 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Semi-Supervised Sparse Statistical Inference
Paper and Code
Jun 17, 2023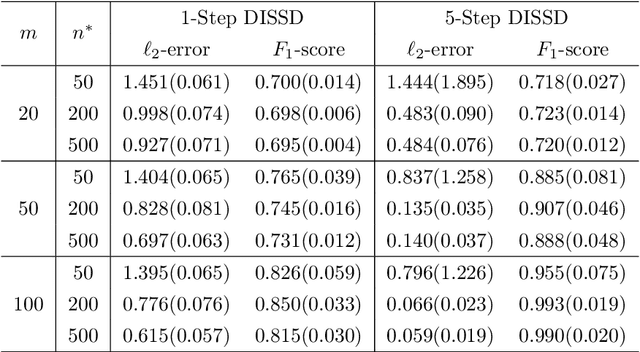
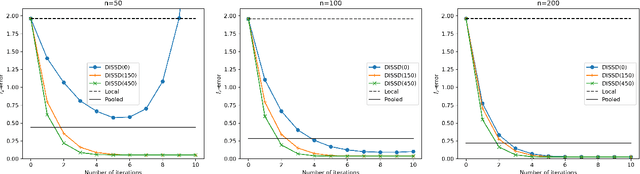
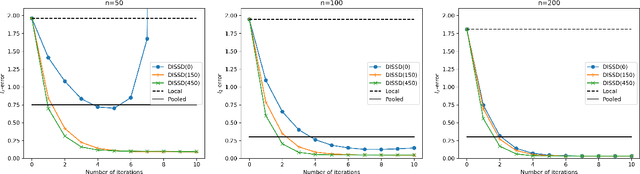
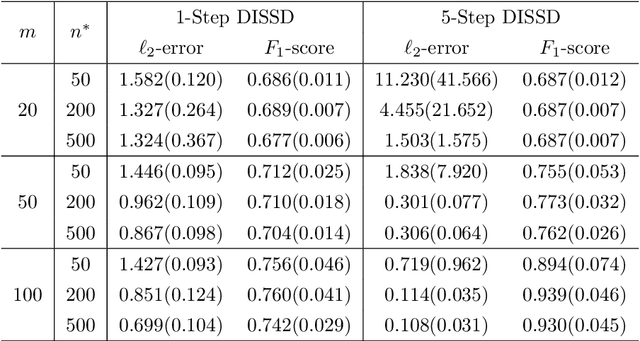
This paper is devoted to studying the semi-supervised sparse statistical inference in a distributed setup. An efficient multi-round distributed debiased estimator, which integrates both labeled and unlabelled data, is developed. We will show that the additional unlabeled data helps to improve the statistical rate of each round of iteration. Our approach offers tailored debiasing methods for $M$-estimation and generalized linear model according to the specific form of the loss function. Our method also applies to a non-smooth loss like absolute deviation loss. Furthermore, our algorithm is computationally efficient since it requires only one estimation of a high-dimensional inverse covariance matrix. We demonstrate the effectiveness of our method by presenting simulation studies and real data applications that highlight the benefits of incorporating unlabeled data.