 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Misalignment Contagion by Steering with Implicit Traits
May 04, 2026Language models (LMs) are increasingly used in high-stakes, multi-agent settings, where following instructions and maintaining value alignment are critical. Most alignment research focuses on interactions between a single LM and a single user, failing to address the risk of misaligned behavior spreading between multiple LMs in multi-turn interactions. We find evidence of this phenomenon, which we call misalignment contagion, across multiple LMs as they engage multi-turn conversational social dilemma games. Specifically, we find that LMs become more anti-social after gameplay and that this effect is intensified when other players are steered to act maliciously. We explore different steering techniques to mitigate such misalignment contagion and find that reinforcing an LM's system prompt is insufficient and often harmful. Instead, we propose steering with implicit traits: a technique that intermittently injects system prompts with statements that reinforce an LMs initial traits and is more effective than system prompt repetition at keeping models in line with their initial pro-social behaviors. Importantly, this method does not require access to model parameters or internal model states, making it suitable for increasingly common use cases where complex multi-agent workflows are being designed with black box models.
ICX360: In-Context eXplainability 360 Toolkit
Nov 14, 2025Large Language Models (LLMs) have become ubiquitous in everyday life and are entering higher-stakes applications ranging from summarizing meeting transcripts to answering doctors' questions. As was the case with earlier predictive models, it is crucial that we develop tools for explaining the output of LLMs, be it a summary, list, response to a question, etc. With these needs in mind, we introduce In-Context Explainability 360 (ICX360), an open-source Python toolkit for explaining LLMs with a focus on the user-provided context (or prompts in general) that are fed to the LLMs. ICX360 contains implementations for three recent tools that explain LLMs using both black-box and white-box methods (via perturbations and gradients respectively). The toolkit, available at https://github.com/IBM/ICX360, contains quick-start guidance materials as well as detailed tutorials covering use cases such as retrieval augmented generation, natural language generation, and jailbreaking.
Sparsity May Be All You Need: Sparse Random Parameter Adaptation
Feb 21, 2025Full fine-tuning of large language models for alignment and task adaptation has become prohibitively expensive as models have grown in size. Parameter-Efficient Fine-Tuning (PEFT) methods aim at significantly reducing the computational and memory resources needed for fine-tuning these models by only training on a small number of parameters instead of all model parameters. Currently, the most popular PEFT method is the Low-Rank Adaptation (LoRA), which freezes the parameters of the model to be fine-tuned and introduces a small set of trainable parameters in the form of low-rank matrices. We propose simply reducing the number of trainable parameters by randomly selecting a small proportion of the model parameters to train on. In this paper, we compare the efficiency and performance of our proposed approach with PEFT methods, including LoRA, as well as full parameter fine-tuning.
CELL your Model: Contrastive Explanation Methods for Large Language Models
Jun 17, 2024The advent of black-box deep neural network classification models has sparked the need to explain their decisions. However, in the case of generative AI such as large language models (LLMs), there is no class prediction to explain. Rather, one can ask why an LLM output a particular response to a given prompt. In this paper, we answer this question by proposing, to the best of our knowledge, the first contrastive explanation methods requiring simply black-box/query access. Our explanations suggest that an LLM outputs a reply to a given prompt because if the prompt was slightly modified, the LLM would have given a different response that is either less preferable or contradicts the original response. The key insight is that contrastive explanations simply require a distance function that has meaning to the user and not necessarily a real valued representation of a specific response (viz. class label). We offer two algorithms for finding contrastive explanations: i) A myopic algorithm, which although effective in creating contrasts, requires many model calls and ii) A budgeted algorithm, our main algorithmic contribution, which intelligently creates contrasts adhering to a query budget, necessary for longer contexts. We show the efficacy of these methods on diverse natural language tasks such as open-text generation, automated red teaming, and explaining conversational degradation.
Multi-Level Explanations for Generative Language Models
Mar 21, 2024
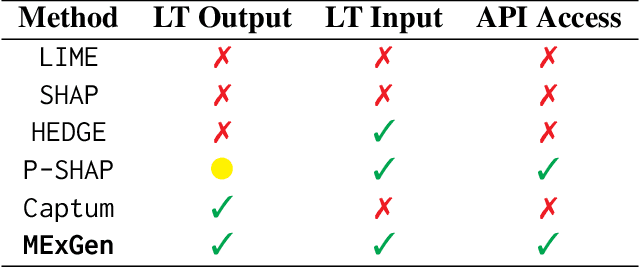
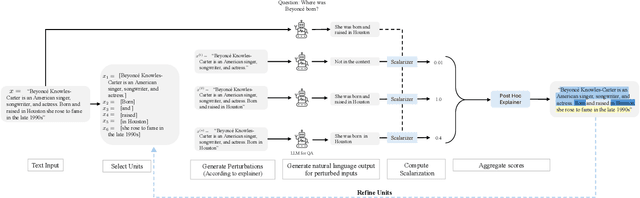

Perturbation-based explanation methods such as LIME and SHAP are commonly applied to text classification. This work focuses on their extension to generative language models. To address the challenges of text as output and long text inputs, we propose a general framework called MExGen that can be instantiated with different attribution algorithms. To handle text output, we introduce the notion of scalarizers for mapping text to real numbers and investigate multiple possibilities. To handle long inputs, we take a multi-level approach, proceeding from coarser levels of granularity to finer ones, and focus on algorithms with linear scaling in model queries. We conduct a systematic evaluation, both automated and human, of perturbation-based attribution methods for summarization and context-grounded question answering. The results show that our framework can provide more locally faithful explanations of generated outputs.
Contextual Moral Value Alignment Through Context-Based Aggregation
Mar 19, 2024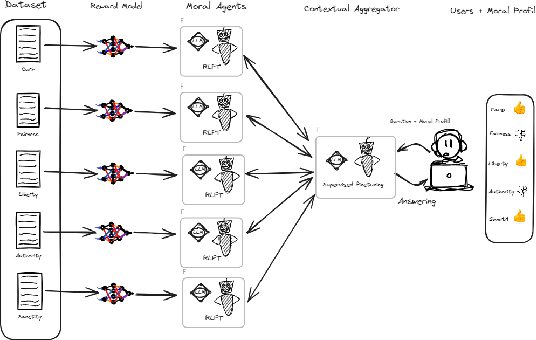
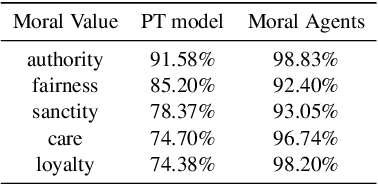
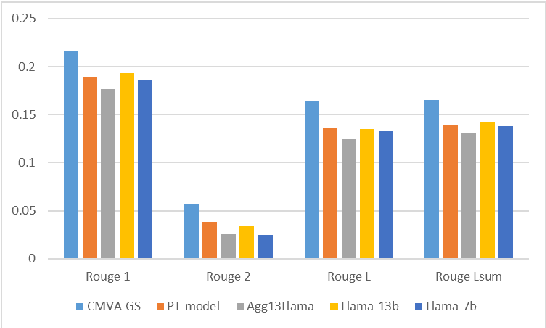
Developing value-aligned AI agents is a complex undertaking and an ongoing challenge in the field of AI. Specifically within the domain of Large Language Models (LLMs), the capability to consolidate multiple independently trained dialogue agents, each aligned with a distinct moral value, into a unified system that can adapt to and be aligned with multiple moral values is of paramount importance. In this paper, we propose a system that does contextual moral value alignment based on contextual aggregation. Here, aggregation is defined as the process of integrating a subset of LLM responses that are best suited to respond to a user input, taking into account features extracted from the user's input. The proposed system shows better results in term of alignment to human value compared to the state of the art.
Connecting Algorithmic Research and Usage Contexts: A Perspective of Contextualized Evaluation for Explainable AI
Jun 22, 2022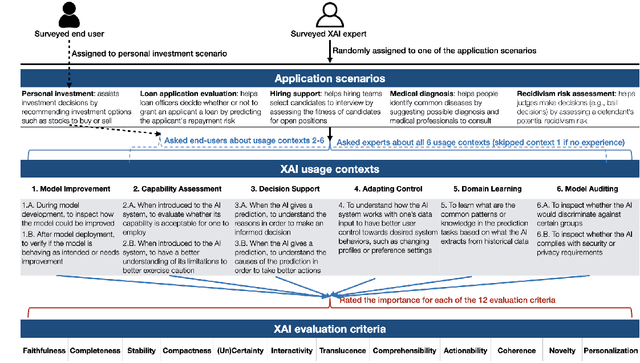


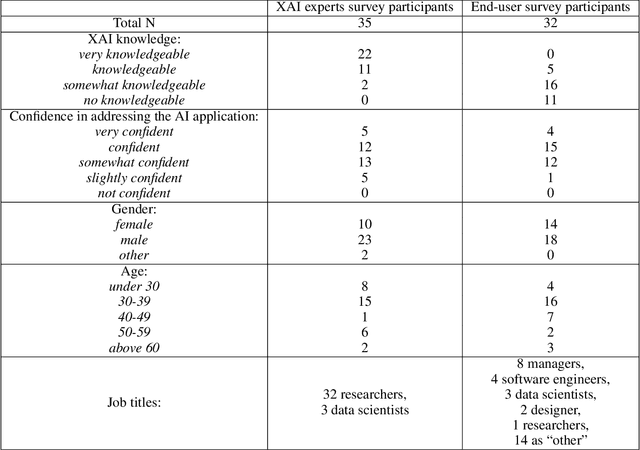
Recent years have seen a surge of interest in the field of explainable AI (XAI), with a plethora of algorithms proposed in the literature. However, a lack of consensus on how to evaluate XAI hinders the advancement of the field. We highlight that XAI is not a monolithic set of technologies -- researchers and practitioners have begun to leverage XAI algorithms to build XAI systems that serve different usage contexts, such as model debugging and decision-support. Algorithmic research of XAI, however, often does not account for these diverse downstream usage contexts, resulting in limited effectiveness or even unintended consequences for actual users, as well as difficulties for practitioners to make technical choices. We argue that one way to close the gap is to develop evaluation methods that account for different user requirements in these usage contexts. Towards this goal, we introduce a perspective of contextualized XAI evaluation by considering the relative importance of XAI evaluation criteria for prototypical usage contexts of XAI. To explore the context-dependency of XAI evaluation criteria, we conduct two survey studies, one with XAI topical experts and another with crowd workers. Our results urge for responsible AI research with usage-informed evaluation practices, and provide a nuanced understanding of user requirements for XAI in different usage contexts.
Local Explanations for Reinforcement Learning
Feb 08, 2022Many works in explainable AI have focused on explaining black-box classification models. Explaining deep reinforcement learning (RL) policies in a manner that could be understood by domain users has received much less attention. In this paper, we propose a novel perspective to understanding RL policies based on identifying important states from automatically learned meta-states. The key conceptual difference between our approach and many previous ones is that we form meta-states based on locality governed by the expert policy dynamics rather than based on similarity of actions, and that we do not assume any particular knowledge of the underlying topology of the state space. Theoretically, we show that our algorithm to find meta-states converges and the objective that selects important states from each meta-state is submodular leading to efficient high quality greedy selection. Experiments on four domains (four rooms, door-key, minipacman, and pong) and a carefully conducted user study illustrate that our perspective leads to better understanding of the policy. We conjecture that this is a result of our meta-states being more intuitive in that the corresponding important states are strong indicators of tractable intermediate goals that are easier for humans to interpret and follow.
Auto-Transfer: Learning to Route Transferrable Representations
Feb 04, 2022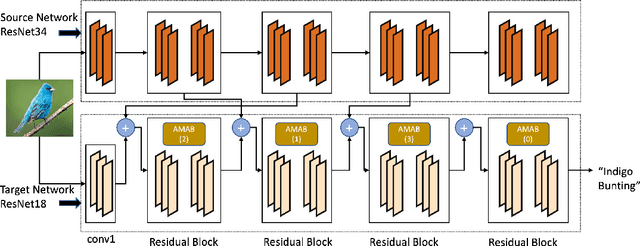
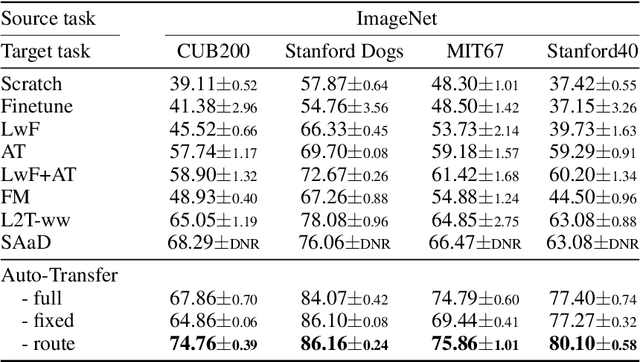
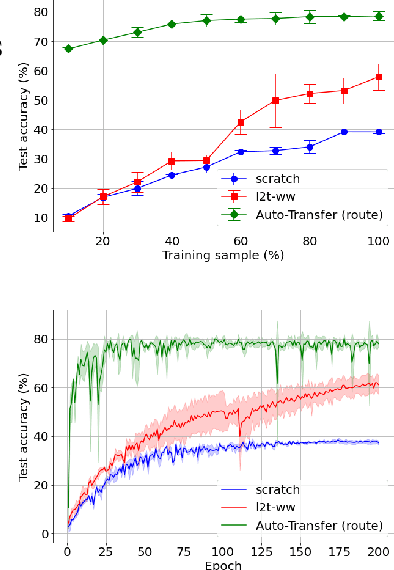

Knowledge transfer between heterogeneous source and target networks and tasks has received a lot of attention in recent times as large amounts of quality labelled data can be difficult to obtain in many applications. Existing approaches typically constrain the target deep neural network (DNN) feature representations to be close to the source DNNs feature representations, which can be limiting. We, in this paper, propose a novel adversarial multi-armed bandit approach which automatically learns to route source representations to appropriate target representations following which they are combined in meaningful ways to produce accurate target models. We see upwards of 5% accuracy improvements compared with the state-of-the-art knowledge transfer methods on four benchmark (target) image datasets CUB200, Stanford Dogs, MIT67, and Stanford40 where the source dataset is ImageNet. We qualitatively analyze the goodness of our transfer scheme by showing individual examples of the important features our target network focuses on in different layers compared with the (closest) competitors. We also observe that our improvement over other methods is higher for smaller target datasets making it an effective tool for small data applications that may benefit from transfer learning.
AI Explainability 360: Impact and Design
Sep 24, 2021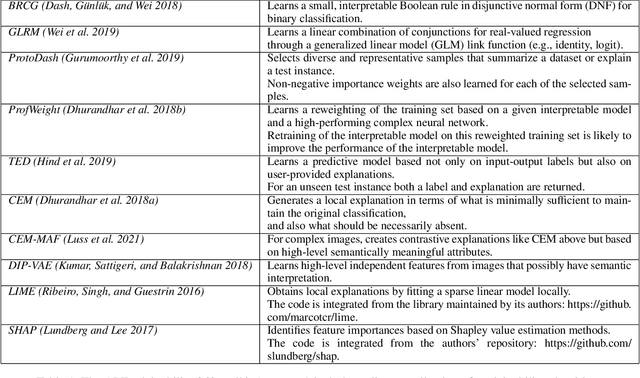
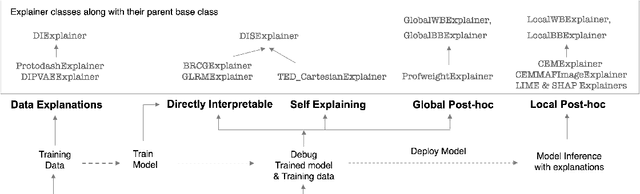

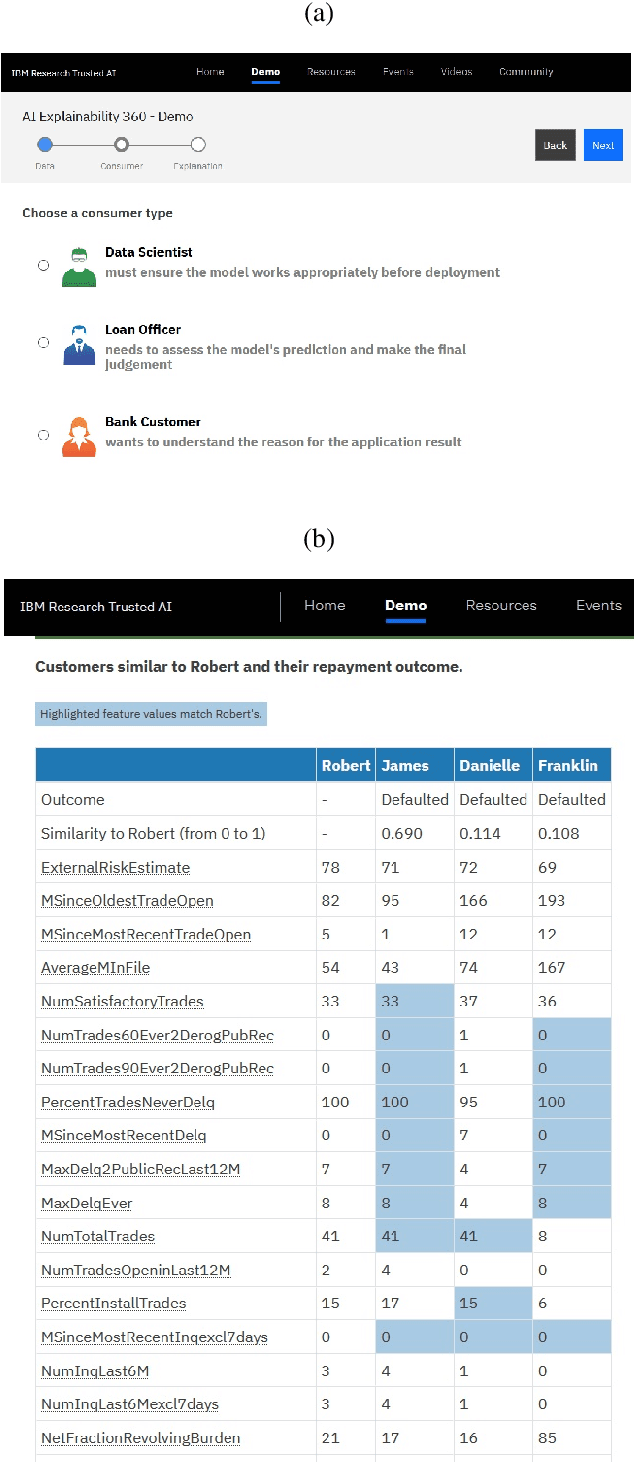
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.