 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Feature Selection by Random Forests and Deep Neural Networks
Paper and Code
Jan 18, 2022
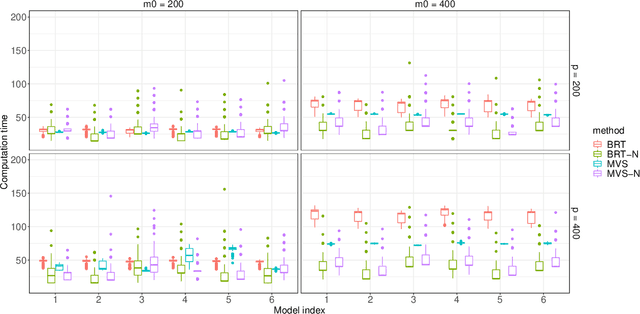
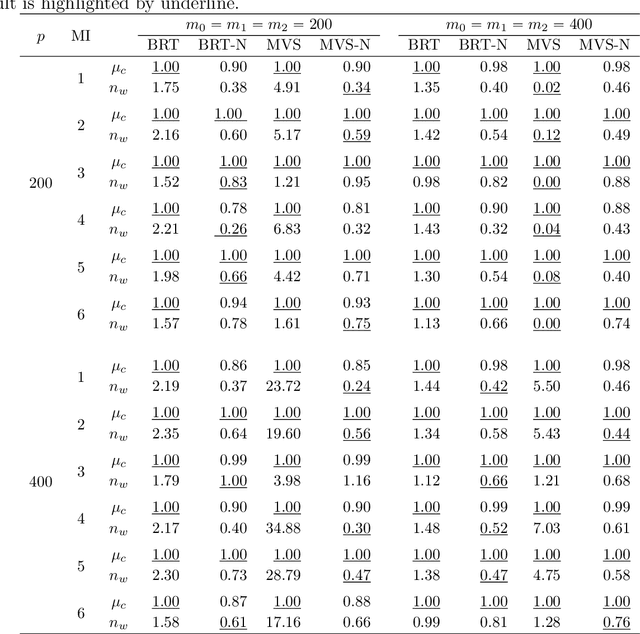

Random forests are a widely used machine learning algorithm, but their computational efficiency is undermined when applied to large-scale datasets with numerous instances and useless features. Herein, we propose a nonparametric feature selection algorithm that incorporates random forests and deep neural networks, and its theoretical properties are also investigated under regularity conditions. Using different synthetic models and a real-world example, we demonstrate the advantage of the proposed algorithm over other alternatives in terms of identifying useful features, avoiding useless ones, and the computation efficiency. Although the algorithm is proposed using standard random forests, it can be widely adapted to other machine learning algorithms, as long as features can be sorted accordingly.