 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Vision-Language-Action Models: An Action Tokenization Perspective
Jul 02, 2025The remarkable advancements of vision and language foundation models in multimodal understanding, reasoning, and generation has sparked growing efforts to extend such intelligence to the physical world, fueling the flourishing of vision-language-action (VLA) models. Despite seemingly diverse approaches, we observe that current VLA models can be unified under a single framework: vision and language inputs are processed by a series of VLA modules, producing a chain of \textit{action tokens} that progressively encode more grounded and actionable information, ultimately generating executable actions. We further determine that the primary design choice distinguishing VLA models lies in how action tokens are formulated, which can be categorized into language description, code, affordance, trajectory, goal state, latent representation, raw action, and reasoning. However, there remains a lack of comprehensive understanding regarding action tokens, significantly impeding effective VLA development and obscuring future directions. Therefore, this survey aims to categorize and interpret existing VLA research through the lens of action tokenization, distill the strengths and limitations of each token type, and identify areas for improvement. Through this systematic review and analysis, we offer a synthesized outlook on the broader evolution of VLA models, highlight underexplored yet promising directions, and contribute guidance for future research, hoping to bring the field closer to general-purpose intelligence.
Visual Anomaly Detection for Images: A Survey
Sep 27, 2021Visual anomaly detection is an important and challenging problem in the field of machine learning and computer vision. This problem has attracted a considerable amount of attention in relevant research communities. Especially in recent years, the development of deep learning has sparked an increasing interest in the visual anomaly detection problem and brought a great variety of novel methods. In this paper, we provide a comprehensive survey of the classical and deep learning-based approaches for visual anomaly detection in the literature. We group the relevant approaches in view of their underlying principles and discuss their assumptions, advantages, and disadvantages carefully. We aim to help the researchers to understand the common principles of visual anomaly detection approaches and identify promising research directions in this field.
CarNet: A Lightweight and Efficient Encoder-Decoder Architecture for High-quality Road Crack Detection
Sep 13, 2021
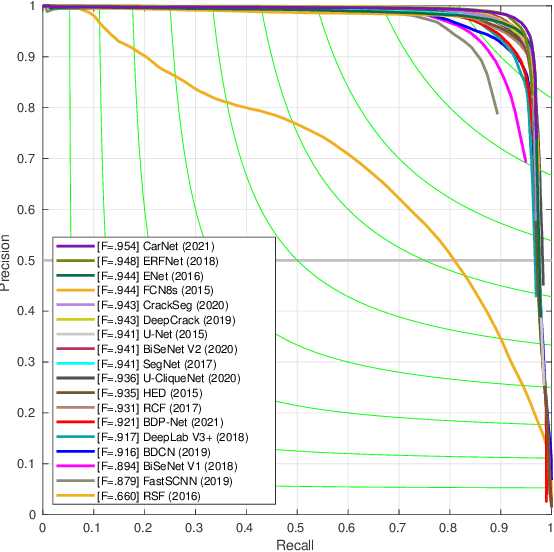
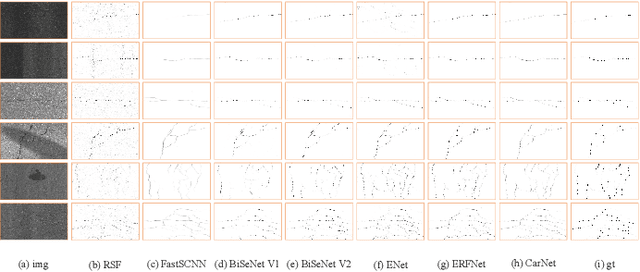
Pixel-wise crack detection is a challenging task because of poor continuity and low contrast in cracks. The existing frameworks usually employ complex models leading to good accuracy and yet low inference efficiency. In this paper, we present a lightweight encoder-decoder architecture, CarNet, for efficient and high-quality crack detection. To this end, we first propose that the ideal encoder should present an olive-type distribution about the number of convolutional layers at different stages. Specifically, as the network stages deepen in the encoder, the number of convolutional layers shows a downward trend after the model input is compressed in the initial network stage. Meanwhile, in the decoder, we introduce a lightweight up-sampling feature pyramid module to learn rich hierarchical features for crack detection. In particular, we compress the feature maps of the last three network stages to the same channels and then employ up-sampling with different multiples to resize them to the same resolutions for information fusion. Finally, extensive experiments on four public databases, i.e., Sun520, Rain365, BJN260, and Crack360, demonstrate that our CarNet gains a good trade-off between inference efficiency and test accuracy over the existing state-of-the-art methods.
Fast and Accurate Road Crack Detection Based on Adaptive Cost-Sensitive Loss Function
Jun 29, 2021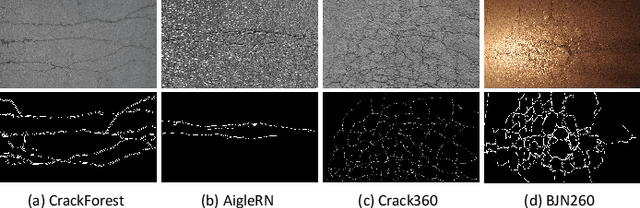


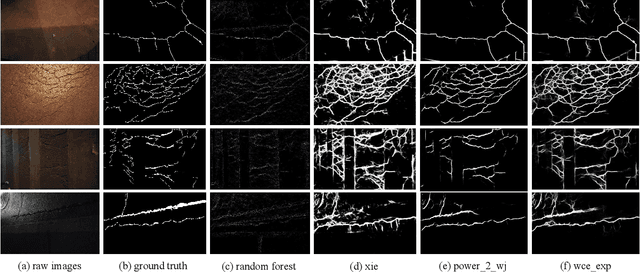
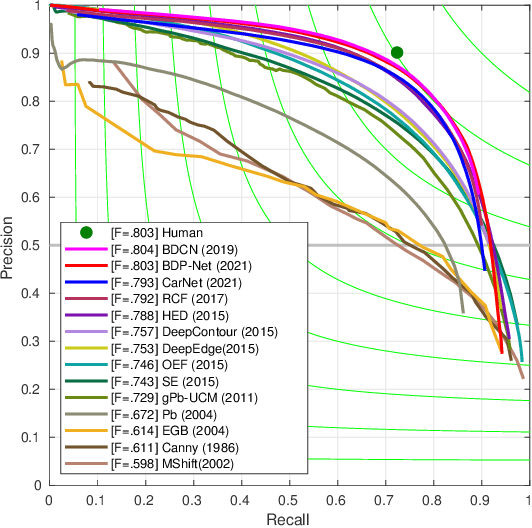
Numerous detection problems in computer vision, including road crack detection, suffer from exceedingly foreground-background imbalance. Fortunately, modification of loss function appears to solve this puzzle once and for all. In this paper, we propose a pixel-based adaptive weighted cross-entropy loss in conjunction with Jaccard distance to facilitate high-quality pixel-level road crack detection. Our work profoundly demonstrates the influence of loss functions on detection outcomes, and sheds light on the sophisticated consecutive improvements in the realm of crack detection. Specifically, to verify the effectiveness of the proposed loss, we conduct extensive experiments on four public databases, i.e., CrackForest, AigleRN, Crack360, and BJN260. Compared with the vanilla weighted cross-entropy, the proposed loss significantly speeds up the training process while retaining the test accuracy.
Two-stage Training for Learning from Label Proportions
May 22, 2021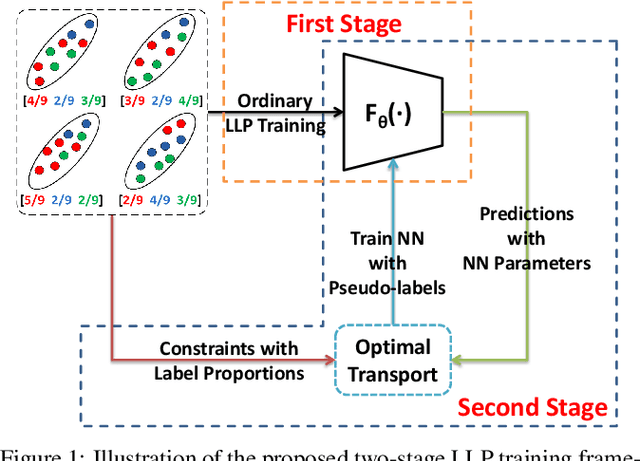
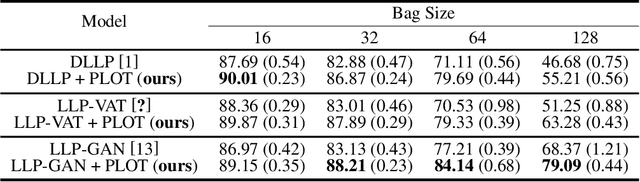
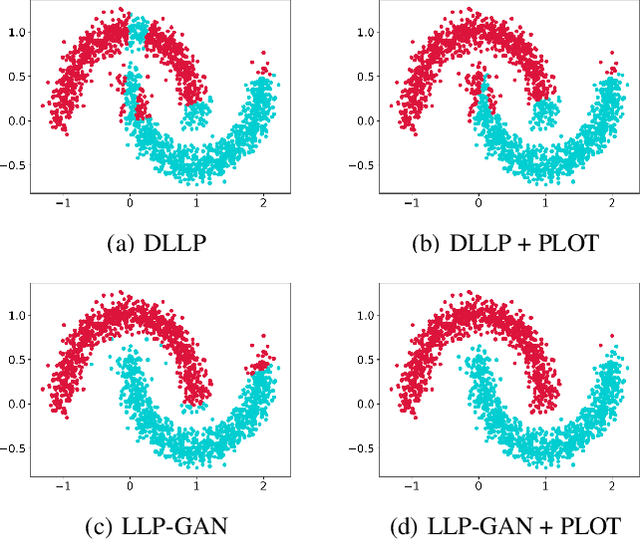
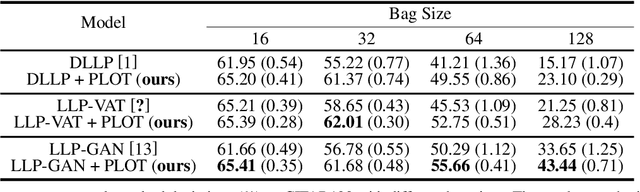
Learning from label proportions (LLP) aims at learning an instance-level classifier with label proportions in grouped training data. Existing deep learning based LLP methods utilize end-to-end pipelines to obtain the proportional loss with Kullback-Leibler divergence between the bag-level prior and posterior class distributions. However, the unconstrained optimization on this objective can hardly reach a solution in accordance with the given proportions. Besides, concerning the probabilistic classifier, this strategy unavoidably results in high-entropy conditional class distributions at the instance level. These issues further degrade the performance of the instance-level classification. In this paper, we regard these problems as noisy pseudo labeling, and instead impose the strict proportion consistency on the classifier with a constrained optimization as a continuous training stage for existing LLP classifiers. In addition, we introduce the mixup strategy and symmetric crossentropy to further reduce the label noise. Our framework is model-agnostic, and demonstrates compelling performance improvement in extensive experiments, when incorporated into other deep LLP models as a post-hoc phase.
DFR: Deep Feature Reconstruction for Unsupervised Anomaly Segmentation
Dec 13, 2020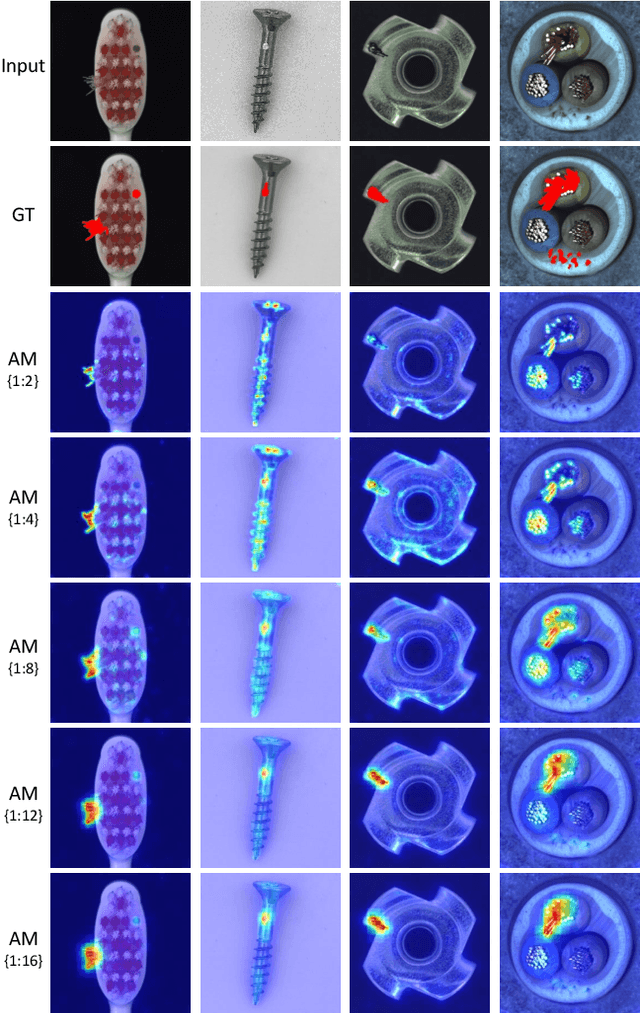
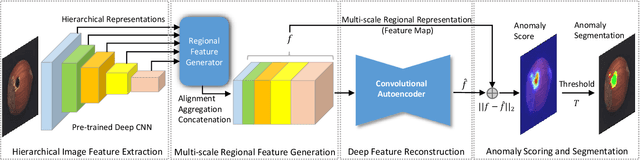
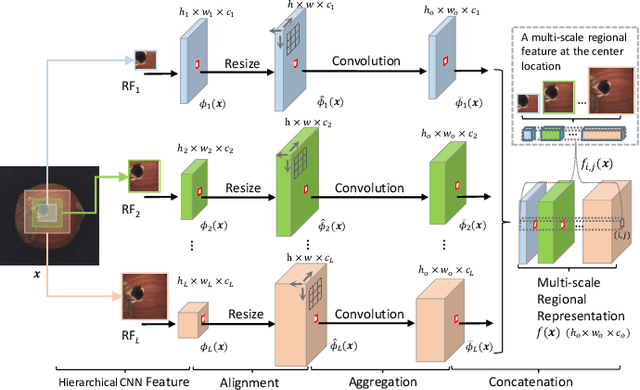
Automatic detecting anomalous regions in images of objects or textures without priors of the anomalies is challenging, especially when the anomalies appear in very small areas of the images, making difficult-to-detect visual variations, such as defects on manufacturing products. This paper proposes an effective unsupervised anomaly segmentation approach that can detect and segment out the anomalies in small and confined regions of images. Concretely, we develop a multi-scale regional feature generator that can generate multiple spatial context-aware representations from pre-trained deep convolutional networks for every subregion of an image. The regional representations not only describe the local characteristics of corresponding regions but also encode their multiple spatial context information, making them discriminative and very beneficial for anomaly detection. Leveraging these descriptive regional features, we then design a deep yet efficient convolutional autoencoder and detect anomalous regions within images via fast feature reconstruction. Our method is simple yet effective and efficient. It advances the state-of-the-art performances on several benchmark datasets and shows great potential for real applications.
Learning to Incorporate Structure Knowledge for Image Inpainting
Feb 12, 2020
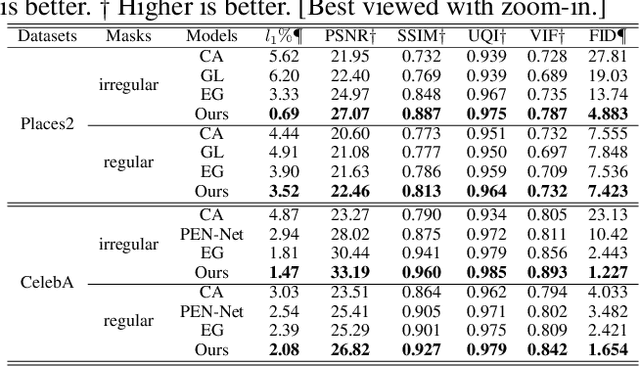
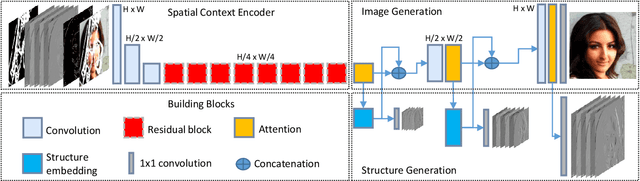
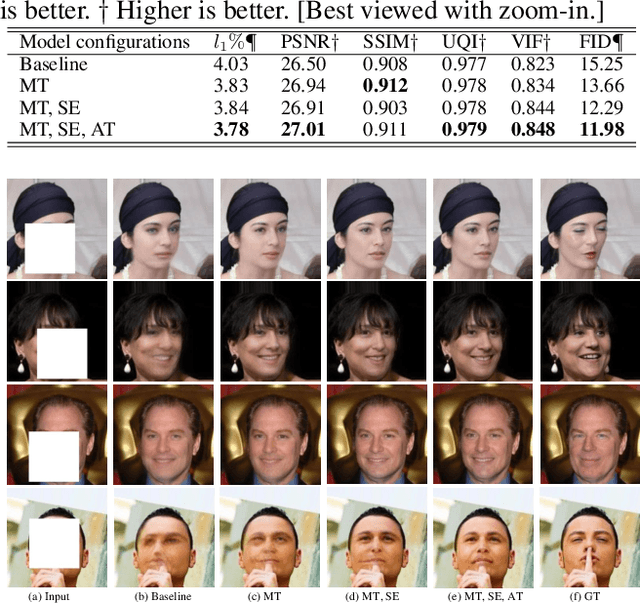
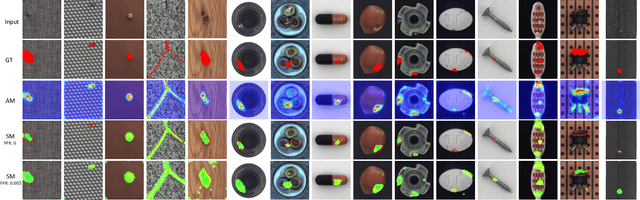
This paper develops a multi-task learning framework that attempts to incorporate the image structure knowledge to assist image inpainting, which is not well explored in previous works. The primary idea is to train a shared generator to simultaneously complete the corrupted image and corresponding structures --- edge and gradient, thus implicitly encouraging the generator to exploit relevant structure knowledge while inpainting. In the meantime, we also introduce a structure embedding scheme to explicitly embed the learned structure features into the inpainting process, thus to provide possible preconditions for image completion. Specifically, a novel pyramid structure loss is proposed to supervise structure learning and embedding. Moreover, an attention mechanism is developed to further exploit the recurrent structures and patterns in the image to refine the generated structures and contents. Through multi-task learning, structure embedding besides with attention, our framework takes advantage of the structure knowledge and outperforms several state-of-the-art methods on benchmark datasets quantitatively and qualitatively.
s-LWSR: Super Lightweight Super-Resolution Network
Sep 24, 2019
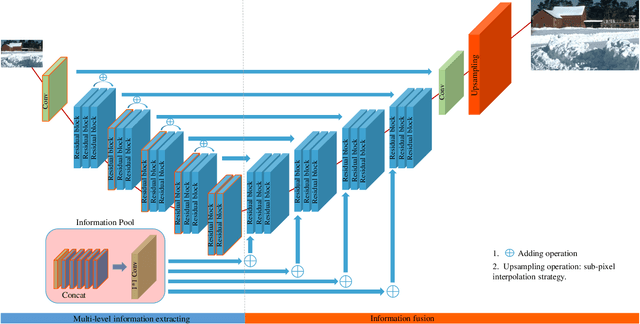
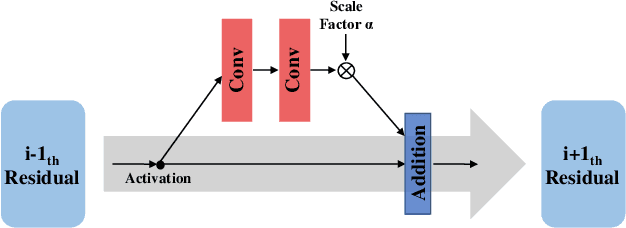
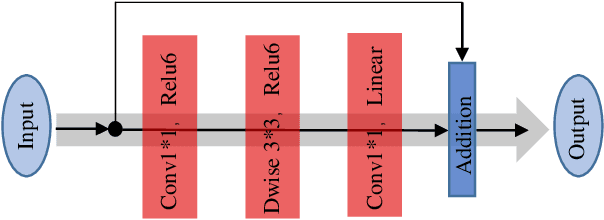
Deep learning (DL) architectures for superresolution (SR) normally contain tremendous parameters, which has been regarded as the crucial advantage for obtaining satisfying performance. However, with the widespread use of mobile phones for taking and retouching photos, this character greatly hampers the deployment of DL-SR models on the mobile devices. To address this problem, in this paper, we propose a super lightweight SR network: s-LWSR. There are mainly three contributions in our work. Firstly, in order to efficiently abstract features from the low resolution image, we build an information pool to mix multi-level information from the first half part of the pipeline. Accordingly, the information pool feeds the second half part with the combination of hierarchical features from the previous layers. Secondly, we employ a compression module to further decrease the size of parameters. Intensive analysis confirms its capacity of trade-off between model complexity and accuracy. Thirdly, by revealing the specific role of activation in deep models, we remove several activation layers in our SR model to retain more information for performance improvement. Extensive experiments show that our s-LWSR, with limited parameters and operations, can achieve similar performance to other cumbersome DL-SR methods.
Learning from Label Proportions with Generative Adversarial Networks
Sep 05, 2019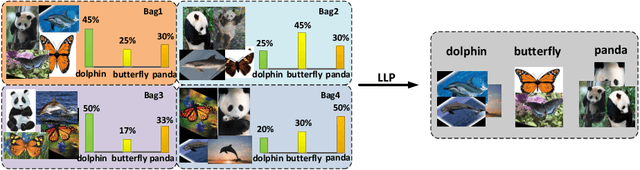
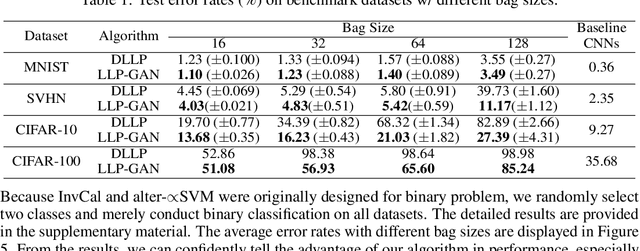
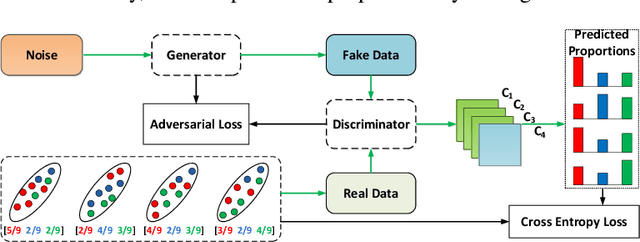
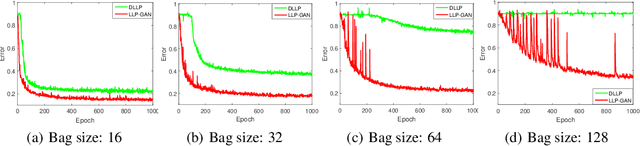
In this paper, we leverage generative adversarial networks (GANs) to derive an effective algorithm LLP-GAN for learning from label proportions (LLP), where only the bag-level proportional information in labels is available. Endowed with end-to-end structure, LLP-GAN performs approximation in the light of an adversarial learning mechanism, without imposing restricted assumptions on distribution. Accordingly, we can directly induce the final instance-level classifier upon the discriminator. Under mild assumptions, we give the explicit generative representation and prove the global optimality for LLP-GAN. Additionally, compared with existing methods, our work empowers LLP solver with capable scalability inheriting from deep models. Several experiments on benchmark datasets demonstrate vivid advantages of the proposed approach.