 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAL: Regression-Aware Reinforcement Learning for LLM-as-a-Judge
Mar 17, 2026Large language models (LLMs) are increasingly deployed as automated evaluators that assign numeric scores to model outputs, a paradigm known as LLM-as-a-Judge. However, standard Reinforcement Learning (RL) methods typically rely on binary rewards (e.g., 0-1 accuracy), thereby ignoring the ordinal structure inherent in regression tasks; for instance, they fail to recognize that predicting 4 is significantly better than predicting 1 when the ground truth is 5. Conversely, existing regression-aware approaches are often confined to Supervised Fine-Tuning (SFT), limiting their ability to explore optimal reasoning paths. To bridge this gap, we propose \textbf{REAL} (\underline{RE}gression-\underline{A}ware Reinforcement \underline{L}earning), a principled RL framework designed to optimize regression rewards, and also proven to be optimal for correlation metrics. A key technical challenge is that the regression objective is explicitly policy-dependent, thus invalidating standard policy gradient methods. To address this, we employ the generalized policy gradient estimator, which naturally decomposes optimization into two complementary components: (1) exploration over Chain-of-Thought (CoT) trajectory, and (2) regression-aware prediction refinement of the final score. Extensive experiments across model scales (8B to 32B) demonstrate that REAL consistently outperforms both regression-aware SFT baselines and standard RL methods, exhibiting significantly better generalization on out-of-domain benchmarks. On Qwen3-32B specifically, we achieve gains of +8.40 Pearson and +7.20 Spearman correlation over the SFT baseline, and +18.30/+11.20 over the base model. These findings highlight the critical value of integrating regression objectives into RL exploration for accurate LLM evaluation.
Learning Regularization Functionals for Inverse Problems: A Comparative Study
Oct 02, 2025In recent years, a variety of learned regularization frameworks for solving inverse problems in imaging have emerged. These offer flexible modeling together with mathematical insights. The proposed methods differ in their architectural design and training strategies, making direct comparison challenging due to non-modular implementations. We address this gap by collecting and unifying the available code into a common framework. This unified view allows us to systematically compare the approaches and highlight their strengths and limitations, providing valuable insights into their future potential. We also provide concise descriptions of each method, complemented by practical guidelines.
Restoration Score Distillation: From Corrupted Diffusion Pretraining to One-Step High-Quality Generation
May 19, 2025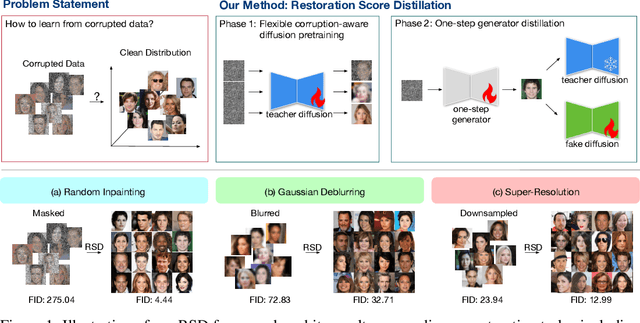


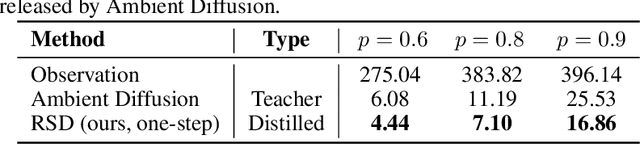
Learning generative models from corrupted data is a fundamental yet persistently challenging task across scientific disciplines, particularly when access to clean data is limited or expensive. Denoising Score Distillation (DSD) \cite{chen2025denoising} recently introduced a novel and surprisingly effective strategy that leverages score distillation to train high-fidelity generative models directly from noisy observations. Building upon this foundation, we propose \textit{Restoration Score Distillation} (RSD), a principled generalization of DSD that accommodates a broader range of corruption types, such as blurred, incomplete, or low-resolution images. RSD operates by first pretraining a teacher diffusion model solely on corrupted data and subsequently distilling it into a single-step generator that produces high-quality reconstructions. Empirically, RSD consistently surpasses its teacher model across diverse restoration tasks on both natural and scientific datasets. Moreover, beyond standard diffusion objectives, the RSD framework is compatible with several corruption-aware training techniques such as Ambient Tweedie, Ambient Diffusion, and its Fourier-space variant, enabling flexible integration with recent advances in diffusion modeling. Theoretically, we demonstrate that in a linear regime, RSD recovers the eigenspace of the clean data covariance matrix from linear measurements, thereby serving as an implicit regularizer. This interpretation recasts score distillation not only as a sampling acceleration technique but as a principled approach to enhancing generative performance in severely degraded data regimes.
Denoising Score Distillation: From Noisy Diffusion Pretraining to One-Step High-Quality Generation
Mar 10, 2025Diffusion models have achieved remarkable success in generating high-resolution, realistic images across diverse natural distributions. However, their performance heavily relies on high-quality training data, making it challenging to learn meaningful distributions from corrupted samples. This limitation restricts their applicability in scientific domains where clean data is scarce or costly to obtain. In this work, we introduce denoising score distillation (DSD), a surprisingly effective and novel approach for training high-quality generative models from low-quality data. DSD first pretrains a diffusion model exclusively on noisy, corrupted samples and then distills it into a one-step generator capable of producing refined, clean outputs. While score distillation is traditionally viewed as a method to accelerate diffusion models, we show that it can also significantly enhance sample quality, particularly when starting from a degraded teacher model. Across varying noise levels and datasets, DSD consistently improves generative performancewe summarize our empirical evidence in Fig. 1. Furthermore, we provide theoretical insights showing that, in a linear model setting, DSD identifies the eigenspace of the clean data distributions covariance matrix, implicitly regularizing the generator. This perspective reframes score distillation as not only a tool for efficiency but also a mechanism for improving generative models, particularly in low-quality data settings.
Unlocking the Potential of Text-to-Image Diffusion with PAC-Bayesian Theory
Nov 25, 2024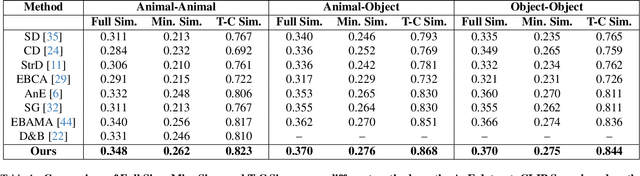
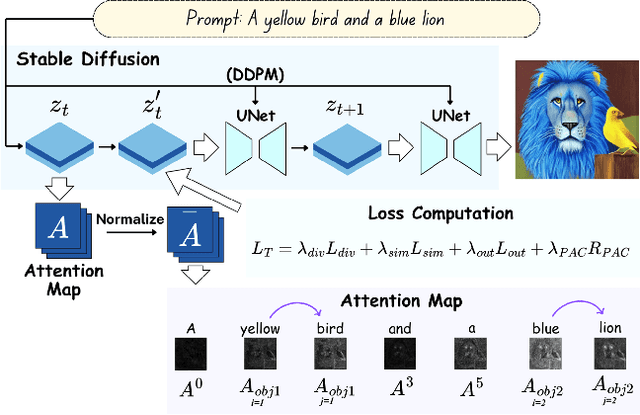

Text-to-image (T2I) diffusion models have revolutionized generative modeling by producing high-fidelity, diverse, and visually realistic images from textual prompts. Despite these advances, existing models struggle with complex prompts involving multiple objects and attributes, often misaligning modifiers with their corresponding nouns or neglecting certain elements. Recent attention-based methods have improved object inclusion and linguistic binding, but still face challenges such as attribute misbinding and a lack of robust generalization guarantees. Leveraging the PAC-Bayes framework, we propose a Bayesian approach that designs custom priors over attention distributions to enforce desirable properties, including divergence between objects, alignment between modifiers and their corresponding nouns, minimal attention to irrelevant tokens, and regularization for better generalization. Our approach treats the attention mechanism as an interpretable component, enabling fine-grained control and improved attribute-object alignment. We demonstrate the effectiveness of our method on standard benchmarks, achieving state-of-the-art results across multiple metrics. By integrating custom priors into the denoising process, our method enhances image quality and addresses long-standing challenges in T2I diffusion models, paving the way for more reliable and interpretable generative models.
Statistical Guarantees for Lifelong Reinforcement Learning using PAC-Bayesian Theory
Nov 01, 2024



Lifelong reinforcement learning (RL) has been developed as a paradigm for extending single-task RL to more realistic, dynamic settings. In lifelong RL, the "life" of an RL agent is modeled as a stream of tasks drawn from a task distribution. We propose EPIC (\underline{E}mpirical \underline{P}AC-Bayes that \underline{I}mproves \underline{C}ontinuously), a novel algorithm designed for lifelong RL using PAC-Bayes theory. EPIC learns a shared policy distribution, referred to as the \textit{world policy}, which enables rapid adaptation to new tasks while retaining valuable knowledge from previous experiences. Our theoretical analysis establishes a relationship between the algorithm's generalization performance and the number of prior tasks preserved in memory. We also derive the sample complexity of EPIC in terms of RL regret. Extensive experiments on a variety of environments demonstrate that EPIC significantly outperforms existing methods in lifelong RL, offering both theoretical guarantees and practical efficacy through the use of the world policy.
DODT: Enhanced Online Decision Transformer Learning through Dreamer's Actor-Critic Trajectory Forecasting
Oct 15, 2024
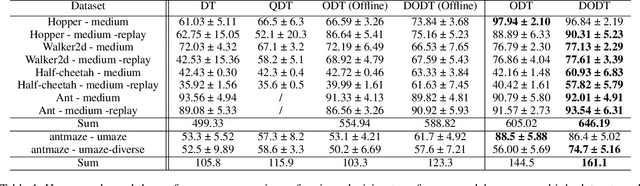
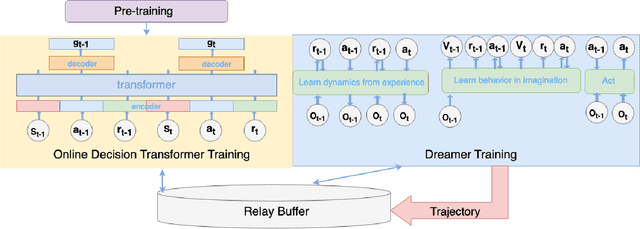
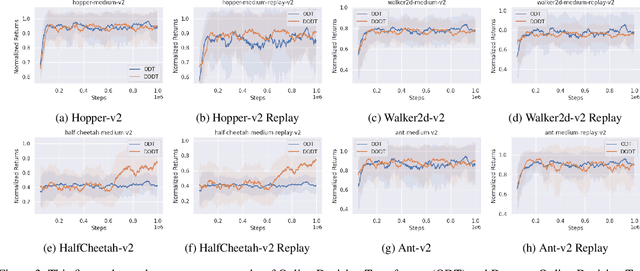
Advancements in reinforcement learning have led to the development of sophisticated models capable of learning complex decision-making tasks. However, efficiently integrating world models with decision transformers remains a challenge. In this paper, we introduce a novel approach that combines the Dreamer algorithm's ability to generate anticipatory trajectories with the adaptive learning strengths of the Online Decision Transformer. Our methodology enables parallel training where Dreamer-produced trajectories enhance the contextual decision-making of the transformer, creating a bidirectional enhancement loop. We empirically demonstrate the efficacy of our approach on a suite of challenging benchmarks, achieving notable improvements in sample efficiency and reward maximization over existing methods. Our results indicate that the proposed integrated framework not only accelerates learning but also showcases robustness in diverse and dynamic scenarios, marking a significant step forward in model-based reinforcement learning.
Think Twice Before You Act: Improving Inverse Problem Solving With MCMC
Sep 13, 2024Recent studies demonstrate that diffusion models can serve as a strong prior for solving inverse problems. A prominent example is Diffusion Posterior Sampling (DPS), which approximates the posterior distribution of data given the measure using Tweedie's formula. Despite the merits of being versatile in solving various inverse problems without re-training, the performance of DPS is hindered by the fact that this posterior approximation can be inaccurate especially for high noise levels. Therefore, we propose \textbf{D}iffusion \textbf{P}osterior \textbf{MC}MC (\textbf{DPMC}), a novel inference algorithm based on Annealed MCMC to solve inverse problems with pretrained diffusion models. We define a series of intermediate distributions inspired by the approximated conditional distributions used by DPS. Through annealed MCMC sampling, we encourage the samples to follow each intermediate distribution more closely before moving to the next distribution at a lower noise level, and therefore reduce the accumulated error along the path. We test our algorithm in various inverse problems, including super resolution, Gaussian deblurring, motion deblurring, inpainting, and phase retrieval. Our algorithm outperforms DPS with less number of evaluations across nearly all tasks, and is competitive among existing approaches.
Flow Priors for Linear Inverse Problems via Iterative Corrupted Trajectory Matching
May 29, 2024



Generative models based on flow matching have attracted significant attention for their simplicity and superior performance in high-resolution image synthesis. By leveraging the instantaneous change-of-variables formula, one can directly compute image likelihoods from a learned flow, making them enticing candidates as priors for downstream tasks such as inverse problems. In particular, a natural approach would be to incorporate such image probabilities in a maximum-a-posteriori (MAP) estimation problem. A major obstacle, however, lies in the slow computation of the log-likelihood, as it requires backpropagating through an ODE solver, which can be prohibitively slow for high-dimensional problems. In this work, we propose an iterative algorithm to approximate the MAP estimator efficiently to solve a variety of linear inverse problems. Our algorithm is mathematically justified by the observation that the MAP objective can be approximated by a sum of $N$ ``local MAP'' objectives, where $N$ is the number of function evaluations. By leveraging Tweedie's formula, we show that we can perform gradient steps to sequentially optimize these objectives. We validate our approach for various linear inverse problems, such as super-resolution, deblurring, inpainting, and compressed sensing, and demonstrate that we can outperform other methods based on flow matching.
Latent Energy-Based Odyssey: Black-Box Optimization via Expanded Exploration in the Energy-Based Latent Space
May 27, 2024Offline Black-Box Optimization (BBO) aims at optimizing a black-box function using the knowledge from a pre-collected offline dataset of function values and corresponding input designs. However, the high-dimensional and highly-multimodal input design space of black-box function pose inherent challenges for most existing methods that model and operate directly upon input designs. These issues include but are not limited to high sample complexity, which relates to inaccurate approximation of black-box function; and insufficient coverage and exploration of input design modes, which leads to suboptimal proposal of new input designs. In this work, we consider finding a latent space that serves as a compressed yet accurate representation of the design-value joint space, enabling effective latent exploration of high-value input design modes. To this end, we formulate an learnable energy-based latent space, and propose Noise-intensified Telescoping density-Ratio Estimation (NTRE) scheme for variational learning of an accurate latent space model without costly Markov Chain Monte Carlo. The optimization process is then exploration of high-value designs guided by the learned energy-based model in the latent space, formulated as gradient-based sampling from a latent-variable-parameterized inverse model. We show that our particular parameterization encourages expanded exploration around high-value design modes, motivated by inversion thinking of a fundamental result of conditional covariance matrix typically used for variance reduction. We observe that our method, backed by an accurately learned informative latent space and an expanding-exploration model design, yields significant improvements over strong previous methods on both synthetic and real world datasets such as the design-bench suite.