 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Role of Natural Language Code Comments in Code Translation
Jan 23, 2026The advent of large language models (LLMs) has ushered in a new era in automated code translation across programming languages. Since most code-specific LLMs are pretrained on well-commented code from large repositories like GitHub, it is reasonable to hypothesize that natural language code comments could aid in improving translation quality. Despite their potential relevance, comments are largely absent from existing code translation benchmarks, rendering their impact on translation quality inadequately characterised. In this paper, we present a large-scale empirical study evaluating the impact of comments on translation performance. Our analysis involves more than $80,000$ translations, with and without comments, of $1100+$ code samples from two distinct benchmarks covering pairwise translations between five different programming languages: C, C++, Go, Java, and Python. Our results provide strong evidence that code comments, particularly those that describe the overall purpose of the code rather than line-by-line functionality, significantly enhance translation accuracy. Based on these findings, we propose COMMENTRA, a code translation approach, and demonstrate that it can potentially double the performance of LLM-based code translation. To the best of our knowledge, our study is the first in terms of its comprehensiveness, scale, and language coverage on how to improve code translation accuracy using code comments.
Locally Invariant Explanations: Towards Stable and Unidirectional Explanations through Local Invariant Learning
Jan 28, 2022Locally interpretable model agnostic explanations (LIME) method is one of the most popular methods used to explain black-box models at a per example level. Although many variants have been proposed, few provide a simple way to produce high fidelity explanations that are also stable and intuitive. In this work, we provide a novel perspective by proposing a model agnostic local explanation method inspired by the invariant risk minimization (IRM) principle -- originally proposed for (global) out-of-distribution generalization -- to provide such high fidelity explanations that are also stable and unidirectional across nearby examples. Our method is based on a game theoretic formulation where we theoretically show that our approach has a strong tendency to eliminate features where the gradient of the black-box function abruptly changes sign in the locality of the example we want to explain, while in other cases it is more careful and will choose a more conservative (feature) attribution, a behavior which can be highly desirable for recourse. Empirically, we show on tabular, image and text data that the quality of our explanations with neighborhoods formed using random perturbations are much better than LIME and in some cases even comparable to other methods that use realistic neighbors sampled from the data manifold. This is desirable given that learning a manifold to either create realistic neighbors or to project explanations is typically expensive or may even be impossible. Moreover, our algorithm is simple and efficient to train, and can ascertain stable input features for local decisions of a black-box without access to side information such as a (partial) causal graph as has been seen in some recent works.
AI Explainability 360: Impact and Design
Sep 24, 2021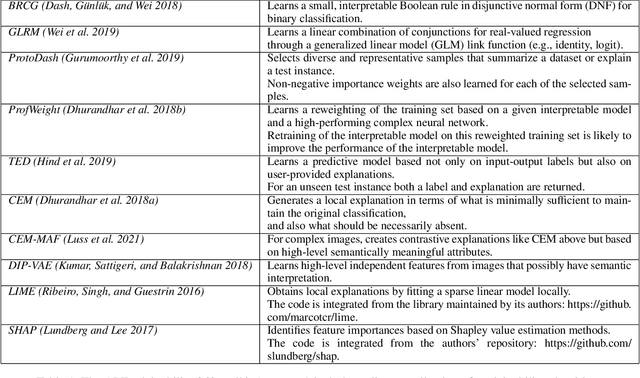
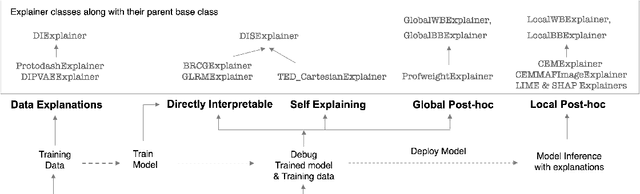

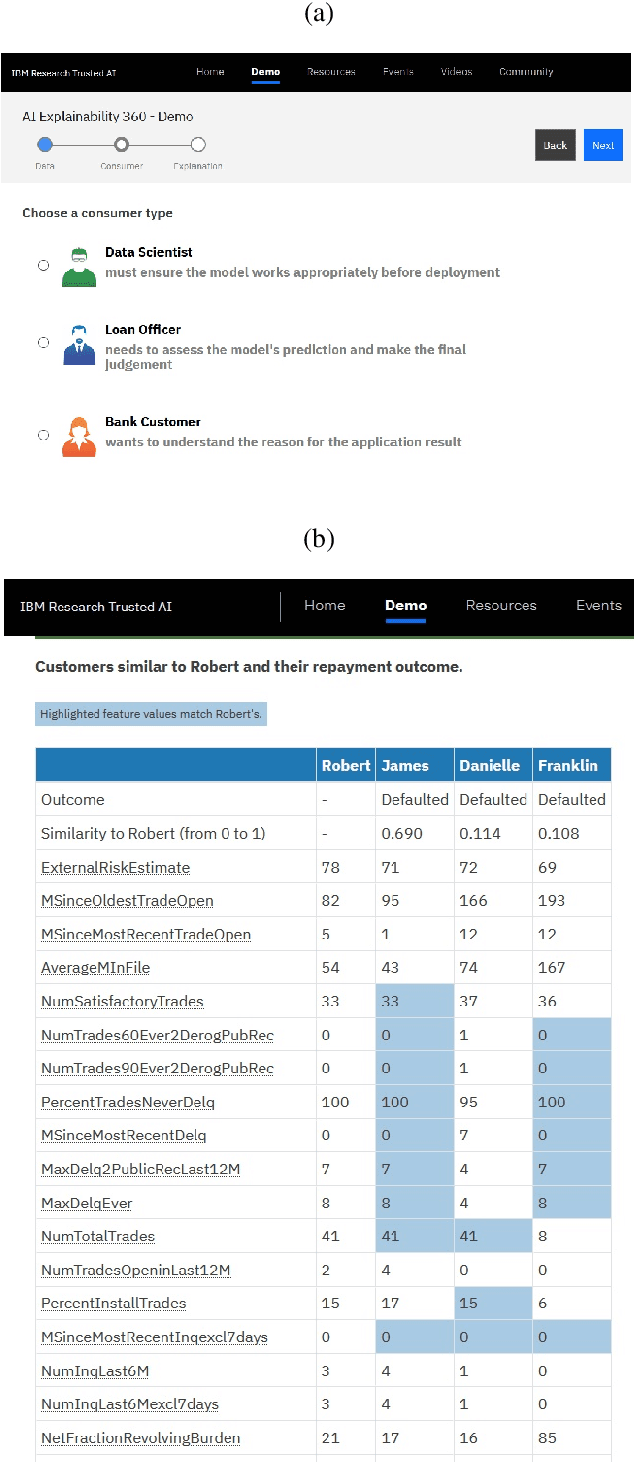
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
Fair Transfer of Multiple Style Attributes in Text
Jan 18, 2020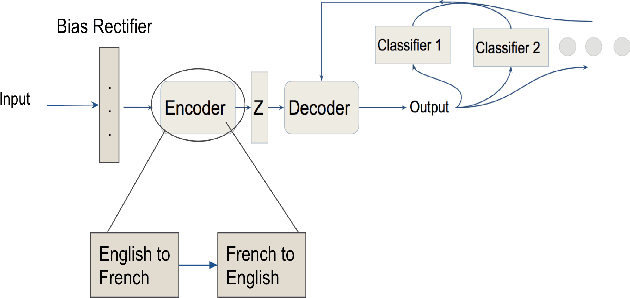



To preserve anonymity and obfuscate their identity on online platforms users may morph their text and portray themselves as a different gender or demographic. Similarly, a chatbot may need to customize its communication style to improve engagement with its audience. This manner of changing the style of written text has gained significant attention in recent years. Yet these past research works largely cater to the transfer of single style attributes. The disadvantage of focusing on a single style alone is that this often results in target text where other existing style attributes behave unpredictably or are unfairly dominated by the new style. To counteract this behavior, it would be nice to have a style transfer mechanism that can transfer or control multiple styles simultaneously and fairly. Through such an approach, one could obtain obfuscated or written text incorporated with a desired degree of multiple soft styles such as female-quality, politeness, or formalness. In this work, we demonstrate that the transfer of multiple styles cannot be achieved by sequentially performing multiple single-style transfers. This is because each single style-transfer step often reverses or dominates over the style incorporated by a previous transfer step. We then propose a neural network architecture for fairly transferring multiple style attributes in a given text. We test our architecture on the Yelp data set to demonstrate our superior performance as compared to existing one-style transfer steps performed in a sequence.
One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques
Sep 14, 2019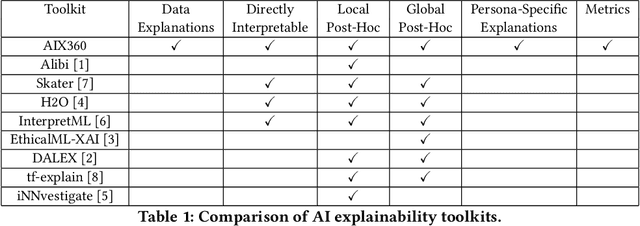
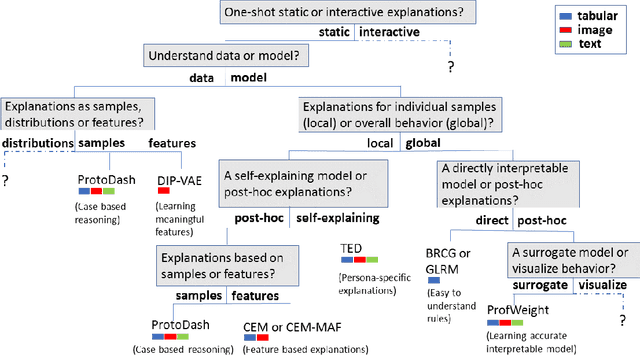
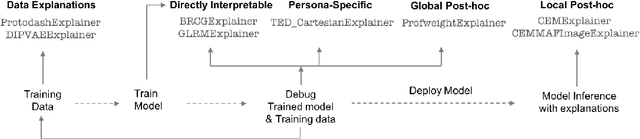
As artificial intelligence and machine learning algorithms make further inroads into society, calls are increasing from multiple stakeholders for these algorithms to explain their outputs. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, present different requirements for explanations. Toward addressing these needs, we introduce AI Explainability 360 (http://aix360.mybluemix.net/), an open-source software toolkit featuring eight diverse and state-of-the-art explainability methods and two evaluation metrics. Equally important, we provide a taxonomy to help entities requiring explanations to navigate the space of explanation methods, not only those in the toolkit but also in the broader literature on explainability. For data scientists and other users of the toolkit, we have implemented an extensible software architecture that organizes methods according to their place in the AI modeling pipeline. We also discuss enhancements to bring research innovations closer to consumers of explanations, ranging from simplified, more accessible versions of algorithms, to tutorials and an interactive web demo to introduce AI explainability to different audiences and application domains. Together, our toolkit and taxonomy can help identify gaps where more explainability methods are needed and provide a platform to incorporate them as they are developed.
Blockchain Enabled Trustless API Marketplace
Dec 05, 2018
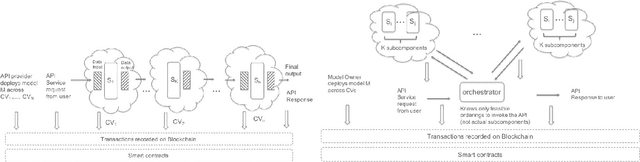
There has been an unprecedented surge in the number of service providers offering a wide range of machine learning prediction APIs for tasks such as image classification, language translation, etc. thereby monetizing the underlying data and trained models. Typically, a data owner (API provider) develops a model, often over proprietary data, and leverages the infrastructure services of a cloud vendor for hosting and serving API requests. Clearly, this model assumes complete trust between the API Provider and cloud vendor. On the other hand, a malicious/buggy cloud vendor may copy the APIs and offer an identical service, under-report model usage metrics, or unfairly discriminate between different API providers by offering them a nominal share of the revenue. In this work, we present the design of a blockchain based decentralized trustless API marketplace that enables all the stakeholders in the API ecosystem to audit the behavior of the parties without having to trust a single centralized entity. In particular, our system divides an AI model into multiple pieces and deploys them among multiple cloud vendors who then collaboratively execute the APIs. Our design ensures that cloud vendors cannot collude with each other to steal the combined model, while individual cloud vendors and clients cannot repudiate their input or model executions.
Model Extraction Warning in MLaaS Paradigm
Nov 20, 2017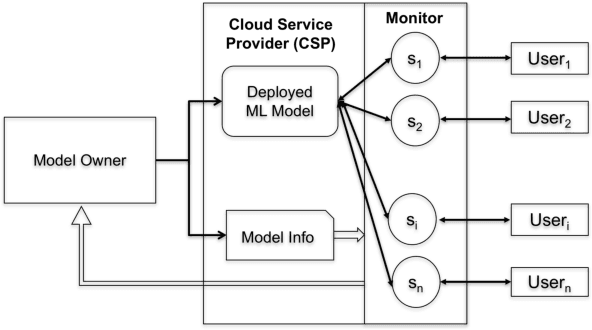
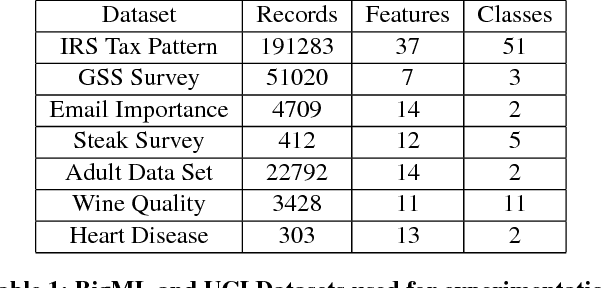
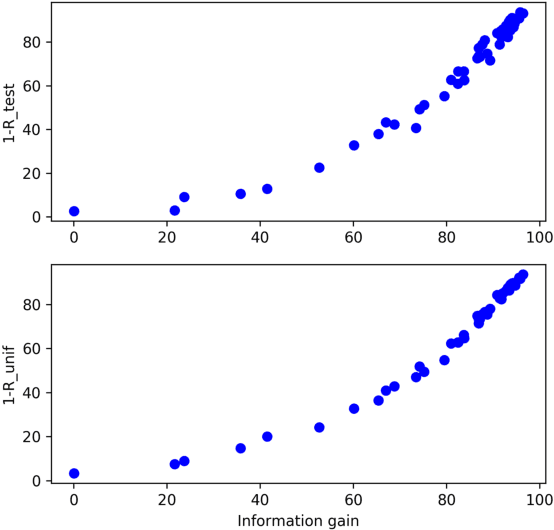
Cloud vendors are increasingly offering machine learning services as part of their platform and services portfolios. These services enable the deployment of machine learning models on the cloud that are offered on a pay-per-query basis to application developers and end users. However recent work has shown that the hosted models are susceptible to extraction attacks. Adversaries may launch queries to steal the model and compromise future query payments or privacy of the training data. In this work, we present a cloud-based extraction monitor that can quantify the extraction status of models by observing the query and response streams of both individual and colluding adversarial users. We present a novel technique that uses information gain to measure the model learning rate by users with increasing number of queries. Additionally, we present an alternate technique that maintains intelligent query summaries to measure the learning rate relative to the coverage of the input feature space in the presence of collusion. Both these approaches have low computational overhead and can easily be offered as services to model owners to warn them of possible extraction attacks from adversaries. We present performance results for these approaches for decision tree models deployed on BigML MLaaS platform, using open source datasets and different adversarial attack strategies.
Recovery of a Sparse Integer Solution to an Underdetermined System of Linear Equations
Dec 28, 2011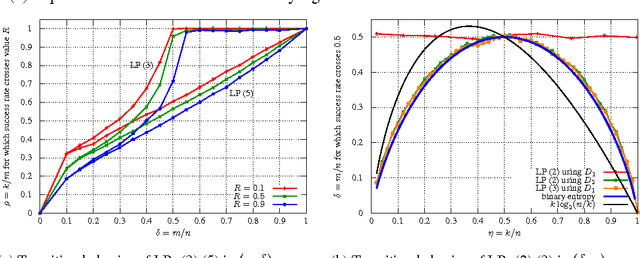
We consider a system of m linear equations in n variables Ax=b where A is a given m x n matrix and b is a given m-vector known to be equal to Ax' for some unknown solution x' that is integer and k-sparse: x' in {0,1}^n and exactly k entries of x' are 1. We give necessary and sufficient conditions for recovering the solution x exactly using an LP relaxation that minimizes l1 norm of x. When A is drawn from a distribution that has exchangeable columns, we show an interesting connection between the recovery probability and a well known problem in geometry, namely the k-set problem. To the best of our knowledge, this connection appears to be new in the compressive sensing literature. We empirically show that for large n if the elements of A are drawn i.i.d. from the normal distribution then the performance of the recovery LP exhibits a phase transition, i.e., for each k there exists a value m' of m such that the recovery always succeeds if m > m' and always fails if m < m'. Using the empirical data we conjecture that m' = nH(k/n)/2 where H(x) = -(x)log_2(x) - (1-x)log_2(1-x) is the binary entropy function.