 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLUR: A Bi-Level Optimization Approach for LLM Unlearning
Jun 09, 2025Enabling large language models (LLMs) to unlearn knowledge and capabilities acquired during training has proven vital for ensuring compliance with data regulations and promoting ethical practices in generative AI. Although there are growing interests in developing various unlearning algorithms, it remains unclear how to best formulate the unlearning problem. The most popular formulation uses a weighted sum of forget and retain loss, but it often leads to performance degradation due to the inherent trade-off between forget and retain losses. In this work, we argue that it is important to model the hierarchical structure of the unlearning problem, where the forget problem (which \textit{unlearns} certain knowledge and/or capabilities) takes priority over the retain problem (which preserves model utility). This hierarchical structure naturally leads to a bi-level optimization formulation where the lower-level objective focuses on minimizing the forget loss, while the upper-level objective aims to maintain the model's utility. Based on this new formulation, we propose a novel algorithm, termed Bi-Level UnleaRning (\texttt{BLUR}), which not only possesses strong theoretical guarantees but more importantly, delivers superior performance. In particular, our extensive experiments demonstrate that \texttt{BLUR} consistently outperforms all the state-of-the-art algorithms across various unlearning tasks, models, and metrics. Codes are available at https://github.com/OptimAI-Lab/BLURLLMUnlearning.
LUME: LLM Unlearning with Multitask Evaluations
Feb 20, 2025
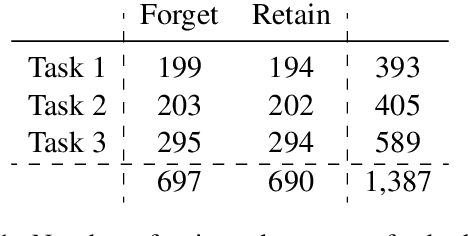
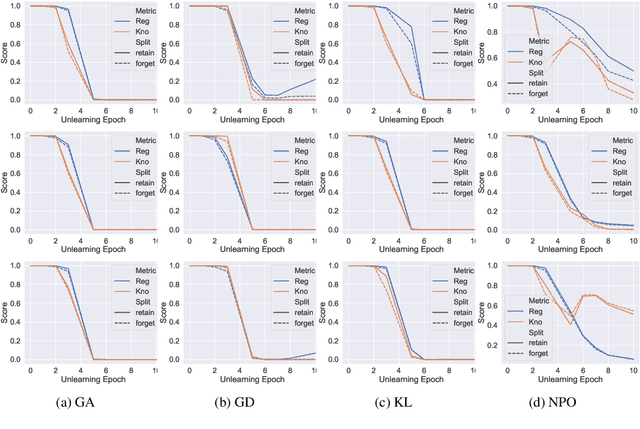
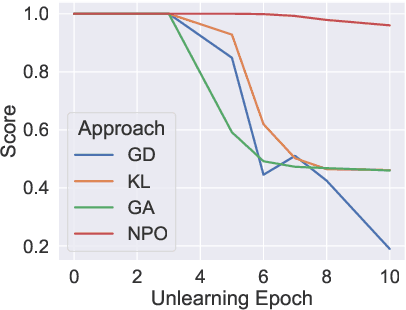
Unlearning aims to remove copyrighted, sensitive, or private content from large language models (LLMs) without a full retraining. In this work, we develop a multi-task unlearning benchmark (LUME) which features three tasks: (1) unlearn synthetically generated creative short novels, (2) unlearn synthetic biographies with sensitive information, and (3) unlearn a collection of public biographies. We further release two fine-tuned LLMs of 1B and 7B parameter sizes as the target models. We conduct detailed evaluations of several recently proposed unlearning algorithms and present results on carefully crafted metrics to understand their behavior and limitations.
Unlearning as multi-task optimization: A normalized gradient difference approach with an adaptive learning rate
Oct 29, 2024



Machine unlearning has been used to remove unwanted knowledge acquired by large language models (LLMs). In this paper, we examine machine unlearning from an optimization perspective, framing it as a regularized multi-task optimization problem, where one task optimizes a forgetting objective and another optimizes the model performance. In particular, we introduce a normalized gradient difference (NGDiff) algorithm, enabling us to have better control over the trade-off between the objectives, while integrating a new, automatic learning rate scheduler. We provide a theoretical analysis and empirically demonstrate the superior performance of NGDiff among state-of-the-art unlearning methods on the TOFU and MUSE datasets while exhibiting stable training.
Fair Representation Learning using Interpolation Enabled Disentanglement
Jul 31, 2021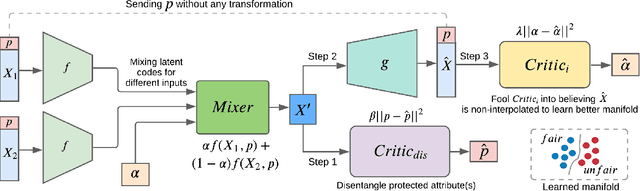

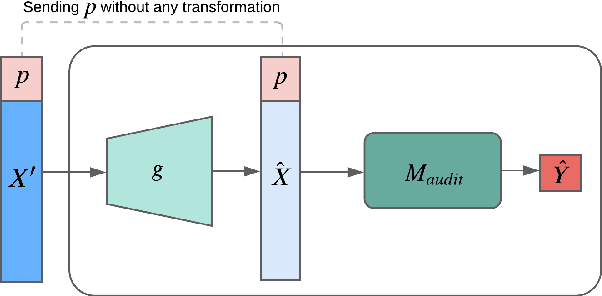
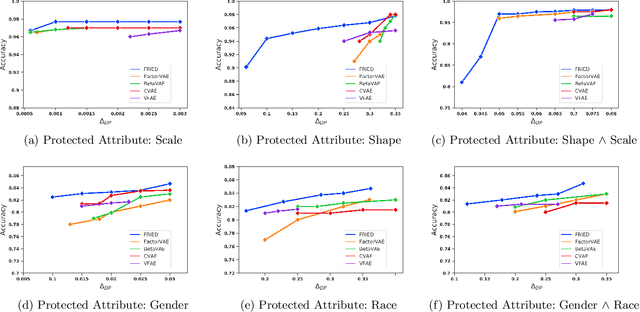
With the growing interest in the machine learning community to solve real-world problems, it has become crucial to uncover the hidden reasoning behind their decisions by focusing on the fairness and auditing the predictions made by these black-box models. In this paper, we propose a novel method to address two key issues: (a) Can we simultaneously learn fair disentangled representations while ensuring the utility of the learned representation for downstream tasks, and (b)Can we provide theoretical insights into when the proposed approach will be both fair and accurate. To address the former, we propose the method FRIED, Fair Representation learning using Interpolation Enabled Disentanglement. In our architecture, by imposing a critic-based adversarial framework, we enforce the interpolated points in the latent space to be more realistic. This helps in capturing the data manifold effectively and enhances the utility of the learned representation for downstream prediction tasks. We address the latter question by developing a theory on fairness-accuracy trade-offs using classifier-based conditional mutual information estimation. We demonstrate the effectiveness of FRIED on datasets of different modalities - tabular, text, and image datasets. We observe that the representations learned by FRIED are overall fairer in comparison to existing baselines and also accurate for downstream prediction tasks. Additionally, we evaluate FRIED on a real-world healthcare claims dataset where we conduct an expert aided model auditing study providing useful insights into opioid ad-diction patterns.
Model Agnostic Multilevel Explanations
Mar 12, 2020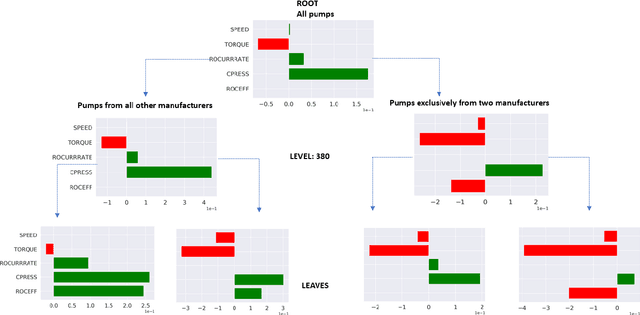
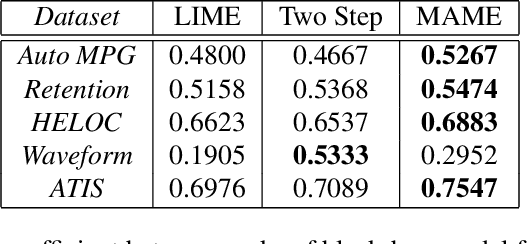
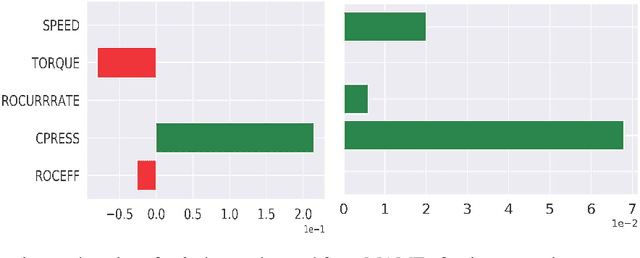
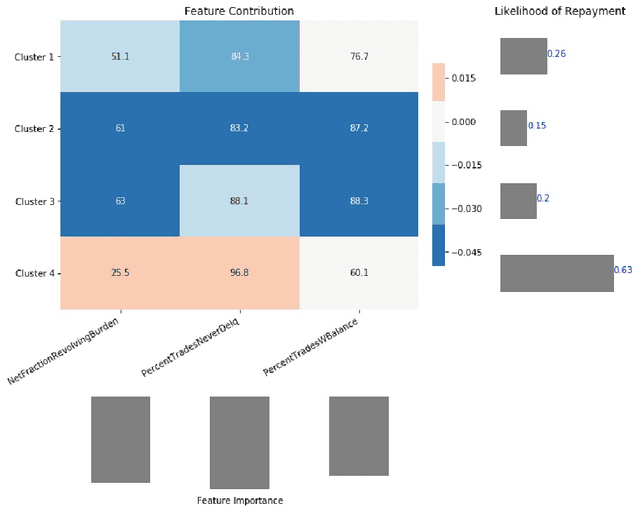
In recent years, post-hoc local instance-level and global dataset-level explainability of black-box models has received a lot of attention. Much less attention has been given to obtaining insights at intermediate or group levels, which is a need outlined in recent works that study the challenges in realizing the guidelines in the General Data Protection Regulation (GDPR). In this paper, we propose a meta-method that, given a typical local explainability method, can build a multilevel explanation tree. The leaves of this tree correspond to the local explanations, the root corresponds to the global explanation, and intermediate levels correspond to explanations for groups of data points that it automatically clusters. The method can also leverage side information, where users can specify points for which they may want the explanations to be similar. We argue that such a multilevel structure can also be an effective form of communication, where one could obtain few explanations that characterize the entire dataset by considering an appropriate level in our explanation tree. Explanations for novel test points can be cost-efficiently obtained by associating them with the closest training points. When the local explainability technique is generalized additive (viz. LIME, GAMs), we develop a fast approximate algorithm for building the multilevel tree and study its convergence behavior. We validate the effectiveness of the proposed technique based on two human studies -- one with experts and the other with non-expert users -- on real world datasets, and show that we produce high fidelity sparse explanations on several other public datasets.
Interpretable Subgroup Discovery in Treatment Effect Estimation with Application to Opioid Prescribing Guidelines
May 08, 2019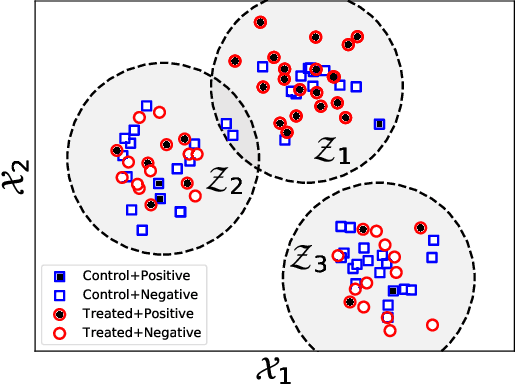
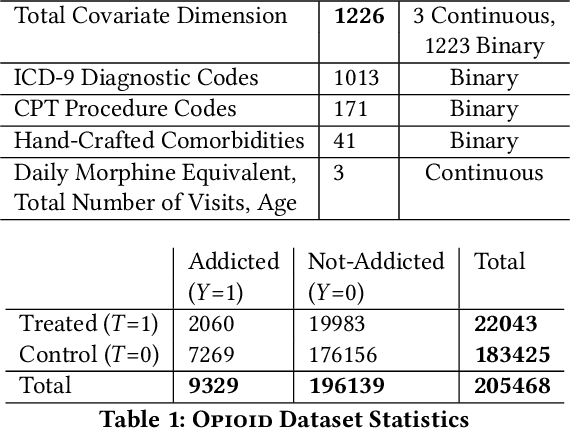
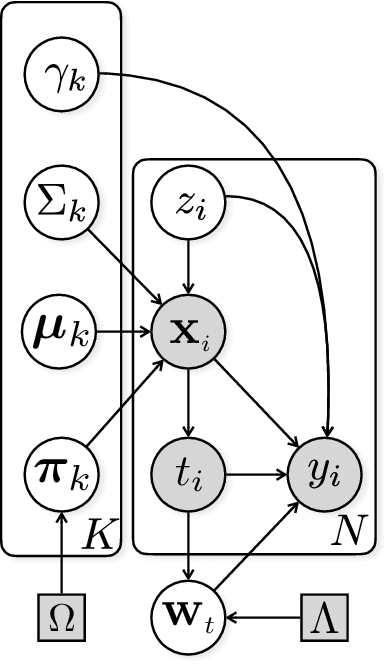
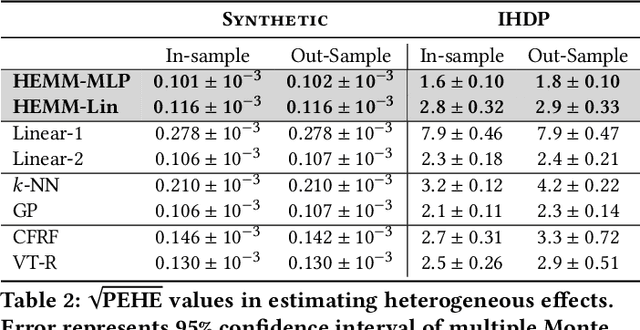
The dearth of prescribing guidelines for physicians is one key driver of the current opioid epidemic in the United States. In this work, we analyze medical and pharmaceutical claims data to draw insights on characteristics of patients who are more prone to adverse outcomes after an initial synthetic opioid prescription. Toward this end, we propose a generative model that allows discovery from observational data of subgroups that demonstrate an enhanced or diminished causal effect due to treatment. Our approach models these sub-populations as a mixture distribution, using sparsity to enhance interpretability, while jointly learning nonlinear predictors of the potential outcomes to better adjust for confounding. The approach leads to human-interpretable insights on discovered subgroups, improving the practical utility for decision support
Is Ordered Weighted $\ell_1$ Regularized Regression Robust to Adversarial Perturbation? A Case Study on OSCAR
Oct 03, 2018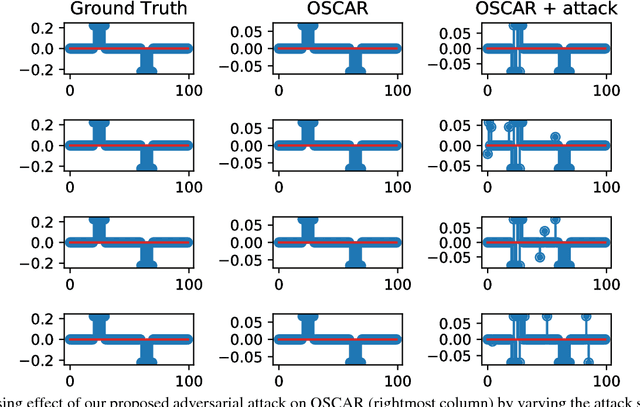
Many state-of-the-art machine learning models such as deep neural networks have recently shown to be vulnerable to adversarial perturbations, especially in classification tasks. Motivated by adversarial machine learning, in this paper we investigate the robustness of sparse regression models with strongly correlated covariates to adversarially designed measurement noises. Specifically, we consider the family of ordered weighted $\ell_1$ (OWL) regularized regression methods and study the case of OSCAR (octagonal shrinkage clustering algorithm for regression) in the adversarial setting. Under a norm-bounded threat model, we formulate the process of finding a maximally disruptive noise for OWL-regularized regression as an optimization problem and illustrate the steps towards finding such a noise in the case of OSCAR. Experimental results demonstrate that the regression performance of grouping strongly correlated features can be severely degraded under our adversarial setting, even when the noise budget is significantly smaller than the ground-truth signals.
Structure Learning from Time Series with False Discovery Control
May 24, 2018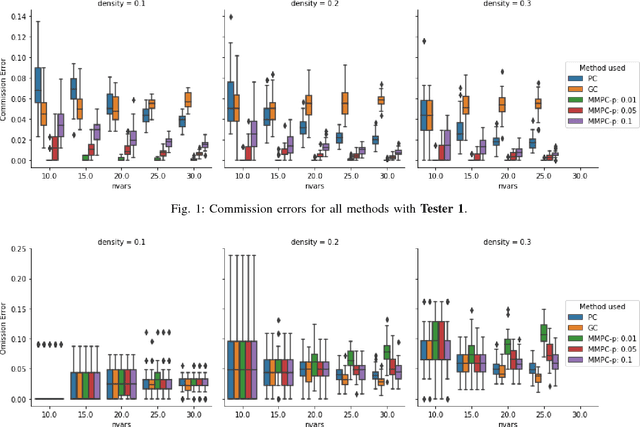
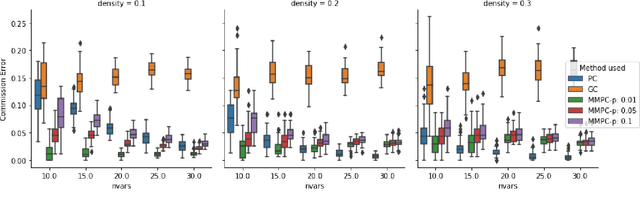
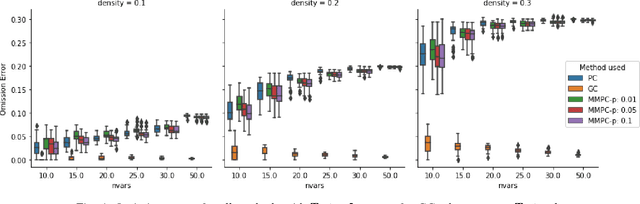
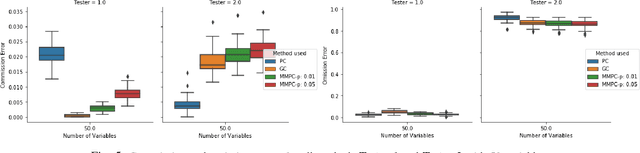
We consider the Granger causal structure learning problem from time series data. Granger causal algorithms predict a 'Granger causal effect' between two variables by testing if prediction error of one decreases significantly in the absence of the other variable among the predictor covariates. Almost all existing Granger causal algorithms condition on a large number of variables (all but two variables) to test for effects between a pair of variables. We propose a new structure learning algorithm called MMPC-p inspired by the well known MMHC algorithm for non-time series data. We show that under some assumptions, the algorithm provides false discovery rate control. The algorithm is sound and complete when given access to perfect directed information testing oracles. We also outline a novel tester for the linear Gaussian case. We show through our extensive experiments that the MMPC-p algorithm scales to larger problems and has improved statistical power compared to existing state of the art for large sparse graphs. We also apply our algorithm on a global development dataset and validate our findings with subject matter experts.