 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bias-Correction Decentralized Stochastic Gradient Algorithm with Momentum Acceleration
Jan 31, 2025



Distributed stochastic optimization algorithms can handle large-scale data simultaneously and accelerate model training. However, the sparsity of distributed networks and the heterogeneity of data limit these advantages. This paper proposes a momentum-accelerated distributed stochastic gradient algorithm, referred to as Exact-Diffusion with Momentum (EDM), which can correct the bias caused by data heterogeneity and introduces the momentum method commonly used in deep learning to accelerate the convergence of the algorithm. We theoretically demonstrate that this algorithm converges to the neighborhood of the optimum sub-linearly irrelevant to data heterogeneity when applied to non-convex objective functions and linearly under the Polyak-{\L}ojasiewicz condition (a weaker assumption than $\mu$-strongly convexity). Finally, we evaluate the performance of the proposed algorithm by simulation, comparing it with a range of existing decentralized optimization algorithms to demonstrate its effectiveness in addressing data heterogeneity and network sparsity.
Mixed Matrix Completion in Complex Survey Sampling under Heterogeneous Missingness
Feb 06, 2024Modern surveys with large sample sizes and growing mixed-type questionnaires require robust and scalable analysis methods. In this work, we consider recovering a mixed dataframe matrix, obtained by complex survey sampling, with entries following different canonical exponential distributions and subject to heterogeneous missingness. To tackle this challenging task, we propose a two-stage procedure: in the first stage, we model the entry-wise missing mechanism by logistic regression, and in the second stage, we complete the target parameter matrix by maximizing a weighted log-likelihood with a low-rank constraint. We propose a fast and scalable estimation algorithm that achieves sublinear convergence, and the upper bound for the estimation error of the proposed method is rigorously derived. Experimental results support our theoretical claims, and the proposed estimator shows its merits compared to other existing methods. The proposed method is applied to analyze the National Health and Nutrition Examination Survey data.
Efficient Sparse Least Absolute Deviation Regression with Differential Privacy
Jan 02, 2024



In recent years, privacy-preserving machine learning algorithms have attracted increasing attention because of their important applications in many scientific fields. However, in the literature, most privacy-preserving algorithms demand learning objectives to be strongly convex and Lipschitz smooth, which thus cannot cover a wide class of robust loss functions (e.g., quantile/least absolute loss). In this work, we aim to develop a fast privacy-preserving learning solution for a sparse robust regression problem. Our learning loss consists of a robust least absolute loss and an $\ell_1$ sparse penalty term. To fast solve the non-smooth loss under a given privacy budget, we develop a Fast Robust And Privacy-Preserving Estimation (FRAPPE) algorithm for least absolute deviation regression. Our algorithm achieves a fast estimation by reformulating the sparse LAD problem as a penalized least square estimation problem and adopts a three-stage noise injection to guarantee the $(\epsilon,\delta)$-differential privacy. We show that our algorithm can achieve better privacy and statistical accuracy trade-off compared with the state-of-the-art privacy-preserving regression algorithms. In the end, we conduct experiments to verify the efficiency of our proposed FRAPPE algorithm.
Distributed Semi-Supervised Sparse Statistical Inference
Jun 17, 2023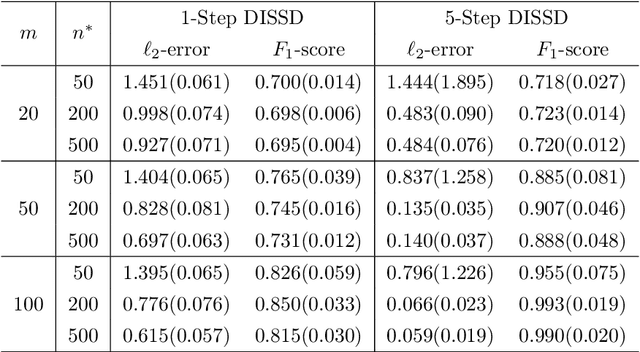
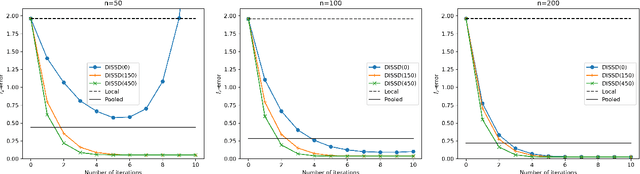
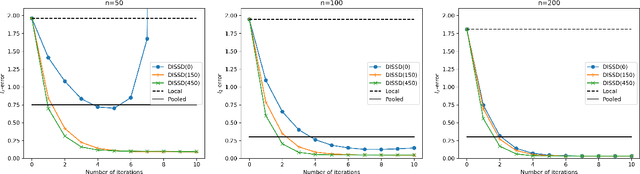
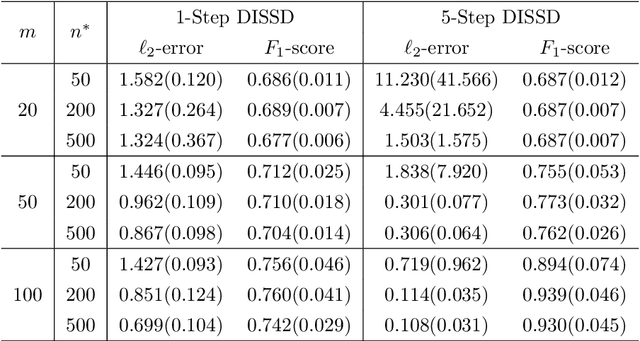
This paper is devoted to studying the semi-supervised sparse statistical inference in a distributed setup. An efficient multi-round distributed debiased estimator, which integrates both labeled and unlabelled data, is developed. We will show that the additional unlabeled data helps to improve the statistical rate of each round of iteration. Our approach offers tailored debiasing methods for $M$-estimation and generalized linear model according to the specific form of the loss function. Our method also applies to a non-smooth loss like absolute deviation loss. Furthermore, our algorithm is computationally efficient since it requires only one estimation of a high-dimensional inverse covariance matrix. We demonstrate the effectiveness of our method by presenting simulation studies and real data applications that highlight the benefits of incorporating unlabeled data.
Transductive Matrix Completion with Calibration for Multi-Task Learning
Feb 20, 2023



Multi-task learning has attracted much attention due to growing multi-purpose research with multiple related data sources. Moreover, transduction with matrix completion is a useful method in multi-label learning. In this paper, we propose a transductive matrix completion algorithm that incorporates a calibration constraint for the features under the multi-task learning framework. The proposed algorithm recovers the incomplete feature matrix and target matrix simultaneously. Fortunately, the calibration information improves the completion results. In particular, we provide a statistical guarantee for the proposed algorithm, and the theoretical improvement induced by calibration information is also studied. Moreover, the proposed algorithm enjoys a sub-linear convergence rate. Several synthetic data experiments are conducted, which show the proposed algorithm out-performs other existing methods, especially when the target matrix is associated with the feature matrix in a nonlinear way.
Majority Vote for Distributed Differentially Private Sign Selection
Sep 08, 2022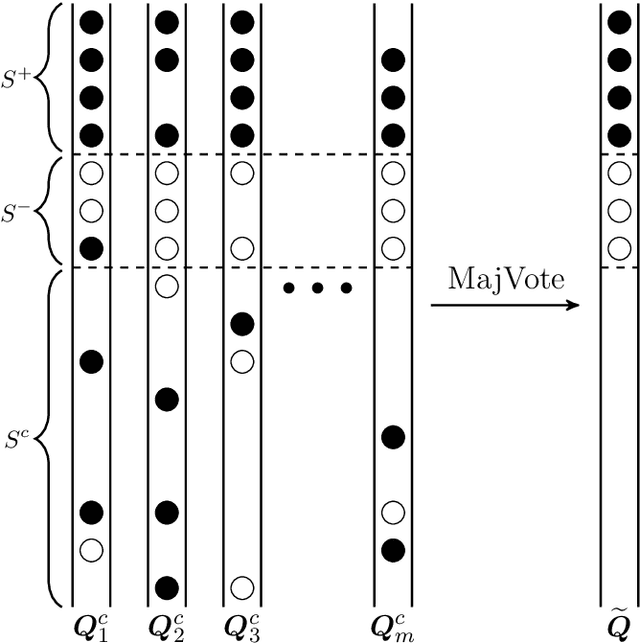
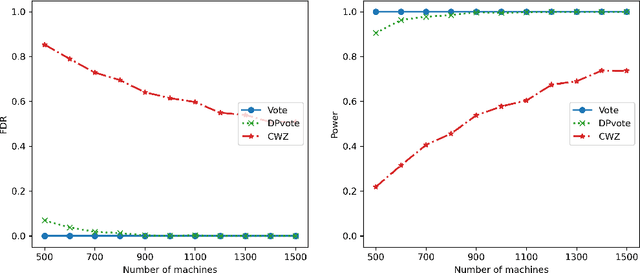
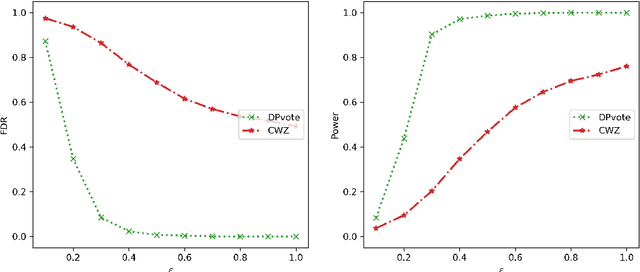
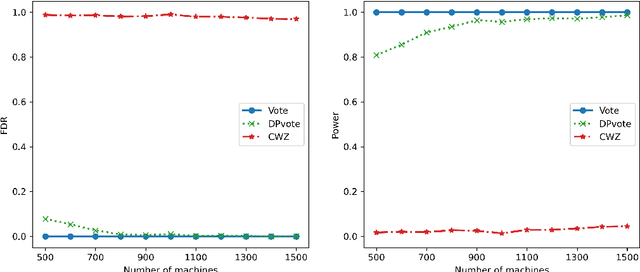
Privacy-preserving data analysis has become prevailing in recent years. In this paper, we propose a distributed group differentially private majority vote mechanism for the sign selection problem in a distributed setup. To achieve this, we apply the iterative peeling to the stability function and use the exponential mechanism to recover the signs. As applications, we study the private sign selection for mean estimation and linear regression problems in distributed systems. Our method recovers the support and signs with the optimal signal-to-noise ratio as in the non-private scenario, which is better than contemporary works of private variable selections. Moreover, the sign selection consistency is justified with theoretical guarantees. Simulation studies are conducted to demonstrate the effectiveness of our proposed method.
Fast and Robust Sparsity Learning over Networks: A Decentralized Surrogate Median Regression Approach
Feb 11, 2022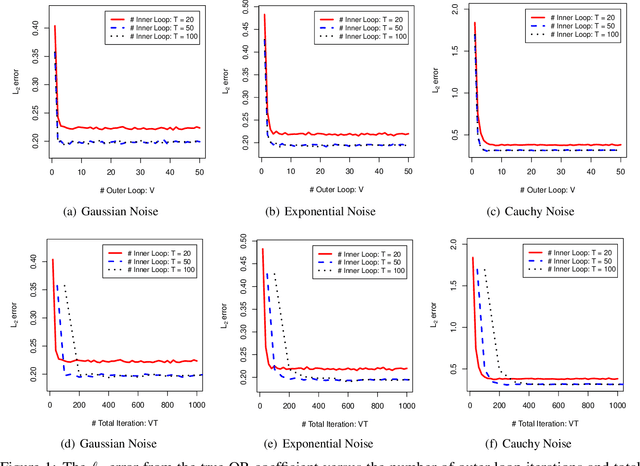
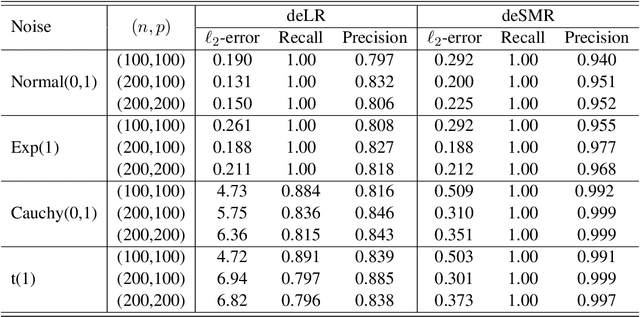
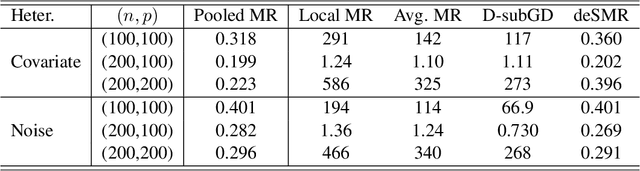
Decentralized sparsity learning has attracted a significant amount of attention recently due to its rapidly growing applications. To obtain the robust and sparse estimators, a natural idea is to adopt the non-smooth median loss combined with a $\ell_1$ sparsity regularizer. However, most of the existing methods suffer from slow convergence performance caused by the {\em double} non-smooth objective. To accelerate the computation, in this paper, we proposed a decentralized surrogate median regression (deSMR) method for efficiently solving the decentralized sparsity learning problem. We show that our proposed algorithm enjoys a linear convergence rate with a simple implementation. We also investigate the statistical guarantee, and it shows that our proposed estimator achieves a near-oracle convergence rate without any restriction on the number of network nodes. Moreover, we establish the theoretical results for sparse support recovery. Thorough numerical experiments and real data study are provided to demonstrate the effectiveness of our method.
Nonparametric Feature Selection by Random Forests and Deep Neural Networks
Jan 18, 2022
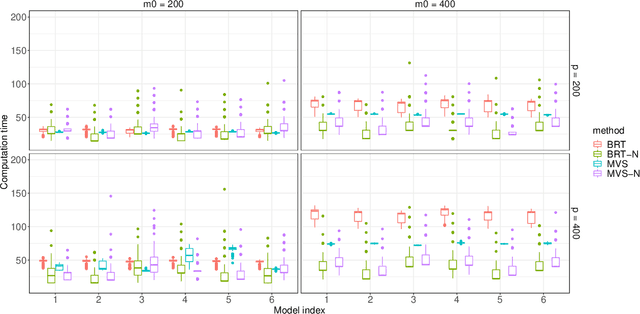
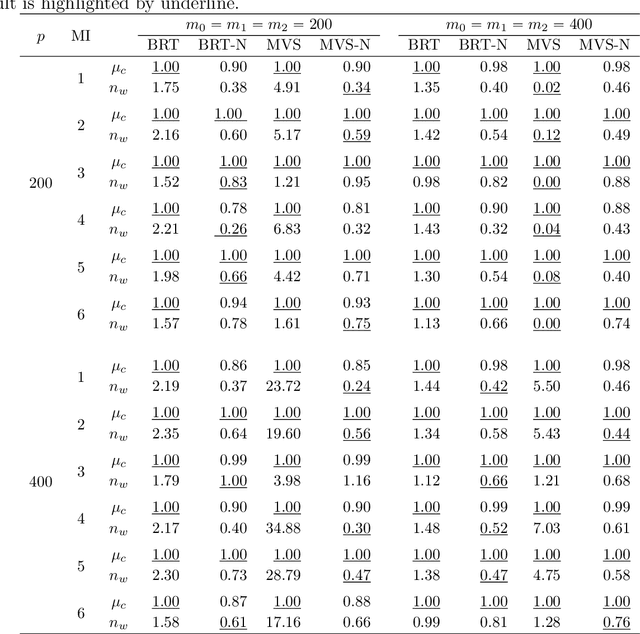

Random forests are a widely used machine learning algorithm, but their computational efficiency is undermined when applied to large-scale datasets with numerous instances and useless features. Herein, we propose a nonparametric feature selection algorithm that incorporates random forests and deep neural networks, and its theoretical properties are also investigated under regularity conditions. Using different synthetic models and a real-world example, we demonstrate the advantage of the proposed algorithm over other alternatives in terms of identifying useful features, avoiding useless ones, and the computation efficiency. Although the algorithm is proposed using standard random forests, it can be widely adapted to other machine learning algorithms, as long as features can be sorted accordingly.
Applying Differential Privacy to Tensor Completion
Oct 13, 2021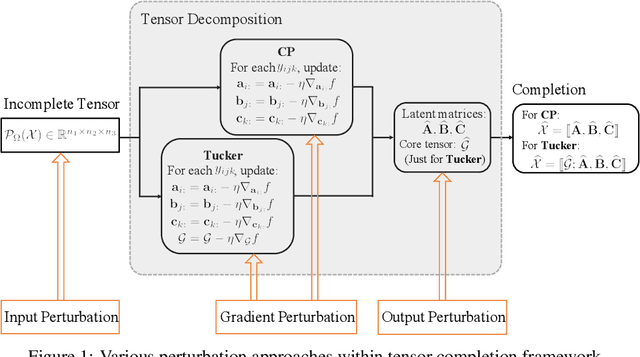
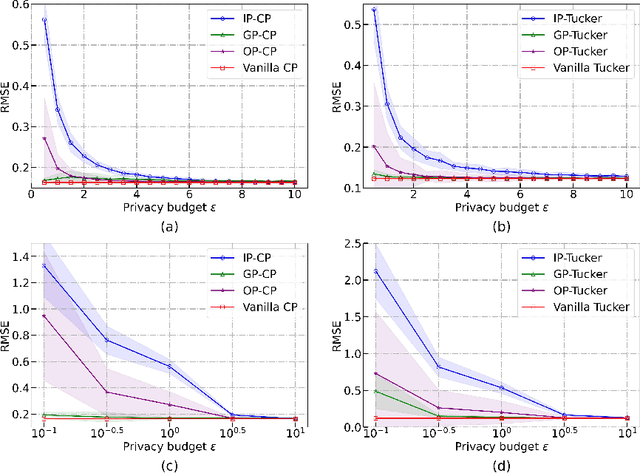
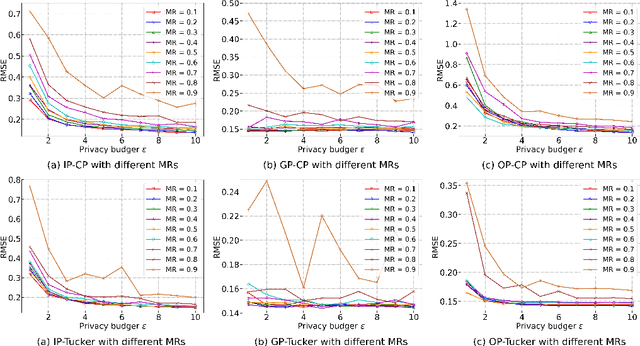
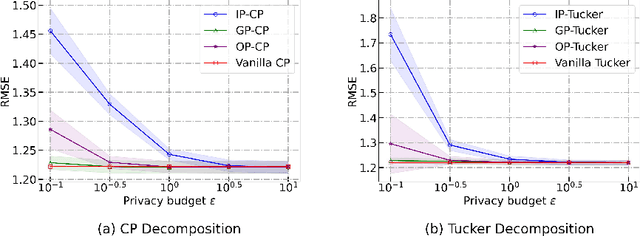
Tensor completion aims at filling the missing or unobserved entries based on partially observed tensors. However, utilization of the observed tensors often raises serious privacy concerns in many practical scenarios. To address this issue, we propose a solid and unified framework that contains several approaches for applying differential privacy to the two most widely used tensor decomposition methods: i) CANDECOMP/PARAFAC~(CP) and ii) Tucker decompositions. For each approach, we establish a rigorous privacy guarantee and meanwhile evaluate the privacy-accuracy trade-off. Experiments on synthetic and real-world datasets demonstrate that our proposal achieves high accuracy for tensor completion while ensuring strong privacy protections.
SAM: A Self-adaptive Attention Module for Context-Aware Recommendation System
Oct 13, 2021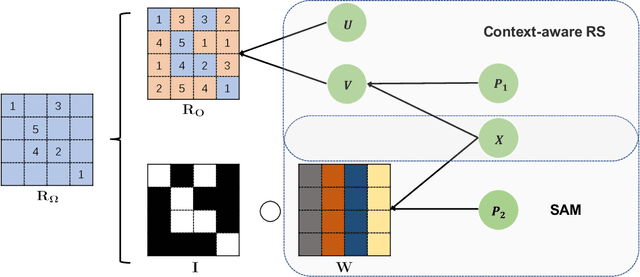
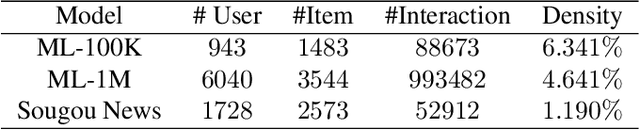
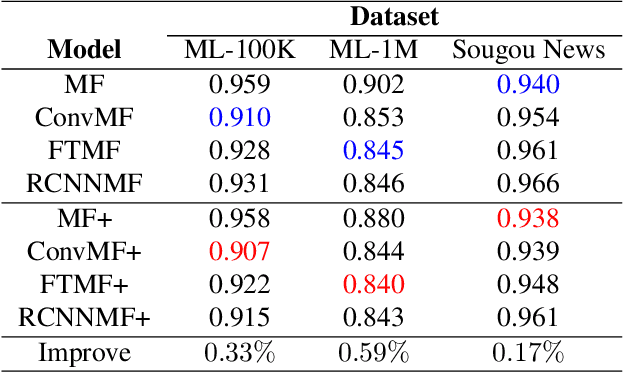
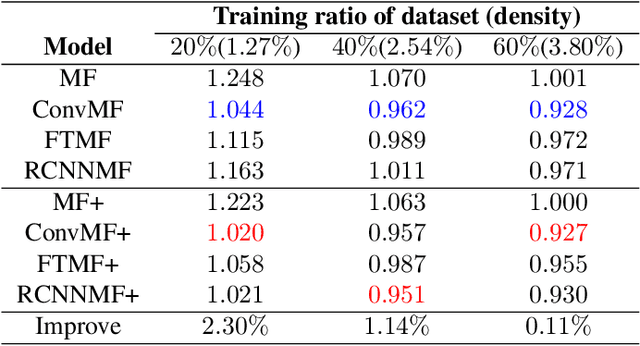
Recently, textual information has been proved to play a positive role in recommendation systems. However, most of the existing methods only focus on representation learning of textual information in ratings, while potential selection bias induced by the textual information is ignored. In this work, we propose a novel and general self-adaptive module, the Self-adaptive Attention Module (SAM), which adjusts the selection bias by capturing contextual information based on its representation. This module can be embedded into recommendation systems that contain learning components of contextual information. Experimental results on three real-world datasets demonstrate the effectiveness of our proposal, and the state-of-the-art models with SAM significantly outperform the original ones.