 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Variational Bayes by Min-Max Median Aggregation
Dec 14, 2025We propose a robust and scalable variational Bayes (VB) framework designed to effectively handle contamination and outliers in dataset. Our approach partitions the data into $m$ disjoint subsets and formulates a joint optimization problem based on robust aggregation principles. A key insight is that the full posterior distribution is equivalent to the minimizer of the mean Kullback-Leibler (KL) divergence from the $m$-powered local posterior distributions. To enhance robustness, we replace the mean KL divergence with a min-max median formulation. The min-max formulation not only ensures consistency between the KL minimizer and the Evidence Lower Bound (ELBO) maximizer but also facilitates the establishment of improved statistical rates for the mean of variational posterior. We observe a notable discrepancy in the $m$-powered marginal log likelihood function contingent on the presence of local latent variables. To address this, we treat these two scenarios separately to guarantee the consistency of the aggregated variational posterior. Specifically, when local latent variables are present, we introduce an aggregate-and-rescale strategy. Theoretically, we provide a non-asymptotic analysis of our proposed posterior, incorporating a refined analysis of Bernstein-von Mises (BvM) theorem to accommodate a diverging number of subsets $m$. Our findings indicate that the two-stage approach yields a smaller approximation error compared to directly aggregating the $m$-powered local posteriors. Furthermore, we establish a nearly optimal statistical rate for the mean of the proposed posterior, advancing existing theories related to min-max median estimators. The efficacy of our method is demonstrated through extensive simulation studies.
Online Estimation and Inference for Robust Policy Evaluation in Reinforcement Learning
Oct 04, 2023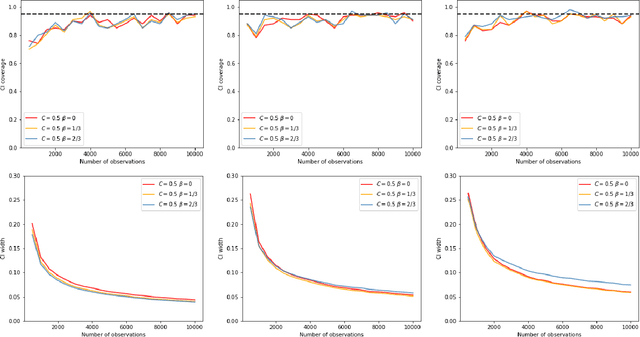
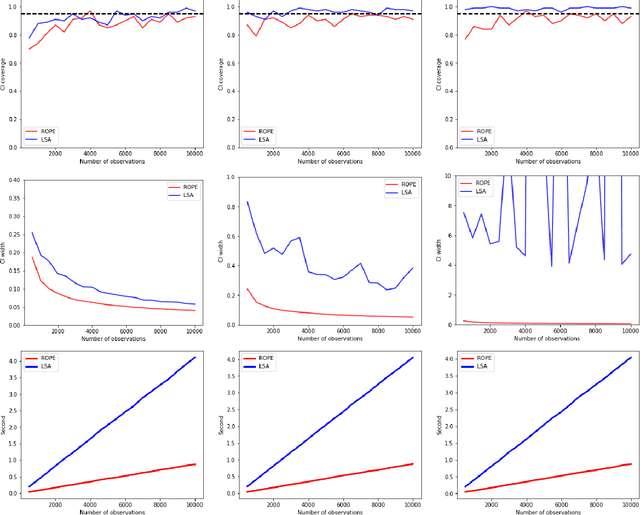
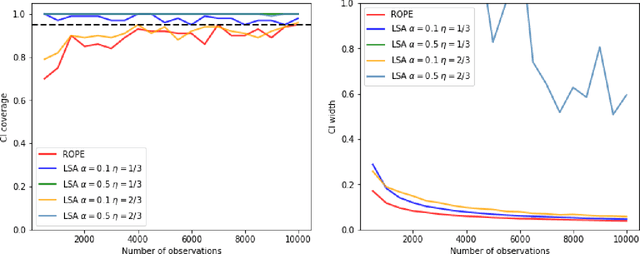
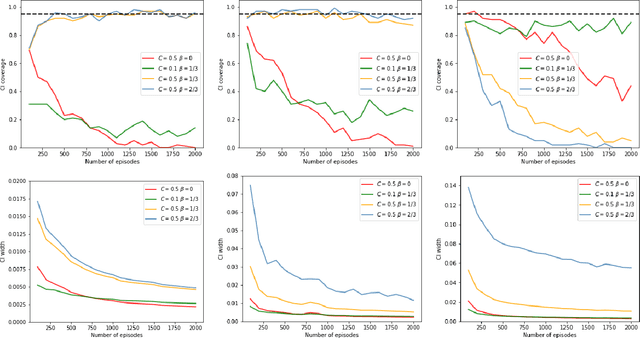
Recently, reinforcement learning has gained prominence in modern statistics, with policy evaluation being a key component. Unlike traditional machine learning literature on this topic, our work places emphasis on statistical inference for the parameter estimates computed using reinforcement learning algorithms. While most existing analyses assume random rewards to follow standard distributions, limiting their applicability, we embrace the concept of robust statistics in reinforcement learning by simultaneously addressing issues of outlier contamination and heavy-tailed rewards within a unified framework. In this paper, we develop an online robust policy evaluation procedure, and establish the limiting distribution of our estimator, based on its Bahadur representation. Furthermore, we develop a fully-online procedure to efficiently conduct statistical inference based on the asymptotic distribution. This paper bridges the gap between robust statistics and statistical inference in reinforcement learning, offering a more versatile and reliable approach to policy evaluation. Finally, we validate the efficacy of our algorithm through numerical experiments conducted in real-world reinforcement learning experiments.
Distributed Semi-Supervised Sparse Statistical Inference
Jun 17, 2023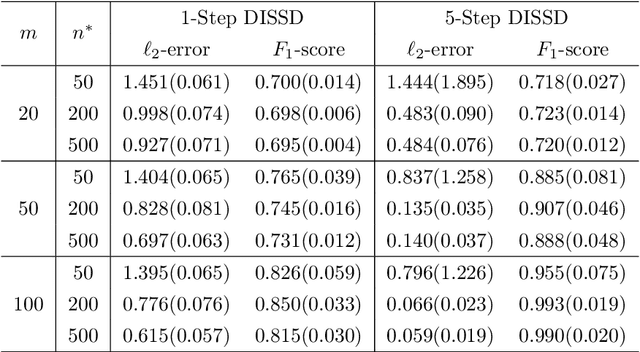
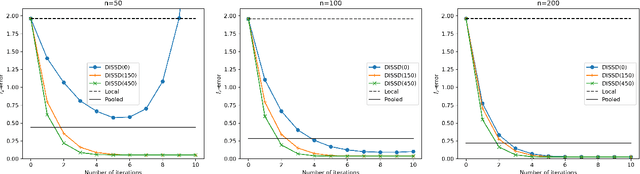
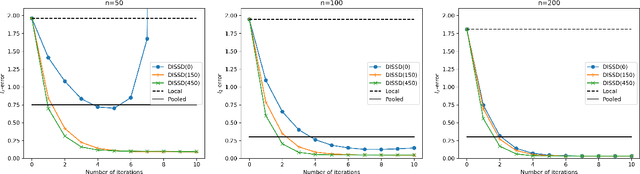
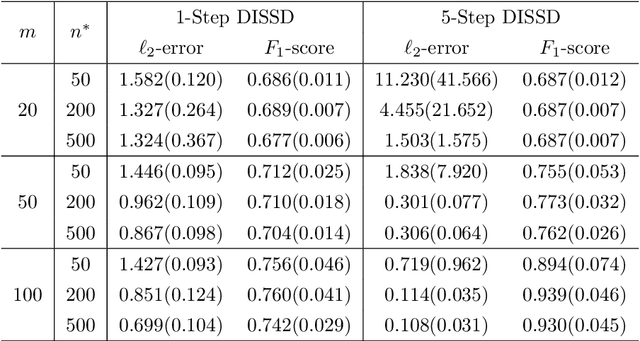
This paper is devoted to studying the semi-supervised sparse statistical inference in a distributed setup. An efficient multi-round distributed debiased estimator, which integrates both labeled and unlabelled data, is developed. We will show that the additional unlabeled data helps to improve the statistical rate of each round of iteration. Our approach offers tailored debiasing methods for $M$-estimation and generalized linear model according to the specific form of the loss function. Our method also applies to a non-smooth loss like absolute deviation loss. Furthermore, our algorithm is computationally efficient since it requires only one estimation of a high-dimensional inverse covariance matrix. We demonstrate the effectiveness of our method by presenting simulation studies and real data applications that highlight the benefits of incorporating unlabeled data.
Majority Vote for Distributed Differentially Private Sign Selection
Sep 08, 2022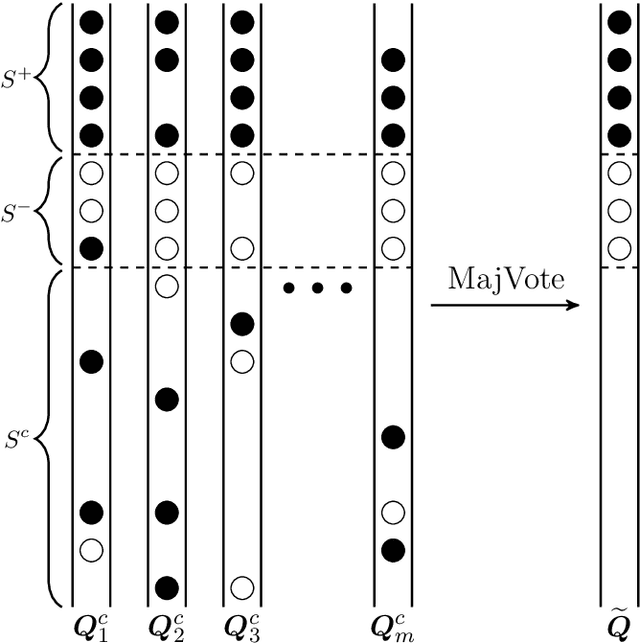
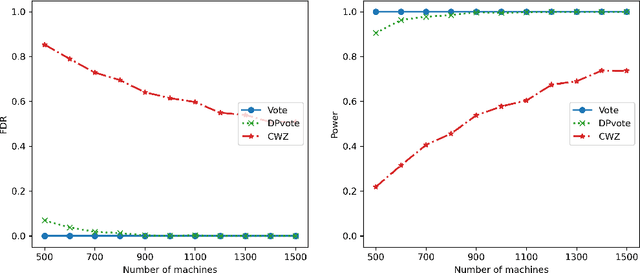
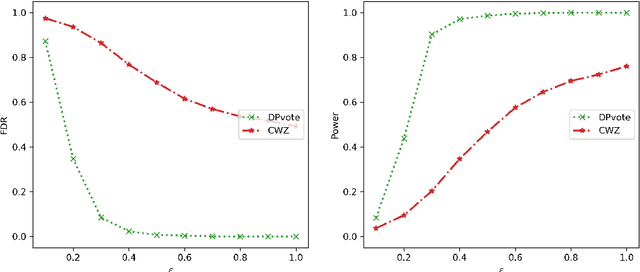
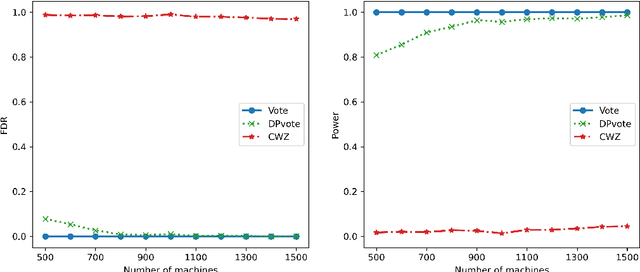
Privacy-preserving data analysis has become prevailing in recent years. In this paper, we propose a distributed group differentially private majority vote mechanism for the sign selection problem in a distributed setup. To achieve this, we apply the iterative peeling to the stability function and use the exponential mechanism to recover the signs. As applications, we study the private sign selection for mean estimation and linear regression problems in distributed systems. Our method recovers the support and signs with the optimal signal-to-noise ratio as in the non-private scenario, which is better than contemporary works of private variable selections. Moreover, the sign selection consistency is justified with theoretical guarantees. Simulation studies are conducted to demonstrate the effectiveness of our proposed method.
Variance Reduced Median-of-Means Estimator for Byzantine-Robust Distributed Inference
Mar 04, 2021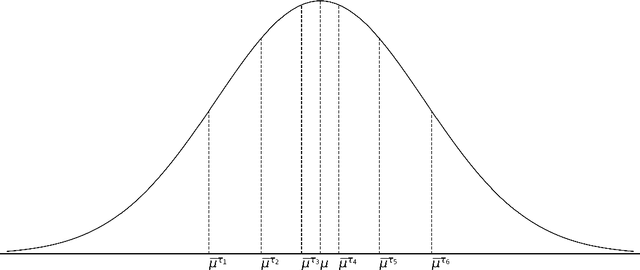
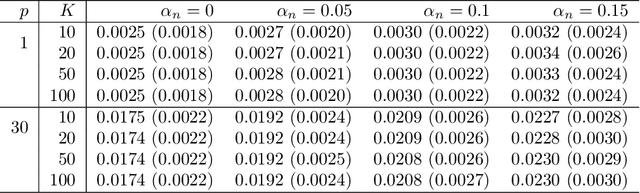
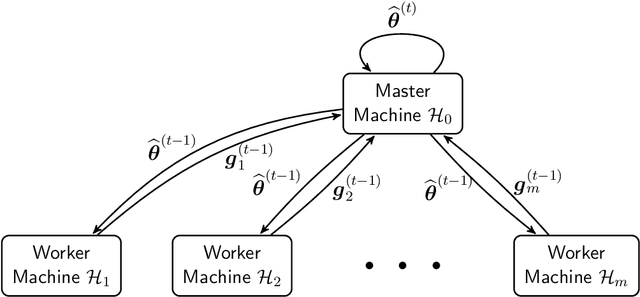
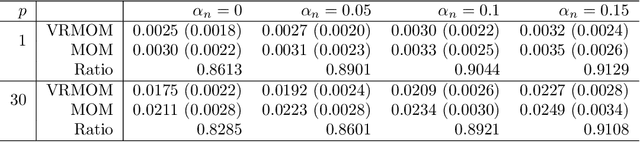
This paper develops an efficient distributed inference algorithm, which is robust against a moderate fraction of Byzantine nodes, namely arbitrary and possibly adversarial machines in a distributed learning system. In robust statistics, the median-of-means (MOM) has been a popular approach to hedge against Byzantine failures due to its ease of implementation and computational efficiency. However, the MOM estimator has the shortcoming in terms of statistical efficiency. The first main contribution of the paper is to propose a variance reduced median-of-means (VRMOM) estimator, which improves the statistical efficiency over the vanilla MOM estimator and is computationally as efficient as the MOM. Based on the proposed VRMOM estimator, we develop a general distributed inference algorithm that is robust against Byzantine failures. Theoretically, our distributed algorithm achieves a fast convergence rate with only a constant number of rounds of communications. We also provide the asymptotic normality result for the purpose of statistical inference. To the best of our knowledge, this is the first normality result in the setting of Byzantine-robust distributed learning. The simulation results are also presented to illustrate the effectiveness of our method.