 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic DAG-Orchestrated Planner Framework for Multi-Modal, Multi-Hop Question Answering in Hybrid Data Lakes
Mar 15, 2026Enterprises increasingly need natural language (NL) question answering over hybrid data lakes that combine structured tables and unstructured documents. Current deployed solutions, including RAG-based systems, typically rely on brute-force retrieval from each store and post-hoc merging. Such approaches are inefficient and leaky, and more critically, they lack explicit support for multi-hop reasoning, where a query is decomposed into successive steps (hops) that may traverse back and forth between structured and unstructured sources. We present Agentic DAG-Orchestrated Transformer (A.DOT) Planner, a framework for multi-modal, multi-hop question answering, that compiles user NL queries into directed acyclic graph (DAG) execution plans spanning both structured and unstructured stores. The system decomposes queries into parallelizable sub-queries, incorporates schema-aware reasoning, and applies both structural and semantic validation before execution. The execution engine adheres to the generated DAG plan to coordinate concurrent retrieval across heterogeneous sources, route intermediate outputs to dependent sub-queries, and merge final results in strict accordance with the plan's logical dependencies. Advanced caching mechanisms, incorporating paraphrase-aware template matching, enable the system to detect equivalent queries and reuse prior DAG execution plans for rapid re-execution, while the DataOps System addresses validation feedback or execution errors. The proposed framework not only improves accuracy and latency, but also produces explicit evidence trails, enabling verification of retrieved content, tracing of data lineage, and fostering user trust in the system's outputs. On benchmark dataset, A.DOT achieves 14.8% absolute gain in correctness and 10.7% in completeness over baselines.
FinOps Agent -- A Use-Case for IT Infrastructure and Cost Optimization
Oct 29, 2025



FinOps (Finance + Operations) represents an operational framework and cultural practice which maximizes cloud business value through collaborative financial accountability across engineering, finance, and business teams. FinOps practitioners face a fundamental challenge: billing data arrives in heterogeneous formats, taxonomies, and metrics from multiple cloud providers and internal systems which eventually lead to synthesizing actionable insights, and making time-sensitive decisions. To address this challenge, we propose leveraging autonomous, goal-driven AI agents for FinOps automation. In this paper, we built a FinOps agent for a typical use-case for IT infrastructure and cost optimization. We built a system simulating a realistic end-to-end industry process starting with retrieving data from various sources to consolidating and analyzing the data to generate recommendations for optimization. We defined a set of metrics to evaluate our agent using several open-source and close-source language models and it shows that the agent was able to understand, plan, and execute tasks as well as an actual FinOps practitioner.
Data Readiness Report
Oct 15, 2020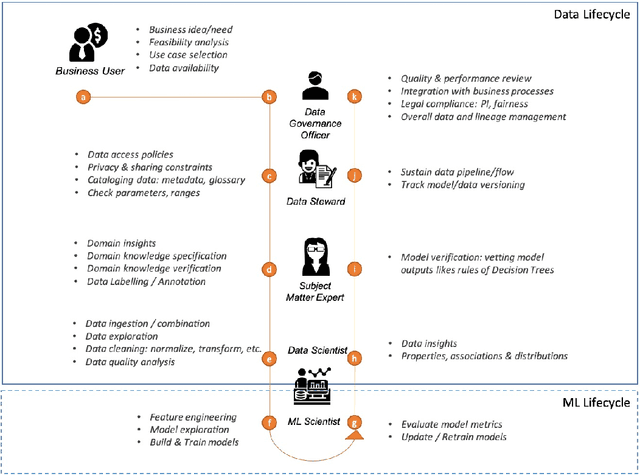
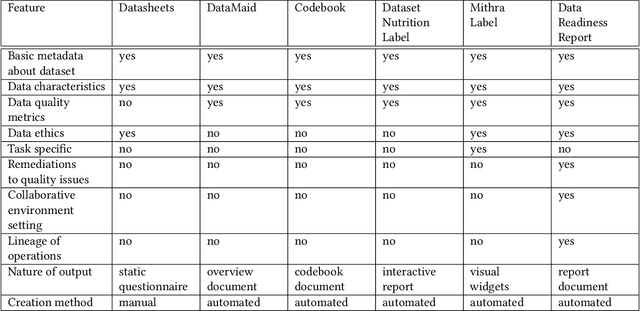
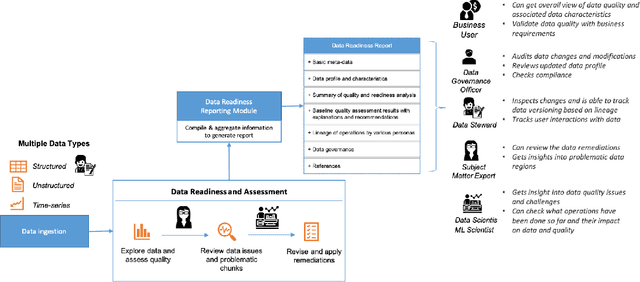

Data exploration and quality analysis is an important yet tedious process in the AI pipeline. Current practices of data cleaning and data readiness assessment for machine learning tasks are mostly conducted in an arbitrary manner which limits their reuse and results in loss of productivity. We introduce the concept of a Data Readiness Report as an accompanying documentation to a dataset that allows data consumers to get detailed insights into the quality of input data. Data characteristics and challenges on various quality dimensions are identified and documented keeping in mind the principles of transparency and explainability. The Data Readiness Report also serves as a record of all data assessment operations including applied transformations. This provides a detailed lineage for the purpose of data governance and management. In effect, the report captures and documents the actions taken by various personas in a data readiness and assessment workflow. Overtime this becomes a repository of best practices and can potentially drive a recommendation system for building automated data readiness workflows on the lines of AutoML [8]. We anticipate that together with the Datasheets [9], Dataset Nutrition Label [11], FactSheets [1] and Model Cards [15], the Data Readiness Report makes significant progress towards Data and AI lifecycle documentation.
Model Extraction Warning in MLaaS Paradigm
Nov 20, 2017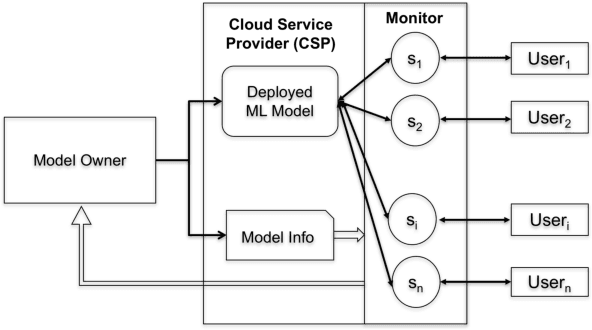
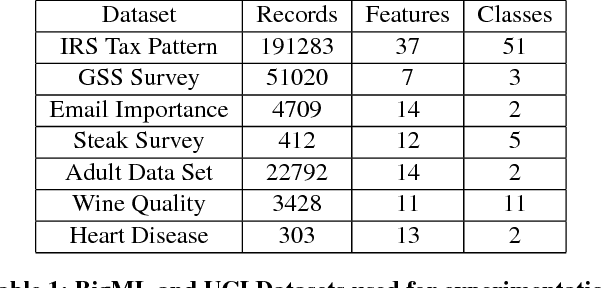
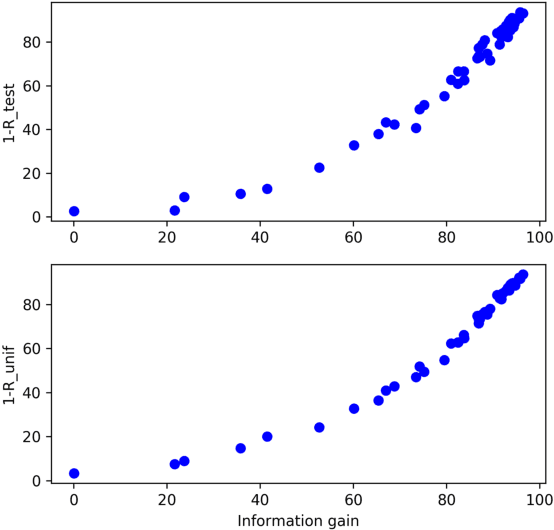
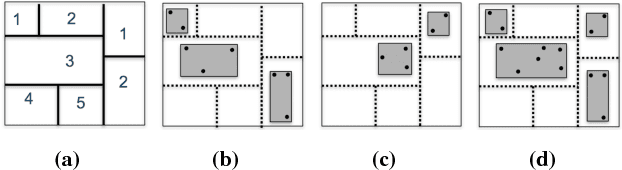
Cloud vendors are increasingly offering machine learning services as part of their platform and services portfolios. These services enable the deployment of machine learning models on the cloud that are offered on a pay-per-query basis to application developers and end users. However recent work has shown that the hosted models are susceptible to extraction attacks. Adversaries may launch queries to steal the model and compromise future query payments or privacy of the training data. In this work, we present a cloud-based extraction monitor that can quantify the extraction status of models by observing the query and response streams of both individual and colluding adversarial users. We present a novel technique that uses information gain to measure the model learning rate by users with increasing number of queries. Additionally, we present an alternate technique that maintains intelligent query summaries to measure the learning rate relative to the coverage of the input feature space in the presence of collusion. Both these approaches have low computational overhead and can easily be offered as services to model owners to warn them of possible extraction attacks from adversaries. We present performance results for these approaches for decision tree models deployed on BigML MLaaS platform, using open source datasets and different adversarial attack strategies.