 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapformer: Adaptive Channel Management for Multivariate Time Series Forecasting
Nov 18, 2025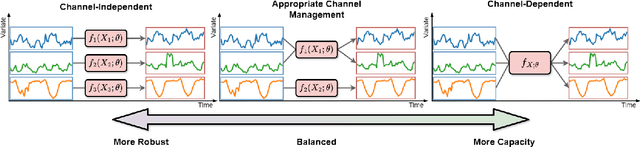
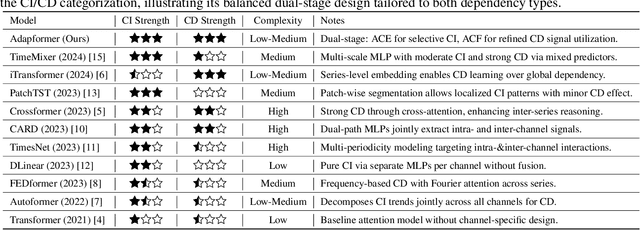
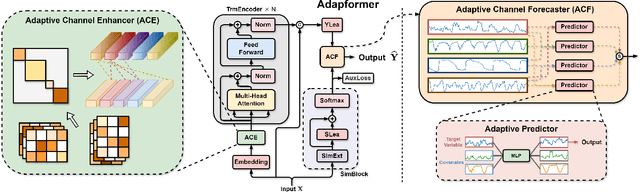
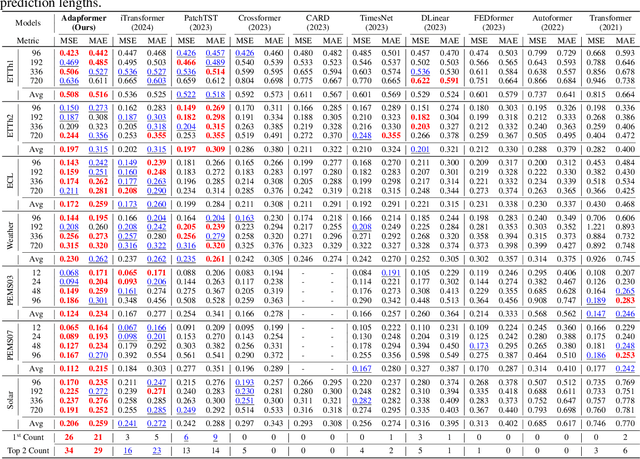
In multivariate time series forecasting (MTSF), accurately modeling the intricate dependencies among multiple variables remains a significant challenge due to the inherent limitations of traditional approaches. Most existing models adopt either \textbf{channel-independent} (CI) or \textbf{channel-dependent} (CD) strategies, each presenting distinct drawbacks. CI methods fail to leverage the potential insights from inter-channel interactions, resulting in models that may not fully exploit the underlying statistical dependencies present in the data. Conversely, CD approaches often incorporate too much extraneous information, risking model overfitting and predictive inefficiency. To address these issues, we introduce the Adaptive Forecasting Transformer (\textbf{Adapformer}), an advanced Transformer-based framework that merges the benefits of CI and CD methodologies through effective channel management. The core of Adapformer lies in its dual-stage encoder-decoder architecture, which includes the \textbf{A}daptive \textbf{C}hannel \textbf{E}nhancer (\textbf{ACE}) for enriching embedding processes and the \textbf{A}daptive \textbf{C}hannel \textbf{F}orecaster (\textbf{ACF}) for refining the predictions. ACE enhances token representations by selectively incorporating essential dependencies, while ACF streamlines the decoding process by focusing on the most relevant covariates, substantially reducing noise and redundancy. Our rigorous testing on diverse datasets shows that Adapformer achieves superior performance over existing models, enhancing both predictive accuracy and computational efficiency, thus making it state-of-the-art in MTSF.
Revisit Non-parametric Two-sample Testing as a Semi-supervised Learning Problem
Nov 30, 2024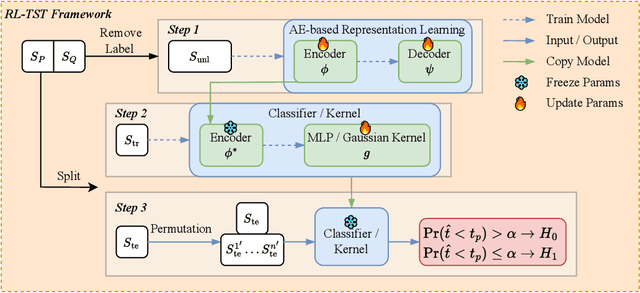

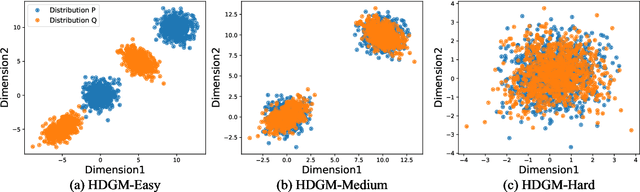
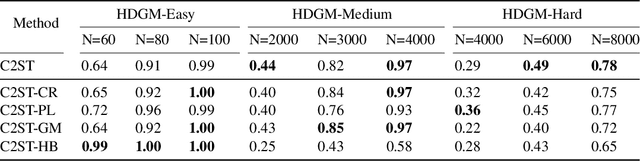
Learning effective data representations is crucial in answering if two samples X and Y are from the same distribution (a.k.a. the non-parametric two-sample testing problem), which can be categorized into: i) learning discriminative representations (DRs) that distinguish between two samples in a supervised-learning paradigm, and ii) learning inherent representations (IRs) focusing on data's inherent features in an unsupervised-learning paradigm. However, both paradigms have issues: learning DRs reduces the data points available for the two-sample testing phase, and learning purely IRs misses discriminative cues. To mitigate both issues, we propose a novel perspective to consider non-parametric two-sample testing as a semi-supervised learning (SSL) problem, introducing the SSL-based Classifier Two-Sample Test (SSL-C2ST) framework. While a straightforward implementation of SSL-C2ST might directly use existing state-of-the-art (SOTA) SSL methods to train a classifier with labeled data (with sample indexes X or Y) and unlabeled data (the remaining ones in the two samples), conventional two-sample testing data often exhibits substantial overlap between samples and violates SSL methods' assumptions, resulting in low test power. Therefore, we propose a two-step approach: first, learn IRs using all data, then fine-tune IRs with only labelled data to learn DRs, which can both utilize information from whole dataset and adapt the discriminative power to the given data. Extensive experiments and theoretical analysis demonstrate that SSL-C2ST outperforms traditional C2ST by effectively leveraging unlabeled data. We also offer a stronger empirically designed test achieving the SOTA performance in many two-sample testing datasets.
Nonparametric Feature Selection by Random Forests and Deep Neural Networks
Jan 18, 2022
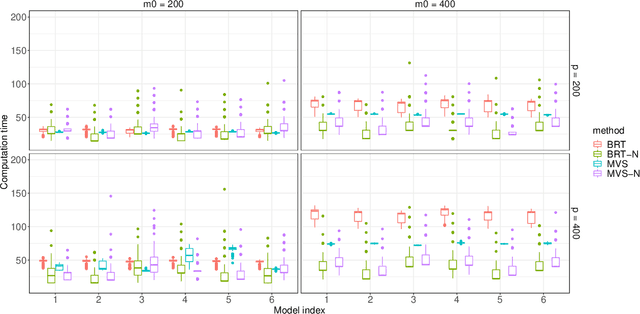
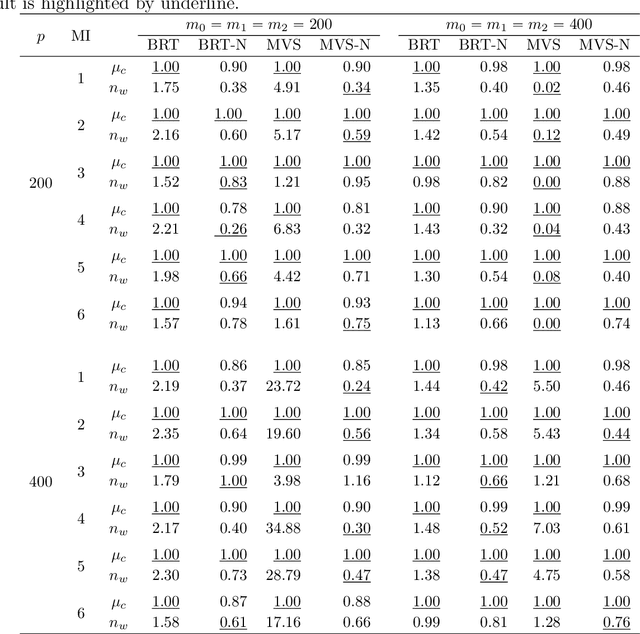

Random forests are a widely used machine learning algorithm, but their computational efficiency is undermined when applied to large-scale datasets with numerous instances and useless features. Herein, we propose a nonparametric feature selection algorithm that incorporates random forests and deep neural networks, and its theoretical properties are also investigated under regularity conditions. Using different synthetic models and a real-world example, we demonstrate the advantage of the proposed algorithm over other alternatives in terms of identifying useful features, avoiding useless ones, and the computation efficiency. Although the algorithm is proposed using standard random forests, it can be widely adapted to other machine learning algorithms, as long as features can be sorted accordingly.