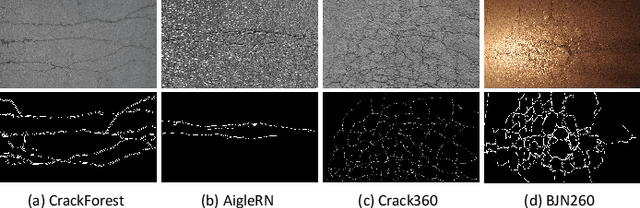


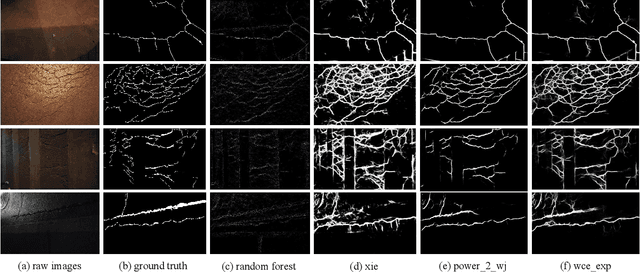
Numerous detection problems in computer vision, including road crack detection, suffer from exceedingly foreground-background imbalance. Fortunately, modification of loss function appears to solve this puzzle once and for all. In this paper, we propose a pixel-based adaptive weighted cross-entropy loss in conjunction with Jaccard distance to facilitate high-quality pixel-level road crack detection. Our work profoundly demonstrates the influence of loss functions on detection outcomes, and sheds light on the sophisticated consecutive improvements in the realm of crack detection. Specifically, to verify the effectiveness of the proposed loss, we conduct extensive experiments on four public databases, i.e., CrackForest, AigleRN, Crack360, and BJN260. Compared with the vanilla weighted cross-entropy, the proposed loss significantly speeds up the training process while retaining the test accuracy.
Two-stage Training for Learning from Label Proportions
May 22, 2021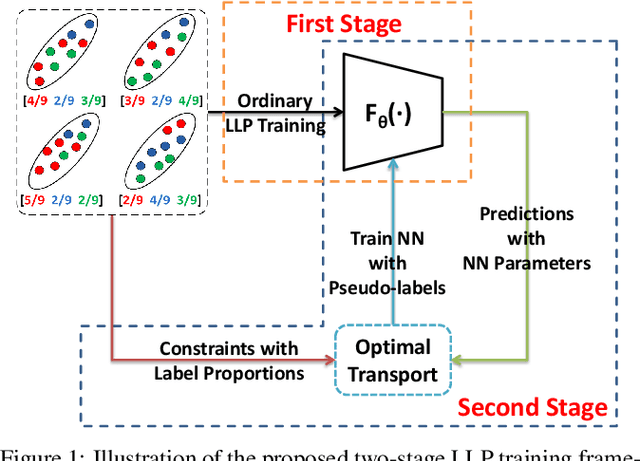
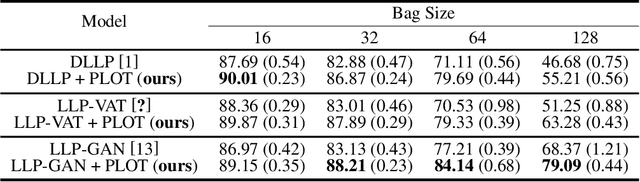
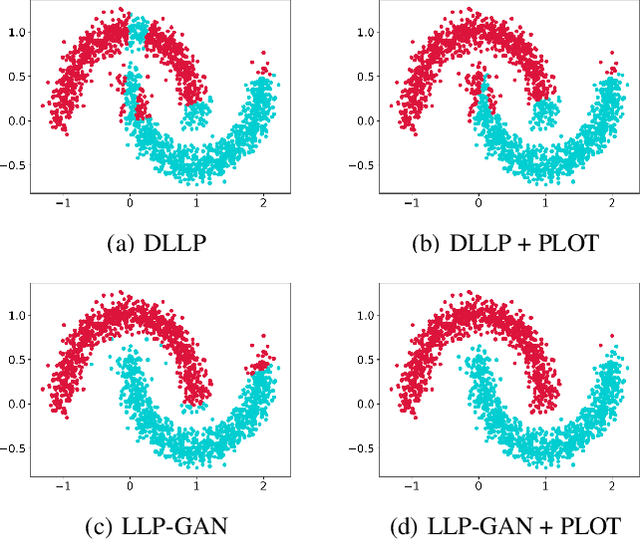
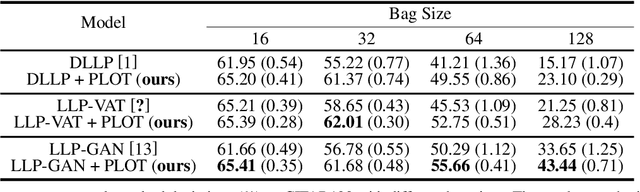
Learning from label proportions (LLP) aims at learning an instance-level classifier with label proportions in grouped training data. Existing deep learning based LLP methods utilize end-to-end pipelines to obtain the proportional loss with Kullback-Leibler divergence between the bag-level prior and posterior class distributions. However, the unconstrained optimization on this objective can hardly reach a solution in accordance with the given proportions. Besides, concerning the probabilistic classifier, this strategy unavoidably results in high-entropy conditional class distributions at the instance level. These issues further degrade the performance of the instance-level classification. In this paper, we regard these problems as noisy pseudo labeling, and instead impose the strict proportion consistency on the classifier with a constrained optimization as a continuous training stage for existing LLP classifiers. In addition, we introduce the mixup strategy and symmetric crossentropy to further reduce the label noise. Our framework is model-agnostic, and demonstrates compelling performance improvement in extensive experiments, when incorporated into other deep LLP models as a post-hoc phase.
Joint Ranking SVM and Binary Relevance with Robust Low-Rank Learning for Multi-Label Classification
Nov 05, 2019
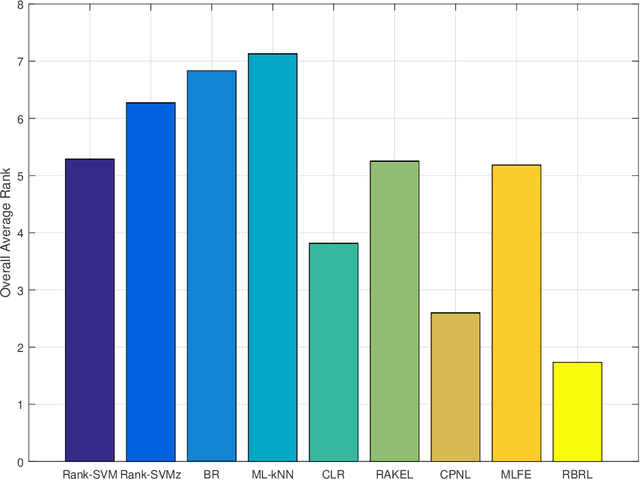

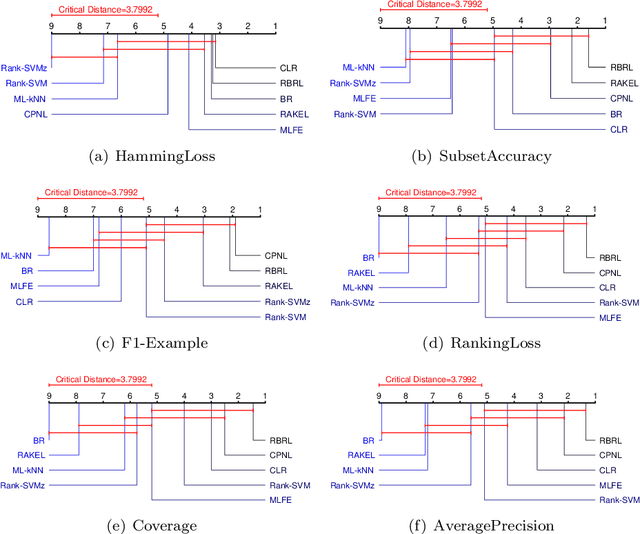
Multi-label classification studies the task where each example belongs to multiple labels simultaneously. As a representative method, Ranking Support Vector Machine (Rank-SVM) aims to minimize the Ranking Loss and can also mitigate the negative influence of the class-imbalance issue. However, due to its stacking-style way for thresholding, it may suffer error accumulation and thus reduces the final classification performance. Binary Relevance (BR) is another typical method, which aims to minimize the Hamming Loss and only needs one-step learning. Nevertheless, it might have the class-imbalance issue and does not take into account label correlations. To address the above issues, we propose a novel multi-label classification model, which joints Ranking support vector machine and Binary Relevance with robust Low-rank learning (RBRL). RBRL inherits the ranking loss minimization advantages of Rank-SVM, and thus overcomes the disadvantages of BR suffering the class-imbalance issue and ignoring the label correlations. Meanwhile, it utilizes the hamming loss minimization and one-step learning advantages of BR, and thus tackles the disadvantages of Rank-SVM including another thresholding learning step. Besides, a low-rank constraint is utilized to further exploit high-order label correlations under the assumption of low dimensional label space. Furthermore, to achieve nonlinear multi-label classifiers, we derive the kernelization RBRL. Two accelerated proximal gradient methods (APG) are used to solve the optimization problems efficiently. Extensive comparative experiments with several state-of-the-art methods illustrate a highly competitive or superior performance of our method RBRL.
* 57 pages, 5 figures, to be published in the journal of Neural Networks