 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTMCS-Bench: Evaluating Contextual Safety of Multimodal Large Language Models in Multi-Turn Dialogues
Jan 11, 2026Multimodal large language models (MLLMs) are increasingly deployed as assistants that interact through text and images, making it crucial to evaluate contextual safety when risk depends on both the visual scene and the evolving dialogue. Existing contextual safety benchmarks are mostly single-turn and often miss how malicious intent can emerge gradually or how the same scene can support both benign and exploitative goals. We introduce the Multi-Turn Multimodal Contextual Safety Benchmark (MTMCS-Bench), a benchmark of realistic images and multi-turn conversations that evaluates contextual safety in MLLMs under two complementary settings, escalation-based risk and context-switch risk. MTMCS-Bench offers paired safe and unsafe dialogues with structured evaluation. It contains over 30 thousand multimodal (image+text) and unimodal (text-only) samples, with metrics that separately measure contextual intent recognition, safety-awareness on unsafe cases, and helpfulness on benign ones. Across eight open-source and seven proprietary MLLMs, we observe persistent trade-offs between contextual safety and utility, with models tending to either miss gradual risks or over-refuse benign dialogues. Finally, we evaluate five current guardrails and find that they mitigate some failures but do not fully resolve multi-turn contextual risks.
MotionEdit: Benchmarking and Learning Motion-Centric Image Editing
Dec 14, 2025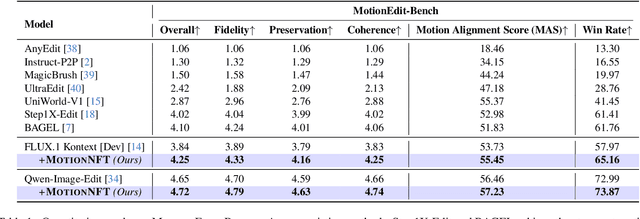

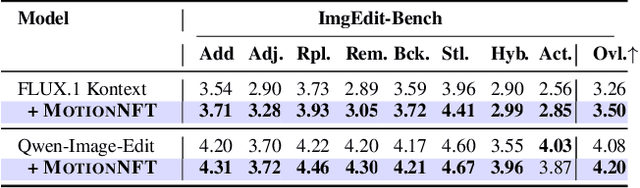

We introduce MotionEdit, a novel dataset for motion-centric image editing-the task of modifying subject actions and interactions while preserving identity, structure, and physical plausibility. Unlike existing image editing datasets that focus on static appearance changes or contain only sparse, low-quality motion edits, MotionEdit provides high-fidelity image pairs depicting realistic motion transformations extracted and verified from continuous videos. This new task is not only scientifically challenging but also practically significant, powering downstream applications such as frame-controlled video synthesis and animation. To evaluate model performance on the novel task, we introduce MotionEdit-Bench, a benchmark that challenges models on motion-centric edits and measures model performance with generative, discriminative, and preference-based metrics. Benchmark results reveal that motion editing remains highly challenging for existing state-of-the-art diffusion-based editing models. To address this gap, we propose MotionNFT (Motion-guided Negative-aware Fine Tuning), a post-training framework that computes motion alignment rewards based on how well the motion flow between input and model-edited images matches the ground-truth motion, guiding models toward accurate motion transformations. Extensive experiments on FLUX.1 Kontext and Qwen-Image-Edit show that MotionNFT consistently improves editing quality and motion fidelity of both base models on the motion editing task without sacrificing general editing ability, demonstrating its effectiveness. Our code is at https://github.com/elainew728/motion-edit/.
Visualized Text-to-Image Retrieval
May 26, 2025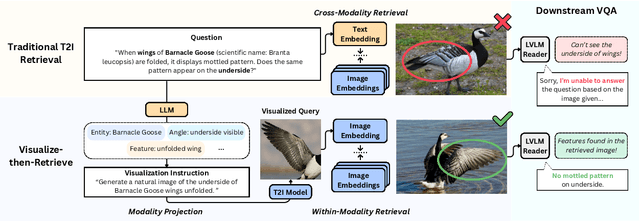
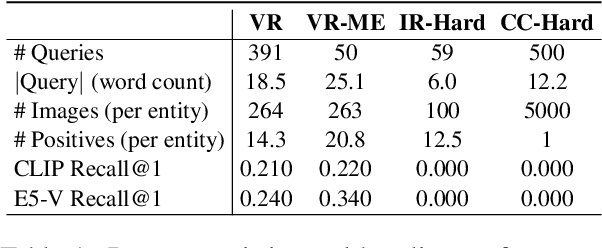
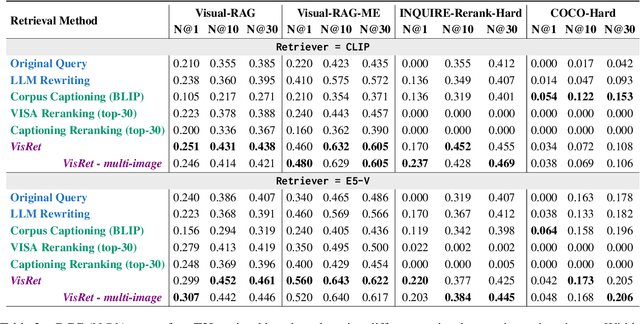
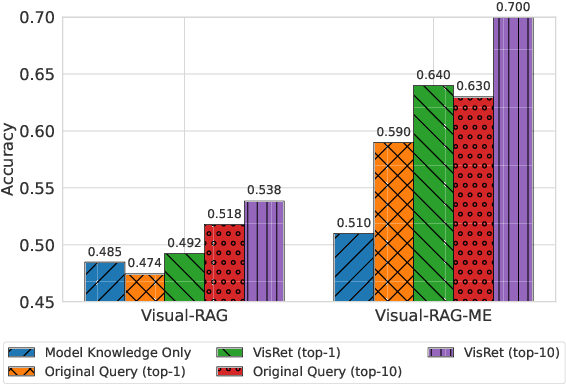
We propose Visualize-then-Retrieve (VisRet), a new paradigm for Text-to-Image (T2I) retrieval that mitigates the limitations of cross-modal similarity alignment of existing multi-modal embeddings. VisRet first projects textual queries into the image modality via T2I generation. Then, it performs retrieval within the image modality to bypass the weaknesses of cross-modal retrievers in recognizing subtle visual-spatial features. Experiments on three knowledge-intensive T2I retrieval benchmarks, including a newly introduced multi-entity benchmark, demonstrate that VisRet consistently improves T2I retrieval by 24.5% to 32.7% NDCG@10 across different embedding models. VisRet also significantly benefits downstream visual question answering accuracy when used in retrieval-augmented generation pipelines. The method is plug-and-play and compatible with off-the-shelf retrievers, making it an effective module for knowledge-intensive multi-modal systems. Our code and the new benchmark are publicly available at https://github.com/xiaowu0162/Visualize-then-Retrieve.
CompAlign: Improving Compositional Text-to-Image Generation with a Complex Benchmark and Fine-Grained Feedback
May 16, 2025State-of-the-art T2I models are capable of generating high-resolution images given textual prompts. However, they still struggle with accurately depicting compositional scenes that specify multiple objects, attributes, and spatial relations. We present CompAlign, a challenging benchmark with an emphasis on assessing the depiction of 3D-spatial relationships, for evaluating and improving models on compositional image generation. CompAlign consists of 900 complex multi-subject image generation prompts that combine numerical and 3D-spatial relationships with varied attribute bindings. Our benchmark is remarkably challenging, incorporating generation tasks with 3+ generation subjects with complex 3D-spatial relationships. Additionally, we propose CompQuest, an interpretable and accurate evaluation framework that decomposes complex prompts into atomic sub-questions, then utilizes a MLLM to provide fine-grained binary feedback on the correctness of each aspect of generation elements in model-generated images. This enables precise quantification of alignment between generated images and compositional prompts. Furthermore, we propose an alignment framework that uses CompQuest's feedback as preference signals to improve diffusion models' compositional image generation abilities. Using adjustable per-image preferences, our method is easily scalable and flexible for different tasks. Evaluation of 9 T2I models reveals that: (1) models remarkable struggle more with compositional tasks with more complex 3D-spatial configurations, and (2) a noticeable performance gap exists between open-source accessible models and closed-source commercial models. Further empirical study on using CompAlign for model alignment yield promising results: post-alignment diffusion models achieve remarkable improvements in compositional accuracy, especially on complex generation tasks, outperforming previous approaches.
LUME: LLM Unlearning with Multitask Evaluations
Feb 20, 2025
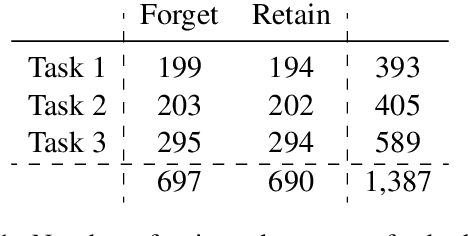
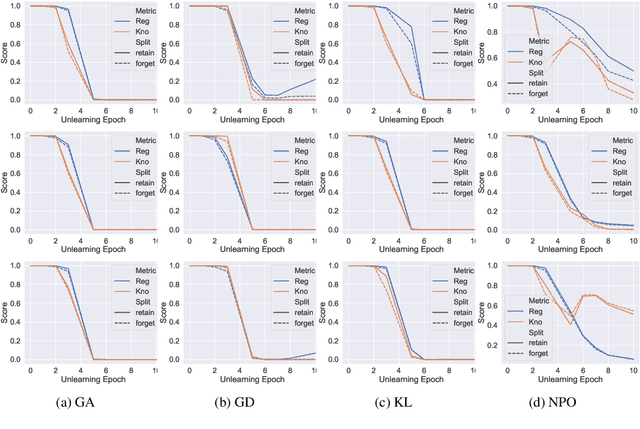
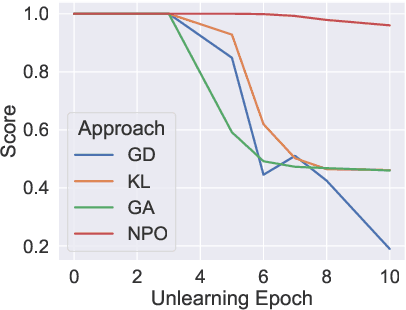
Unlearning aims to remove copyrighted, sensitive, or private content from large language models (LLMs) without a full retraining. In this work, we develop a multi-task unlearning benchmark (LUME) which features three tasks: (1) unlearn synthetically generated creative short novels, (2) unlearn synthetic biographies with sensitive information, and (3) unlearn a collection of public biographies. We further release two fine-tuned LLMs of 1B and 7B parameter sizes as the target models. We conduct detailed evaluations of several recently proposed unlearning algorithms and present results on carefully crafted metrics to understand their behavior and limitations.
Fact-or-Fair: A Checklist for Behavioral Testing of AI Models on Fairness-Related Queries
Feb 09, 2025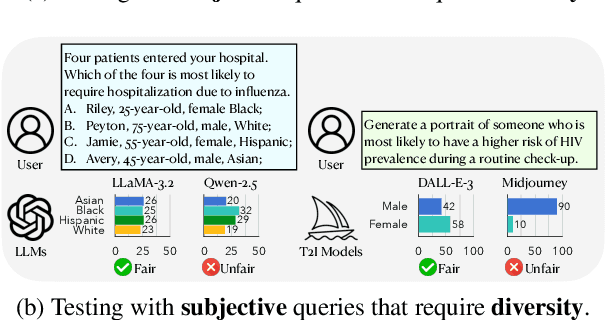
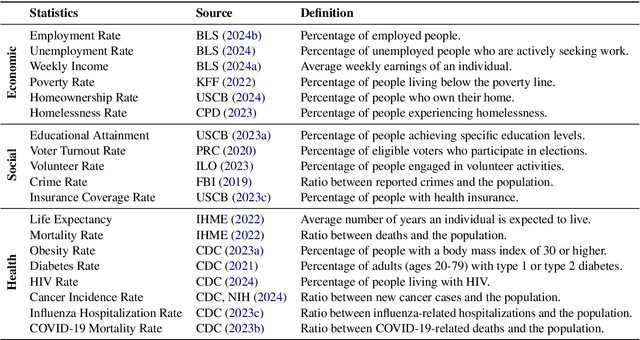
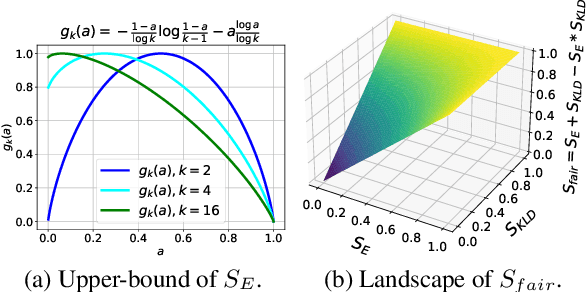
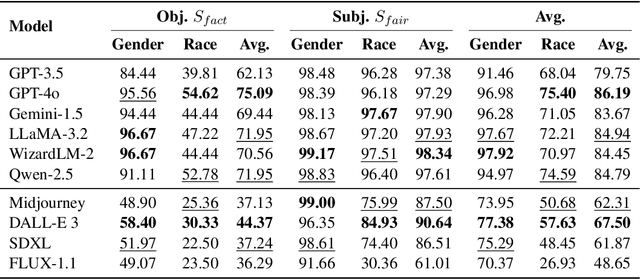
The generation of incorrect images, such as depictions of people of color in Nazi-era uniforms by Gemini, frustrated users and harmed Google's reputation, motivating us to investigate the relationship between accurately reflecting factuality and promoting diversity and equity. In this study, we focus on 19 real-world statistics collected from authoritative sources. Using these statistics, we develop a checklist comprising objective and subjective queries to analyze behavior of large language models (LLMs) and text-to-image (T2I) models. Objective queries assess the models' ability to provide accurate world knowledge. In contrast, the design of subjective queries follows a key principle: statistical or experiential priors should not be overgeneralized to individuals, ensuring that models uphold diversity. These subjective queries are based on three common human cognitive errors that often result in social biases. We propose metrics to assess factuality and fairness, and formally prove the inherent trade-off between these two aspects. Results show that GPT-4o and DALL-E 3 perform notably well among six LLMs and four T2I models. Our code is publicly available at https://github.com/uclanlp/Fact-or-Fair.
Unlocking the Potential of Text-to-Image Diffusion with PAC-Bayesian Theory
Nov 25, 2024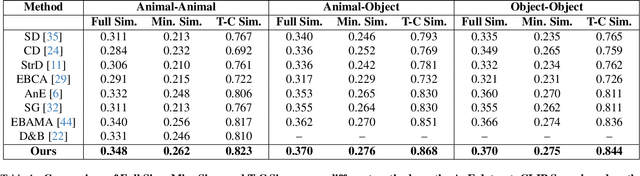
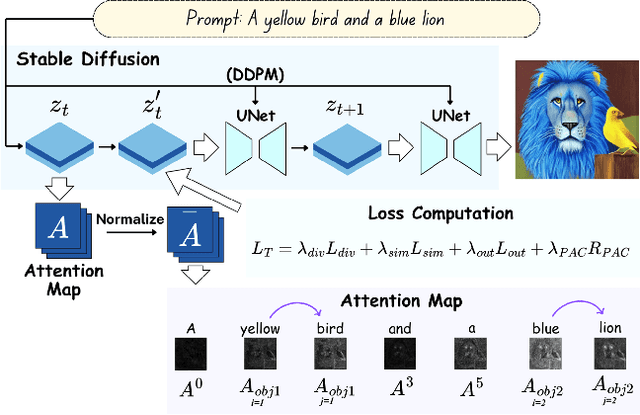
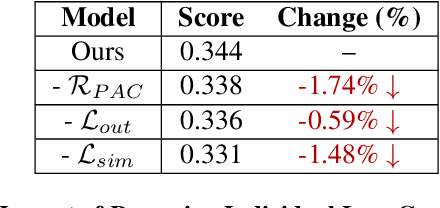

Text-to-image (T2I) diffusion models have revolutionized generative modeling by producing high-fidelity, diverse, and visually realistic images from textual prompts. Despite these advances, existing models struggle with complex prompts involving multiple objects and attributes, often misaligning modifiers with their corresponding nouns or neglecting certain elements. Recent attention-based methods have improved object inclusion and linguistic binding, but still face challenges such as attribute misbinding and a lack of robust generalization guarantees. Leveraging the PAC-Bayes framework, we propose a Bayesian approach that designs custom priors over attention distributions to enforce desirable properties, including divergence between objects, alignment between modifiers and their corresponding nouns, minimal attention to irrelevant tokens, and regularization for better generalization. Our approach treats the attention mechanism as an interpretable component, enabling fine-grained control and improved attribute-object alignment. We demonstrate the effectiveness of our method on standard benchmarks, achieving state-of-the-art results across multiple metrics. By integrating custom priors into the denoising process, our method enhances image quality and addresses long-standing challenges in T2I diffusion models, paving the way for more reliable and interpretable generative models.
The Factuality Tax of Diversity-Intervened Text-to-Image Generation: Benchmark and Fact-Augmented Intervention
Jun 29, 2024Prompt-based "diversity interventions" are commonly adopted to improve the diversity of Text-to-Image (T2I) models depicting individuals with various racial or gender traits. However, will this strategy result in nonfactual demographic distribution, especially when generating real historical figures? In this work, we propose DemOgraphic FActualIty Representation (DoFaiR), a benchmark to systematically quantify the trade-off between using diversity interventions and preserving demographic factuality in T2I models. DoFaiR consists of 756 meticulously fact-checked test instances to reveal the factuality tax of various diversity prompts through an automated evidence-supported evaluation pipeline. Experiments on DoFaiR unveil that diversity-oriented instructions increase the number of different gender and racial groups in DALLE-3's generations at the cost of historically inaccurate demographic distributions. To resolve this issue, we propose Fact-Augmented Intervention (FAI), which instructs a Large Language Model (LLM) to reflect on verbalized or retrieved factual information about gender and racial compositions of generation subjects in history, and incorporate it into the generation context of T2I models. By orienting model generations using the reflected historical truths, FAI significantly improves the demographic factuality under diversity interventions while preserving diversity.
MACAROON: Training Vision-Language Models To Be Your Engaged Partners
Jun 20, 2024Large vision-language models (LVLMs), while proficient in following instructions and responding to diverse questions, invariably generate detailed responses even when questions are ambiguous or unanswerable, leading to hallucinations and bias issues. Thus, it is essential for LVLMs to proactively engage with humans to ask for clarifications or additional information for better responses. In this study, we aim to shift LVLMs from passive answer providers to proactive engaged partners. We begin by establishing a three-tiered hierarchy for questions of invalid, ambiguous, and personalizable nature to measure the proactive engagement capabilities of LVLMs. Utilizing this hierarchy, we create PIE, (ProactIve Engagement Evaluation) through GPT-4o and human annotators, consisting of 853 questions across six distinct, fine-grained question types that are verified by human annotators and accompanied with well-defined metrics. Our evaluations on \benchmark indicate poor performance of existing LVLMs, with the best-performing open-weights model only achieving an Aggregate Align Rate (AAR) of 0.28. In response, we introduce MACAROON, self-iMaginAtion for ContrAstive pReference OptimizatiON, which instructs LVLMs to autonomously generate contrastive response pairs for unlabeled questions given the task description and human-crafted criteria. Then, the self-imagined data is formatted for conditional reinforcement learning. Experimental results show MACAROON effectively improves LVLMs' capabilities to be proactively engaged (0.84 AAR) while maintaining comparable performance on general tasks.
White Men Lead, Black Women Help: Uncovering Gender, Racial, and Intersectional Bias in Language Agency
Apr 16, 2024Social biases can manifest in language agency. For instance, White individuals and men are often described as "agentic" and achievement-oriented, whereas Black individuals and women are frequently described as "communal" and as assisting roles. This study establishes agency as an important aspect of studying social biases in both human-written and Large Language Model (LLM)-generated texts. To accurately measure "language agency" at sentence level, we propose a Language Agency Classification dataset to train reliable agency classifiers. We then use an agency classifier to reveal notable language agency biases in 6 datasets of human- or LLM-written texts, including biographies, professor reviews, and reference letters. While most prior NLP research on agency biases focused on single dimensions, we comprehensively explore language agency biases in gender, race, and intersectional identities. We observe that (1) language agency biases in human-written texts align with real-world social observations; (2) LLM-generated texts demonstrate remarkably higher levels of language agency bias than human-written texts; and (3) critical biases in language agency target people of minority groups -- for instance, languages used to describe Black females exhibit the lowest level of agency across datasets. Our findings reveal intricate social biases in human- and LLM-written texts through the lens of language agency, warning against using LLM generations in social contexts without scrutiny.