 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnecting Algorithmic Research and Usage Contexts: A Perspective of Contextualized Evaluation for Explainable AI
Paper and Code
Jun 22, 2022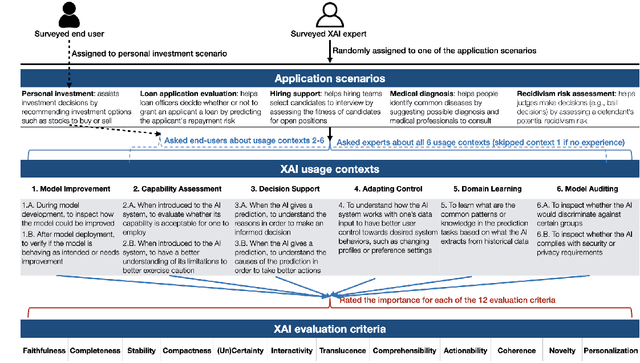


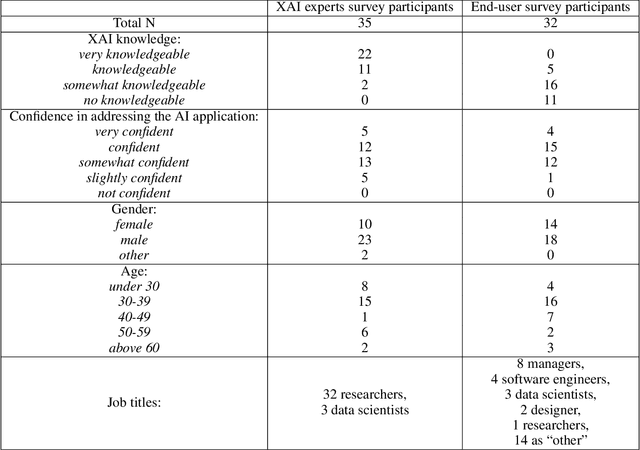
Recent years have seen a surge of interest in the field of explainable AI (XAI), with a plethora of algorithms proposed in the literature. However, a lack of consensus on how to evaluate XAI hinders the advancement of the field. We highlight that XAI is not a monolithic set of technologies -- researchers and practitioners have begun to leverage XAI algorithms to build XAI systems that serve different usage contexts, such as model debugging and decision-support. Algorithmic research of XAI, however, often does not account for these diverse downstream usage contexts, resulting in limited effectiveness or even unintended consequences for actual users, as well as difficulties for practitioners to make technical choices. We argue that one way to close the gap is to develop evaluation methods that account for different user requirements in these usage contexts. Towards this goal, we introduce a perspective of contextualized XAI evaluation by considering the relative importance of XAI evaluation criteria for prototypical usage contexts of XAI. To explore the context-dependency of XAI evaluation criteria, we conduct two survey studies, one with XAI topical experts and another with crowd workers. Our results urge for responsible AI research with usage-informed evaluation practices, and provide a nuanced understanding of user requirements for XAI in different usage contexts.