 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Potential of Text-to-Image Diffusion with PAC-Bayesian Theory
Paper and Code
Nov 25, 2024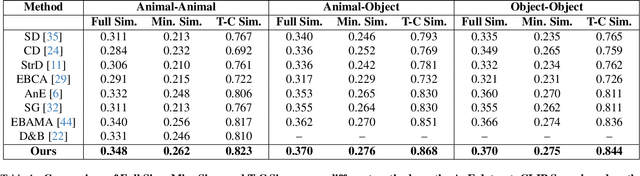
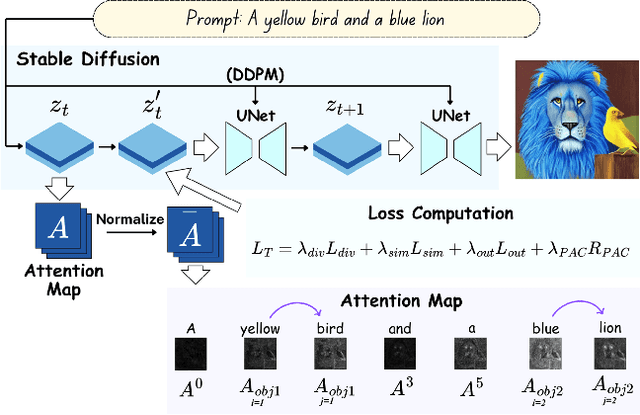
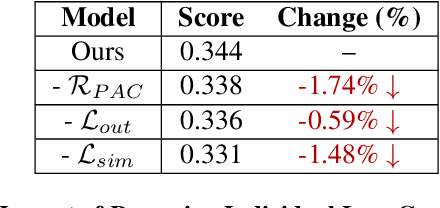

Text-to-image (T2I) diffusion models have revolutionized generative modeling by producing high-fidelity, diverse, and visually realistic images from textual prompts. Despite these advances, existing models struggle with complex prompts involving multiple objects and attributes, often misaligning modifiers with their corresponding nouns or neglecting certain elements. Recent attention-based methods have improved object inclusion and linguistic binding, but still face challenges such as attribute misbinding and a lack of robust generalization guarantees. Leveraging the PAC-Bayes framework, we propose a Bayesian approach that designs custom priors over attention distributions to enforce desirable properties, including divergence between objects, alignment between modifiers and their corresponding nouns, minimal attention to irrelevant tokens, and regularization for better generalization. Our approach treats the attention mechanism as an interpretable component, enabling fine-grained control and improved attribute-object alignment. We demonstrate the effectiveness of our method on standard benchmarks, achieving state-of-the-art results across multiple metrics. By integrating custom priors into the denoising process, our method enhances image quality and addresses long-standing challenges in T2I diffusion models, paving the way for more reliable and interpretable generative models.