 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Field Generation Based on Hybrid Mamba-Transformer with Physics-informed Fine-tuning
May 16, 2025This research confronts the challenge of substantial physical equation discrepancies encountered in the generation of spatiotemporal physical fields through data-driven trained models. A spatiotemporal physical field generation model, named HMT-PF, is developed based on the hybrid Mamba-Transformer architecture, incorporating unstructured grid information as input. A fine-tuning block, enhanced with physical information, is introduced to effectively reduce the physical equation discrepancies. The physical equation residuals are computed through a point query mechanism for efficient gradient evaluation, then encoded into latent space for refinement. The fine-tuning process employs a self-supervised learning approach to achieve physical consistency while maintaining essential field characteristics. Results show that the hybrid Mamba-Transformer model achieves good performance in generating spatiotemporal fields, while the physics-informed fine-tuning mechanism further reduces significant physical errors effectively. A MSE-R evaluation method is developed to assess the accuracy and realism of physical field generation.
Replacement Learning: Training Vision Tasks with Fewer Learnable Parameters
Oct 02, 2024



Traditional end-to-end deep learning models often enhance feature representation and overall performance by increasing the depth and complexity of the network during training. However, this approach inevitably introduces issues of parameter redundancy and resource inefficiency, especially in deeper networks. While existing works attempt to skip certain redundant layers to alleviate these problems, challenges related to poor performance, computational complexity, and inefficient memory usage remain. To address these issues, we propose an innovative training approach called Replacement Learning, which mitigates these limitations by completely replacing all the parameters of the frozen layers with only two learnable parameters. Specifically, Replacement Learning selectively freezes the parameters of certain layers, and the frozen layers utilize parameters from adjacent layers, updating them through a parameter integration mechanism controlled by two learnable parameters. This method leverages information from surrounding structures, reduces computation, conserves GPU memory, and maintains a balance between historical context and new inputs, ultimately enhancing overall model performance. We conducted experiments across four benchmark datasets, including CIFAR-10, STL-10, SVHN, and ImageNet, utilizing various architectures such as CNNs and ViTs to validate the effectiveness of Replacement Learning. Experimental results demonstrate that our approach reduces the number of parameters, training time, and memory consumption while completely surpassing the performance of end-to-end training.
GSO-YOLO: Global Stability Optimization YOLO for Construction Site Detection
Jul 01, 2024



Safety issues at construction sites have long plagued the industry, posing risks to worker safety and causing economic damage due to potential hazards. With the advancement of artificial intelligence, particularly in the field of computer vision, the automation of safety monitoring on construction sites has emerged as a solution to this longstanding issue. Despite achieving impressive performance, advanced object detection methods like YOLOv8 still face challenges in handling the complex conditions found at construction sites. To solve these problems, this study presents the Global Stability Optimization YOLO (GSO-YOLO) model to address challenges in complex construction sites. The model integrates the Global Optimization Module (GOM) and Steady Capture Module (SCM) to enhance global contextual information capture and detection stability. The innovative AIoU loss function, which combines CIoU and EIoU, improves detection accuracy and efficiency. Experiments on datasets like SODA, MOCS, and CIS show that GSO-YOLO outperforms existing methods, achieving SOTA performance.
MLAAN: Scaling Supervised Local Learning with Multilaminar Leap Augmented Auxiliary Network
Jun 24, 2024End-to-end (E2E) training approaches are commonly plagued by high memory consumption, reduced efficiency in training, challenges in model parallelization, and suboptimal biocompatibility. Local learning is considered a novel interactive training method that holds promise as an alternative to E2E. Nonetheless, conventional local learning methods fall short in achieving high model accuracy due to inadequate local inter-module interactions. In this paper, we introduce a new model known as the Scaling Supervised Local Learning with Multilaminar Leap Augmented Auxiliary Network (MLAAN). MLAAN features an innovative supervised local learning approach coupled with a robust reinforcement module. This dual-component design enables the MLAAN to integrate smoothly with established local learning techniques, thereby enhancing the efficacy of the foundational methods. The method simultaneously acquires the local and global features of the model separately by constructing an independent auxiliary network and a cascade auxiliary network on the one hand and incorporates a leap augmented module, which serves to counteract the reduced learning capacity often associated with weaker supervision. This architecture not only augments the exchange of information amongst the local modules but also effectively mitigates the model's tendency toward myopia. The experimental evaluations conducted on four benchmark datasets, CIFAR-10, STL-10, SVHN, and ImageNet, demonstrate that the integration of MLAAN with existing supervised local learning methods significantly enhances the original methodologies. Of particular note, MLAAN enables local learning methods to comprehensively outperform end-to-end training approaches in terms of optimal performance while saving GPU memory.
Class Information Guided Reconstruction for Automatic Modulation Open-Set Recognition
Dec 20, 2023Automatic Modulation Recognition (AMR) is a crucial technology in the domains of radar and communications. Traditional AMR approaches assume a closed-set scenario, where unknown samples are forcibly misclassified into known classes, leading to serious consequences for situation awareness and threat assessment. To address this issue, Automatic Modulation Open-set Recognition (AMOSR) defines two tasks as Known Class Classification (KCC) and Unknown Class Identification (UCI). However, AMOSR faces core challenges in terms of inappropriate decision boundaries and sparse feature distributions. To overcome the aforementioned challenges, we propose a Class Information guided Reconstruction (CIR) framework, which leverages reconstruction losses to distinguish known and unknown classes. To enhance distinguishability, we design Class Conditional Vectors (CCVs) to match the latent representations extracted from input samples, achieving perfect reconstruction for known samples while yielding poor results for unknown ones. We also propose a Mutual Information (MI) loss function to ensure reliable matching, with upper and lower bounds of MI derived for tractable optimization and mathematical proofs provided. The mutually beneficial CCVs and MI facilitate the CIR attaining optimal UCI performance without compromising KCC accuracy, especially in scenarios with a higher proportion of unknown classes. Additionally, a denoising module is introduced before reconstruction, enabling the CIR to achieve a significant performance improvement at low SNRs. Experimental results on simulated and measured signals validate the effectiveness and the robustness of the proposed method.
SAM: A Self-adaptive Attention Module for Context-Aware Recommendation System
Oct 13, 2021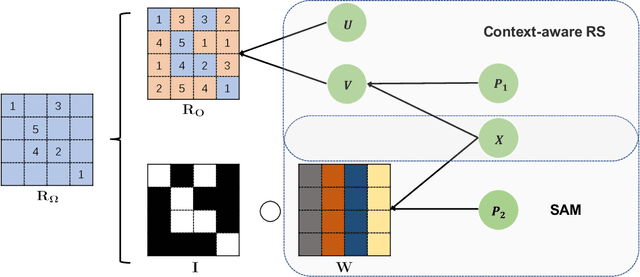
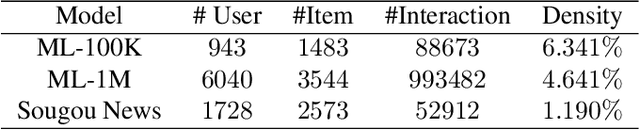
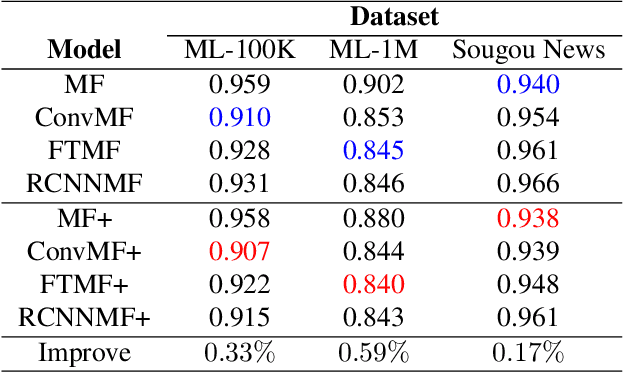
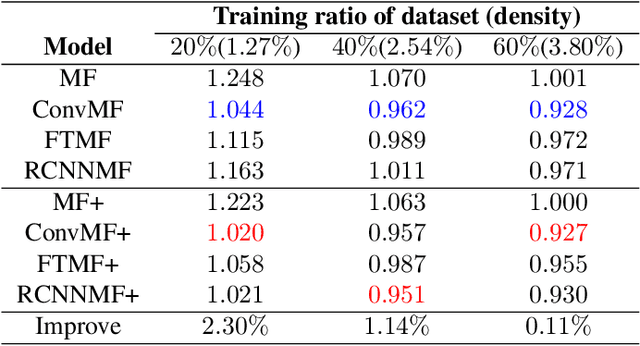
Recently, textual information has been proved to play a positive role in recommendation systems. However, most of the existing methods only focus on representation learning of textual information in ratings, while potential selection bias induced by the textual information is ignored. In this work, we propose a novel and general self-adaptive module, the Self-adaptive Attention Module (SAM), which adjusts the selection bias by capturing contextual information based on its representation. This module can be embedded into recommendation systems that contain learning components of contextual information. Experimental results on three real-world datasets demonstrate the effectiveness of our proposal, and the state-of-the-art models with SAM significantly outperform the original ones.
Leveraged Weighted Loss for Partial Label Learning
Jun 10, 2021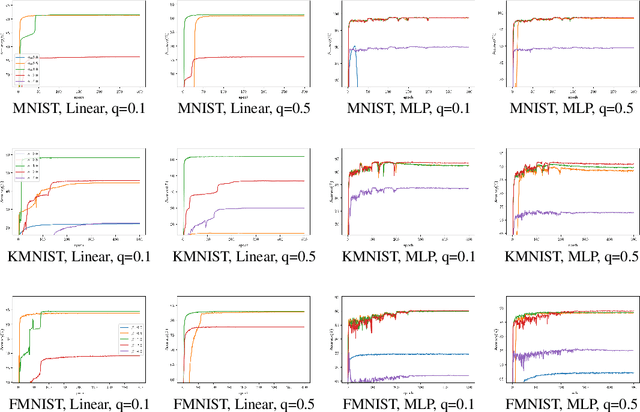
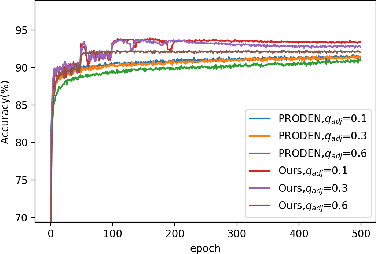
As an important branch of weakly supervised learning, partial label learning deals with data where each instance is assigned with a set of candidate labels, whereas only one of them is true. Despite many methodology studies on learning from partial labels, there still lacks theoretical understandings of their risk consistent properties under relatively weak assumptions, especially on the link between theoretical results and the empirical choice of parameters. In this paper, we propose a family of loss functions named \textit{Leveraged Weighted} (LW) loss, which for the first time introduces the leverage parameter $\beta$ to consider the trade-off between losses on partial labels and non-partial ones. From the theoretical side, we derive a generalized result of risk consistency for the LW loss in learning from partial labels, based on which we provide guidance to the choice of the leverage parameter $\beta$. In experiments, we verify the theoretical guidance, and show the high effectiveness of our proposed LW loss on both benchmark and real datasets compared with other state-of-the-art partial label learning algorithms.
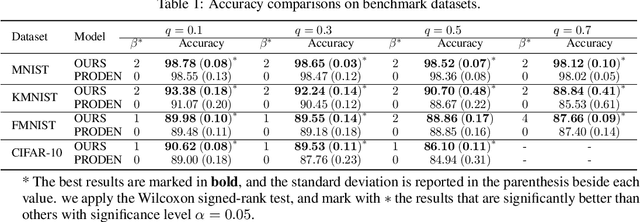
Two-stage Training for Learning from Label Proportions
May 22, 2021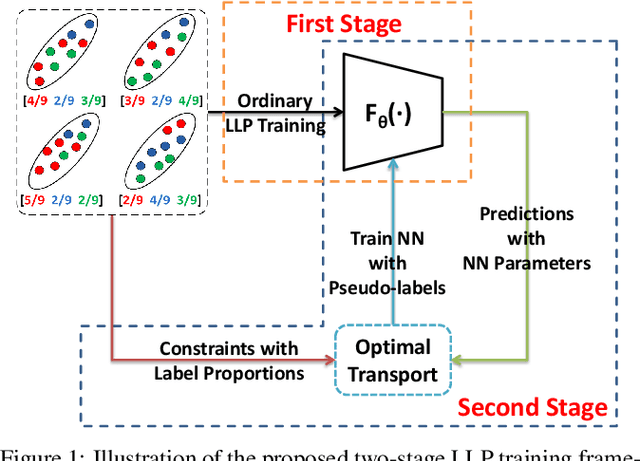
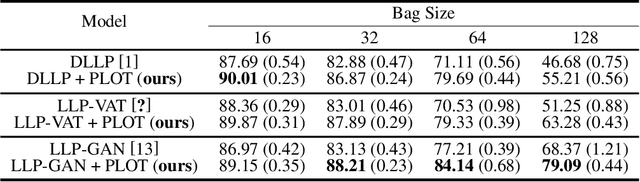
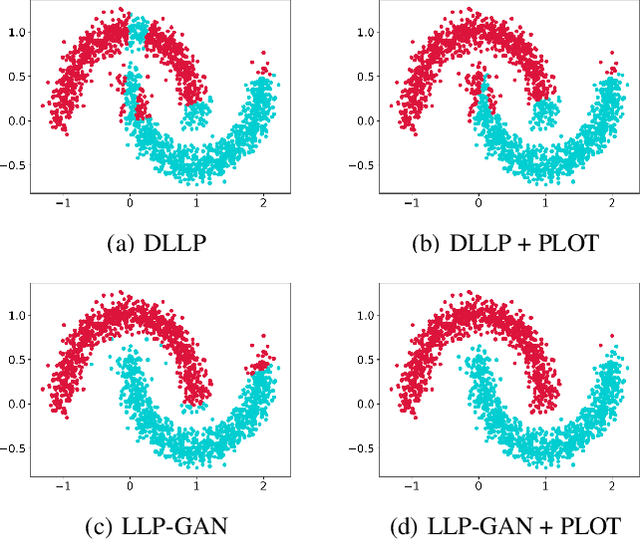
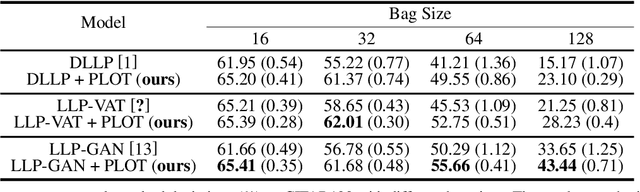
Learning from label proportions (LLP) aims at learning an instance-level classifier with label proportions in grouped training data. Existing deep learning based LLP methods utilize end-to-end pipelines to obtain the proportional loss with Kullback-Leibler divergence between the bag-level prior and posterior class distributions. However, the unconstrained optimization on this objective can hardly reach a solution in accordance with the given proportions. Besides, concerning the probabilistic classifier, this strategy unavoidably results in high-entropy conditional class distributions at the instance level. These issues further degrade the performance of the instance-level classification. In this paper, we regard these problems as noisy pseudo labeling, and instead impose the strict proportion consistency on the classifier with a constrained optimization as a continuous training stage for existing LLP classifiers. In addition, we introduce the mixup strategy and symmetric crossentropy to further reduce the label noise. Our framework is model-agnostic, and demonstrates compelling performance improvement in extensive experiments, when incorporated into other deep LLP models as a post-hoc phase.
s-LWSR: Super Lightweight Super-Resolution Network
Sep 24, 2019
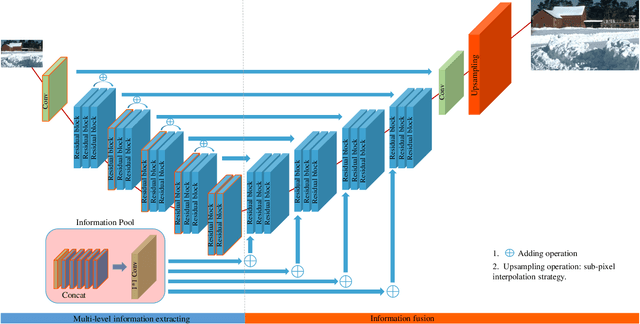
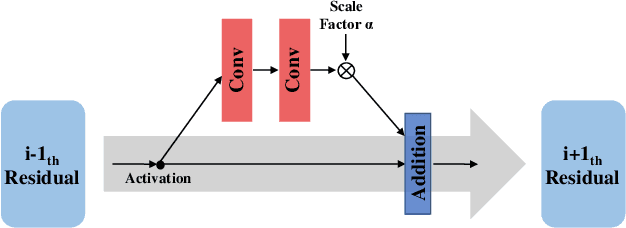
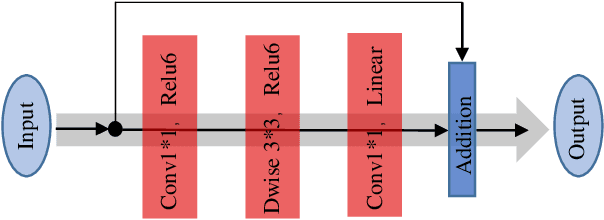
Deep learning (DL) architectures for superresolution (SR) normally contain tremendous parameters, which has been regarded as the crucial advantage for obtaining satisfying performance. However, with the widespread use of mobile phones for taking and retouching photos, this character greatly hampers the deployment of DL-SR models on the mobile devices. To address this problem, in this paper, we propose a super lightweight SR network: s-LWSR. There are mainly three contributions in our work. Firstly, in order to efficiently abstract features from the low resolution image, we build an information pool to mix multi-level information from the first half part of the pipeline. Accordingly, the information pool feeds the second half part with the combination of hierarchical features from the previous layers. Secondly, we employ a compression module to further decrease the size of parameters. Intensive analysis confirms its capacity of trade-off between model complexity and accuracy. Thirdly, by revealing the specific role of activation in deep models, we remove several activation layers in our SR model to retain more information for performance improvement. Extensive experiments show that our s-LWSR, with limited parameters and operations, can achieve similar performance to other cumbersome DL-SR methods.
Learning from Label Proportions with Generative Adversarial Networks
Sep 05, 2019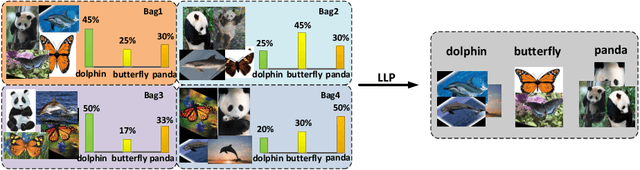
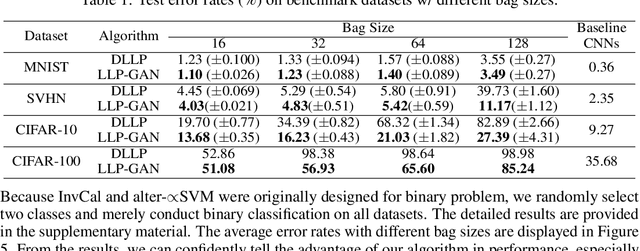
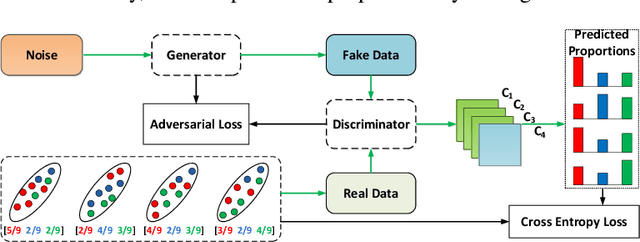
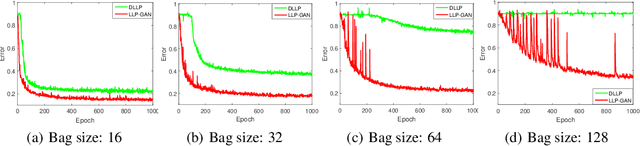
In this paper, we leverage generative adversarial networks (GANs) to derive an effective algorithm LLP-GAN for learning from label proportions (LLP), where only the bag-level proportional information in labels is available. Endowed with end-to-end structure, LLP-GAN performs approximation in the light of an adversarial learning mechanism, without imposing restricted assumptions on distribution. Accordingly, we can directly induce the final instance-level classifier upon the discriminator. Under mild assumptions, we give the explicit generative representation and prove the global optimality for LLP-GAN. Additionally, compared with existing methods, our work empowers LLP solver with capable scalability inheriting from deep models. Several experiments on benchmark datasets demonstrate vivid advantages of the proposed approach.