 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAID: A Benchmark for Bias Assessment of AI Detectors
Dec 12, 2025AI-generated text detectors have recently gained adoption in educational and professional contexts. Prior research has uncovered isolated cases of bias, particularly against English Language Learners (ELLs) however, there is a lack of systematic evaluation of such systems across broader sociolinguistic factors. In this work, we propose BAID, a comprehensive evaluation framework for AI detectors across various types of biases. As a part of the framework, we introduce over 200k samples spanning 7 major categories: demographics, age, educational grade level, dialect, formality, political leaning, and topic. We also generated synthetic versions of each sample with carefully crafted prompts to preserve the original content while reflecting subgroup-specific writing styles. Using this, we evaluate four open-source state-of-the-art AI text detectors and find consistent disparities in detection performance, particularly low recall rates for texts from underrepresented groups. Our contributions provide a scalable, transparent approach for auditing AI detectors and emphasize the need for bias-aware evaluation before these tools are deployed for public use.
Simulation-to-reality UAV Fault Diagnosis in windy environments
Sep 21, 2023Monitoring propeller failures is vital to maintain the safe and reliable operation of quadrotor UAVs. The simulation-to-reality UAV fault diagnosis technique offer a secure and economical approach to identify faults in propellers. However, classifiers trained with simulated data perform poorly in real flights due to the wind disturbance in outdoor scenarios. In this work, we propose an uncertainty-based fault classifier (UFC) to address the challenge of sim-to-real UAV fault diagnosis in windy scenarios. It uses the ensemble of difference-based deep convolutional neural networks (EDDCNN) to reduce model variance and bias. Moreover, it employs an uncertainty-based decision framework to filter out uncertain predictions. Experimental results demonstrate that the UFC can achieve 100% fault-diagnosis accuracy with a data usage rate of 33.6% in the windy outdoor scenario.
Difference-based Deep Convolutional Neural Network for Simulation-to-reality UAV Fault Diagnosis
Feb 16, 2023Identifying the fault in propellers is important to keep quadrotors operating safely and efficiently. The simulation-to-reality (sim-to-real) UAV fault diagnosis methods provide a cost-effective and safe approach to detect the propeller faults. However, due to the gap between simulation and reality, classifiers trained with simulated data usually underperform in real flights. In this work, a new deep neural network (DNN) model is presented to address the above issue. It uses the difference features extracted by deep convolutional neural networks (DDCNN) to reduce the sim-to-real gap. Moreover, a new domain adaptation method is presented to further bring the distribution of the real-flight data closer to that of the simulation data. The experimental results show that the proposed approach can achieve an accuracy of 97.9\% in detecting propeller faults in real flight. Feature visualization was performed to help better understand our DDCNN model.
Simulation-to-reality UAV Fault Diagnosis with Deep Learning
Feb 09, 2023Accurate diagnosis of propeller faults is crucial for ensuring the safe and efficient operation of quadrotors. Training a fault classifier using simulated data and deploying it on a real quadrotor is a cost-effective and safe approach. However, the simulation-to-reality gap often leads to poor performance of the classifier when applied in real flight. In this work, we propose a deep learning model that addresses this issue by utilizing newly identified features (NIF) as input and utilizing domain adaptation techniques to reduce the simulation-to-reality gap. In addition, we introduce an adjusted simulation model that generates training data that more accurately reflects the behavior of real quadrotors. The experimental results demonstrate that our proposed approach achieves an accuracy of 96\% in detecting propeller faults. To the best of our knowledge, this is the first reliable and efficient method for simulation-to-reality fault diagnosis of quadrotor propellers.
Connecting Algorithmic Research and Usage Contexts: A Perspective of Contextualized Evaluation for Explainable AI
Jun 22, 2022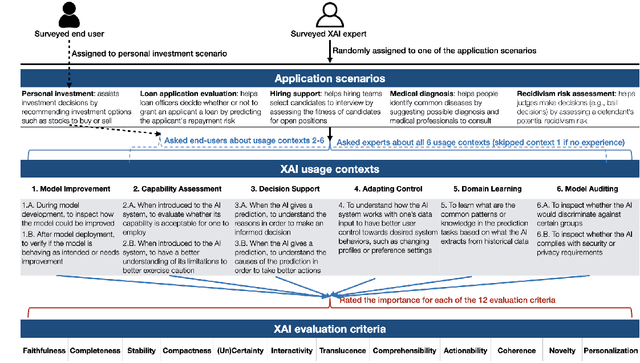


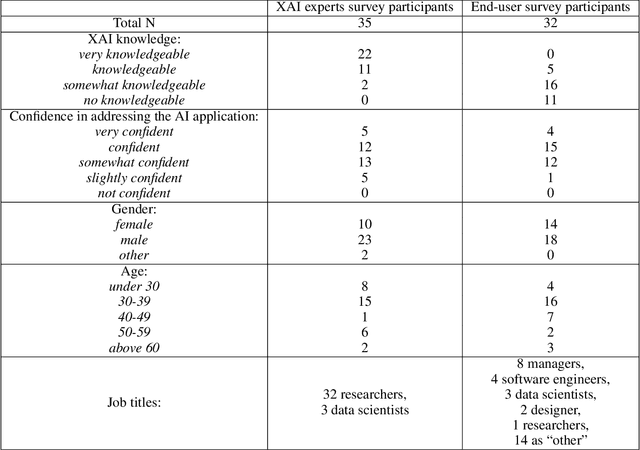
Recent years have seen a surge of interest in the field of explainable AI (XAI), with a plethora of algorithms proposed in the literature. However, a lack of consensus on how to evaluate XAI hinders the advancement of the field. We highlight that XAI is not a monolithic set of technologies -- researchers and practitioners have begun to leverage XAI algorithms to build XAI systems that serve different usage contexts, such as model debugging and decision-support. Algorithmic research of XAI, however, often does not account for these diverse downstream usage contexts, resulting in limited effectiveness or even unintended consequences for actual users, as well as difficulties for practitioners to make technical choices. We argue that one way to close the gap is to develop evaluation methods that account for different user requirements in these usage contexts. Towards this goal, we introduce a perspective of contextualized XAI evaluation by considering the relative importance of XAI evaluation criteria for prototypical usage contexts of XAI. To explore the context-dependency of XAI evaluation criteria, we conduct two survey studies, one with XAI topical experts and another with crowd workers. Our results urge for responsible AI research with usage-informed evaluation practices, and provide a nuanced understanding of user requirements for XAI in different usage contexts.
De-biasing "bias" measurement
May 11, 2022

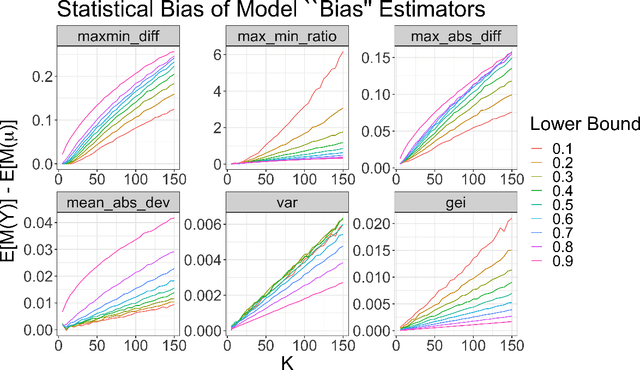
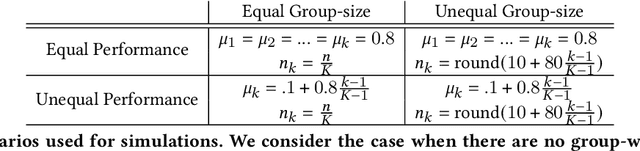
When a model's performance differs across socially or culturally relevant groups--like race, gender, or the intersections of many such groups--it is often called "biased." While much of the work in algorithmic fairness over the last several years has focused on developing various definitions of model fairness (the absence of group-wise model performance disparities) and eliminating such "bias," much less work has gone into rigorously measuring it. In practice, it important to have high quality, human digestible measures of model performance disparities and associated uncertainty quantification about them that can serve as inputs into multi-faceted decision-making processes. In this paper, we show both mathematically and through simulation that many of the metrics used to measure group-wise model performance disparities are themselves statistically biased estimators of the underlying quantities they purport to represent. We argue that this can cause misleading conclusions about the relative group-wise model performance disparities along different dimensions, especially in cases where some sensitive variables consist of categories with few members. We propose the "double-corrected" variance estimator, which provides unbiased estimates and uncertainty quantification of the variance of model performance across groups. It is conceptually simple and easily implementable without statistical software package or numerical optimization. We demonstrate the utility of this approach through simulation and show on a real dataset that while statistically biased estimators of model group-wise model performance disparities indicate statistically significant between-group model performance disparities, when accounting for statistical bias in the estimator, the estimated group-wise disparities in model performance are no longer statistically significant.
Human-AI Collaboration via Conditional Delegation: A Case Study of Content Moderation
Apr 25, 2022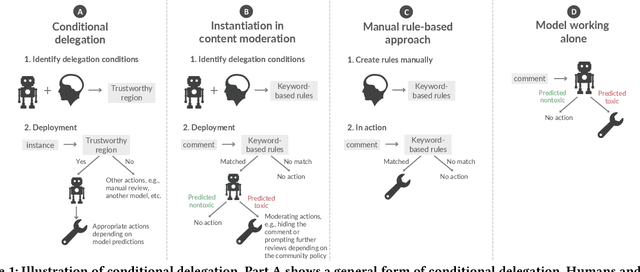

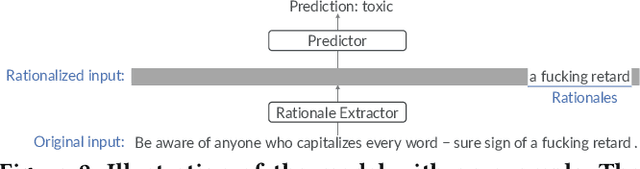
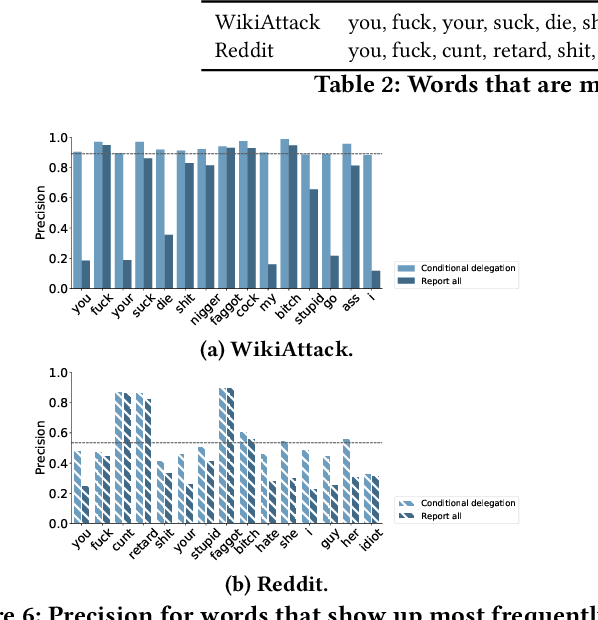
Despite impressive performance in many benchmark datasets, AI models can still make mistakes, especially among out-of-distribution examples. It remains an open question how such imperfect models can be used effectively in collaboration with humans. Prior work has focused on AI assistance that helps people make individual high-stakes decisions, which is not scalable for a large amount of relatively low-stakes decisions, e.g., moderating social media comments. Instead, we propose conditional delegation as an alternative paradigm for human-AI collaboration where humans create rules to indicate trustworthy regions of a model. Using content moderation as a testbed, we develop novel interfaces to assist humans in creating conditional delegation rules and conduct a randomized experiment with two datasets to simulate in-distribution and out-of-distribution scenarios. Our study demonstrates the promise of conditional delegation in improving model performance and provides insights into design for this novel paradigm, including the effect of AI explanations.
AI Explainability 360: Impact and Design
Sep 24, 2021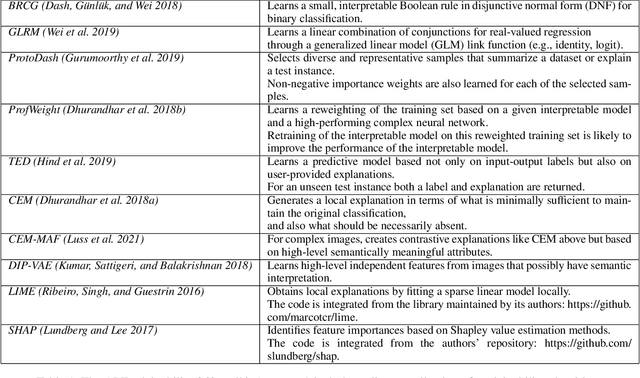
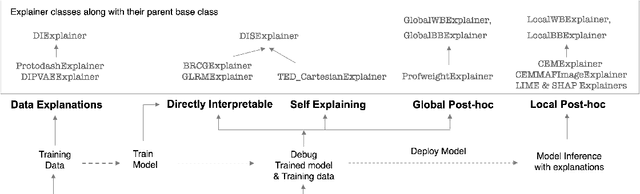

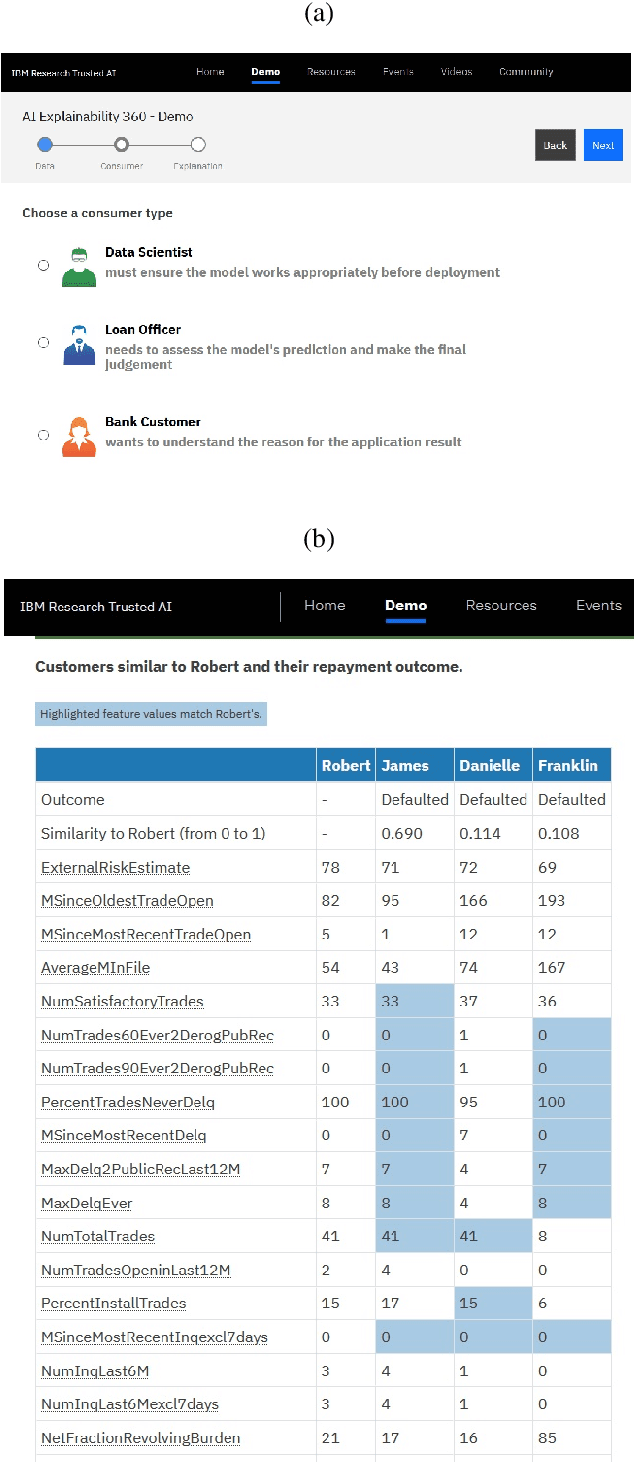
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
Uncertainty Quantification 360: A Holistic Toolkit for Quantifying and Communicating the Uncertainty of AI
Jun 04, 2021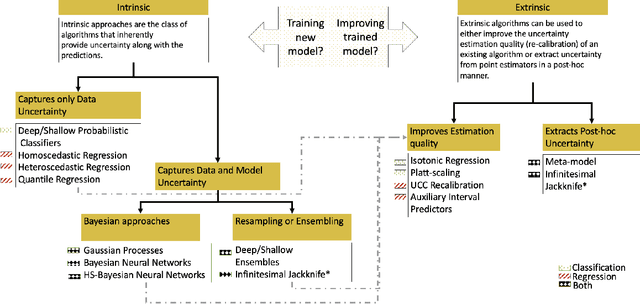
In this paper, we describe an open source Python toolkit named Uncertainty Quantification 360 (UQ360) for the uncertainty quantification of AI models. The goal of this toolkit is twofold: first, to provide a broad range of capabilities to streamline as well as foster the common practices of quantifying, evaluating, improving, and communicating uncertainty in the AI application development lifecycle; second, to encourage further exploration of UQ's connections to other pillars of trustworthy AI such as fairness and transparency through the dissemination of latest research and education materials. Beyond the Python package (\url{https://github.com/IBM/UQ360}), we have developed an interactive experience (\url{http://uq360.mybluemix.net}) and guidance materials as educational tools to aid researchers and developers in producing and communicating high-quality uncertainties in an effective manner.
D2S: Document-to-Slide Generation Via Query-Based Text Summarization
May 08, 2021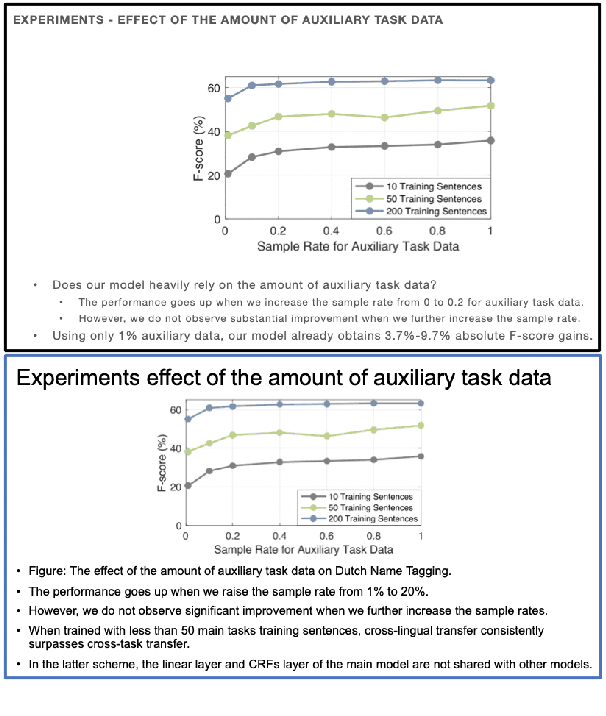
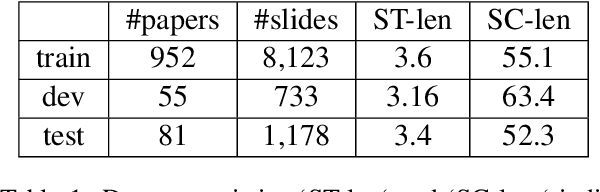

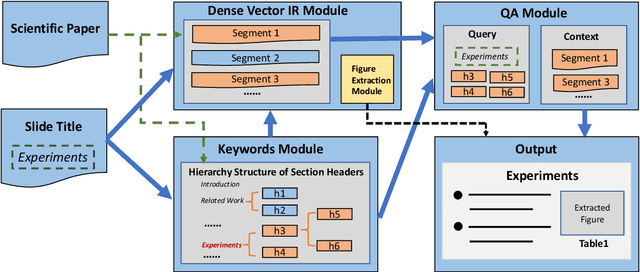
Presentations are critical for communication in all areas of our lives, yet the creation of slide decks is often tedious and time-consuming. There has been limited research aiming to automate the document-to-slides generation process and all face a critical challenge: no publicly available dataset for training and benchmarking. In this work, we first contribute a new dataset, SciDuet, consisting of pairs of papers and their corresponding slides decks from recent years' NLP and ML conferences (e.g., ACL). Secondly, we present D2S, a novel system that tackles the document-to-slides task with a two-step approach: 1) Use slide titles to retrieve relevant and engaging text, figures, and tables; 2) Summarize the retrieved context into bullet points with long-form question answering. Our evaluation suggests that long-form QA outperforms state-of-the-art summarization baselines on both automated ROUGE metrics and qualitative human evaluation.