 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Long-Range ENSO Prediction with an Explainable Deep Learning Model
Mar 25, 2025El Ni\~no-Southern Oscillation (ENSO) is a prominent mode of interannual climate variability with far-reaching global impacts. Its evolution is governed by intricate air-sea interactions, posing significant challenges for long-term prediction. In this study, we introduce CTEFNet, a multivariate deep learning model that synergizes convolutional neural networks and transformers to enhance ENSO forecasting. By integrating multiple oceanic and atmospheric predictors, CTEFNet extends the effective forecast lead time to 20 months while mitigating the impact of the spring predictability barrier, outperforming both dynamical models and state-of-the-art deep learning approaches. Furthermore, CTEFNet offers physically meaningful and statistically significant insights through gradient-based sensitivity analysis, revealing the key precursor signals that govern ENSO dynamics, which align with well-established theories and reveal new insights about inter-basin interactions among the Pacific, Atlantic, and Indian Oceans. The CTEFNet's superior predictive skill and interpretable sensitivity assessments underscore its potential for advancing climate prediction. Our findings highlight the importance of multivariate coupling in ENSO evolution and demonstrate the promise of deep learning in capturing complex climate dynamics with enhanced interpretability.
Mixed Matrix Completion in Complex Survey Sampling under Heterogeneous Missingness
Feb 06, 2024Modern surveys with large sample sizes and growing mixed-type questionnaires require robust and scalable analysis methods. In this work, we consider recovering a mixed dataframe matrix, obtained by complex survey sampling, with entries following different canonical exponential distributions and subject to heterogeneous missingness. To tackle this challenging task, we propose a two-stage procedure: in the first stage, we model the entry-wise missing mechanism by logistic regression, and in the second stage, we complete the target parameter matrix by maximizing a weighted log-likelihood with a low-rank constraint. We propose a fast and scalable estimation algorithm that achieves sublinear convergence, and the upper bound for the estimation error of the proposed method is rigorously derived. Experimental results support our theoretical claims, and the proposed estimator shows its merits compared to other existing methods. The proposed method is applied to analyze the National Health and Nutrition Examination Survey data.
Transductive Matrix Completion with Calibration for Multi-Task Learning
Feb 20, 2023



Multi-task learning has attracted much attention due to growing multi-purpose research with multiple related data sources. Moreover, transduction with matrix completion is a useful method in multi-label learning. In this paper, we propose a transductive matrix completion algorithm that incorporates a calibration constraint for the features under the multi-task learning framework. The proposed algorithm recovers the incomplete feature matrix and target matrix simultaneously. Fortunately, the calibration information improves the completion results. In particular, we provide a statistical guarantee for the proposed algorithm, and the theoretical improvement induced by calibration information is also studied. Moreover, the proposed algorithm enjoys a sub-linear convergence rate. Several synthetic data experiments are conducted, which show the proposed algorithm out-performs other existing methods, especially when the target matrix is associated with the feature matrix in a nonlinear way.
Nonparametric Feature Selection by Random Forests and Deep Neural Networks
Jan 18, 2022
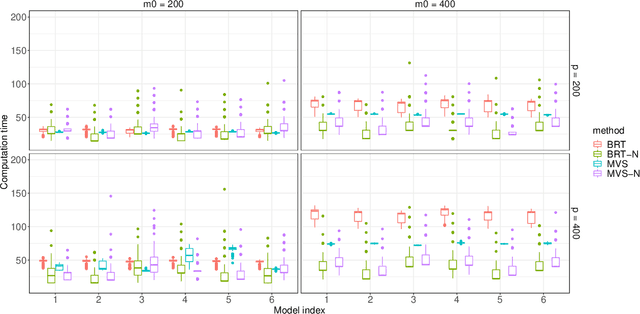
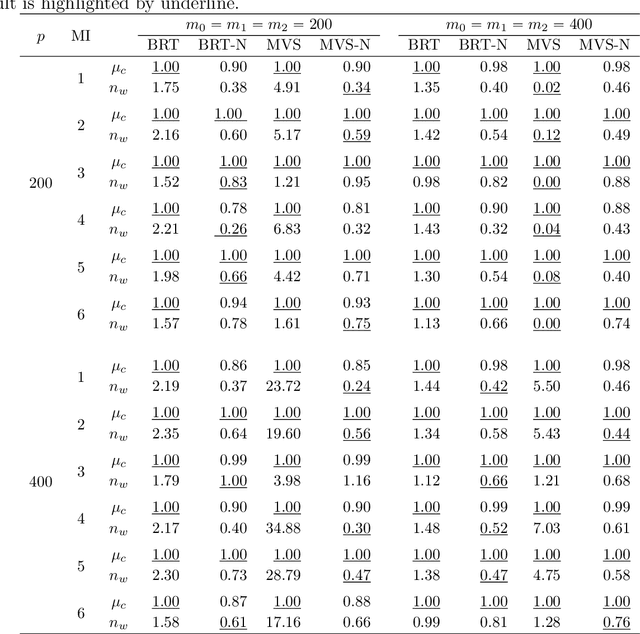

Random forests are a widely used machine learning algorithm, but their computational efficiency is undermined when applied to large-scale datasets with numerous instances and useless features. Herein, we propose a nonparametric feature selection algorithm that incorporates random forests and deep neural networks, and its theoretical properties are also investigated under regularity conditions. Using different synthetic models and a real-world example, we demonstrate the advantage of the proposed algorithm over other alternatives in terms of identifying useful features, avoiding useless ones, and the computation efficiency. Although the algorithm is proposed using standard random forests, it can be widely adapted to other machine learning algorithms, as long as features can be sorted accordingly.