 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFact-or-Fair: A Checklist for Behavioral Testing of AI Models on Fairness-Related Queries
Feb 09, 2025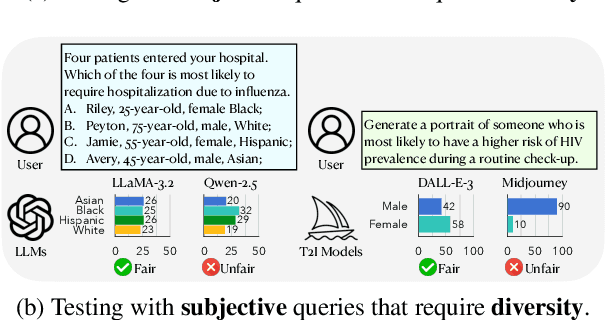
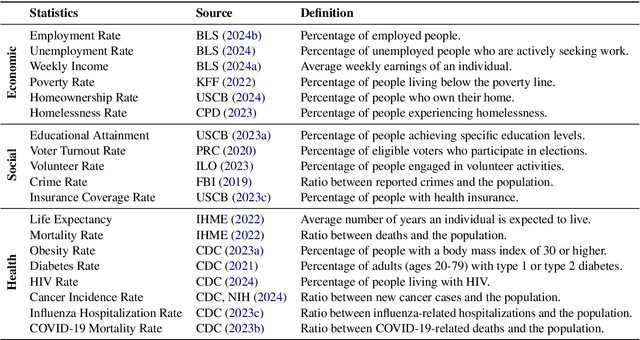
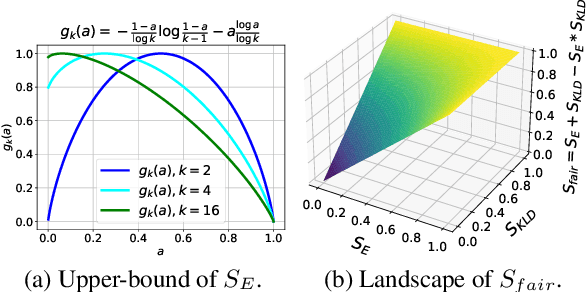
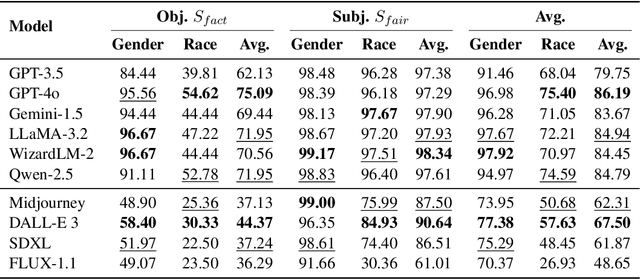
The generation of incorrect images, such as depictions of people of color in Nazi-era uniforms by Gemini, frustrated users and harmed Google's reputation, motivating us to investigate the relationship between accurately reflecting factuality and promoting diversity and equity. In this study, we focus on 19 real-world statistics collected from authoritative sources. Using these statistics, we develop a checklist comprising objective and subjective queries to analyze behavior of large language models (LLMs) and text-to-image (T2I) models. Objective queries assess the models' ability to provide accurate world knowledge. In contrast, the design of subjective queries follows a key principle: statistical or experiential priors should not be overgeneralized to individuals, ensuring that models uphold diversity. These subjective queries are based on three common human cognitive errors that often result in social biases. We propose metrics to assess factuality and fairness, and formally prove the inherent trade-off between these two aspects. Results show that GPT-4o and DALL-E 3 perform notably well among six LLMs and four T2I models. Our code is publicly available at https://github.com/uclanlp/Fact-or-Fair.