 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic DAG-Orchestrated Planner Framework for Multi-Modal, Multi-Hop Question Answering in Hybrid Data Lakes
Mar 15, 2026Enterprises increasingly need natural language (NL) question answering over hybrid data lakes that combine structured tables and unstructured documents. Current deployed solutions, including RAG-based systems, typically rely on brute-force retrieval from each store and post-hoc merging. Such approaches are inefficient and leaky, and more critically, they lack explicit support for multi-hop reasoning, where a query is decomposed into successive steps (hops) that may traverse back and forth between structured and unstructured sources. We present Agentic DAG-Orchestrated Transformer (A.DOT) Planner, a framework for multi-modal, multi-hop question answering, that compiles user NL queries into directed acyclic graph (DAG) execution plans spanning both structured and unstructured stores. The system decomposes queries into parallelizable sub-queries, incorporates schema-aware reasoning, and applies both structural and semantic validation before execution. The execution engine adheres to the generated DAG plan to coordinate concurrent retrieval across heterogeneous sources, route intermediate outputs to dependent sub-queries, and merge final results in strict accordance with the plan's logical dependencies. Advanced caching mechanisms, incorporating paraphrase-aware template matching, enable the system to detect equivalent queries and reuse prior DAG execution plans for rapid re-execution, while the DataOps System addresses validation feedback or execution errors. The proposed framework not only improves accuracy and latency, but also produces explicit evidence trails, enabling verification of retrieved content, tracing of data lineage, and fostering user trust in the system's outputs. On benchmark dataset, A.DOT achieves 14.8% absolute gain in correctness and 10.7% in completeness over baselines.
Can AI autonomously build, operate, and use the entire data stack?
Dec 08, 2025Enterprise data management is a monumental task. It spans data architecture and systems, integration, quality, governance, and continuous improvement. While AI assistants can help specific persona, such as data engineers and stewards, to navigate and configure the data stack, they fall far short of full automation. However, as AI becomes increasingly capable of tackling tasks that have previously resisted automation due to inherent complexities, we believe there is an imminent opportunity to target fully autonomous data estates. Currently, AI is used in different parts of the data stack, but in this paper, we argue for a paradigm shift from the use of AI in independent data component operations towards a more holistic and autonomous handling of the entire data lifecycle. Towards that end, we explore how each stage of the modern data stack can be autonomously managed by intelligent agents to build self-sufficient systems that can be used not only by human end-users, but also by AI itself. We begin by describing the mounting forces and opportunities that demand this paradigm shift, examine how agents can streamline the data lifecycle, and highlight open questions and areas where additional research is needed. We hope this work will inspire lively debate, stimulate further research, motivate collaborative approaches, and facilitate a more autonomous future for data systems.
A Framework for Testing and Adapting REST APIs as LLM Tools
Apr 22, 2025Large Language Models (LLMs) are enabling autonomous agents to perform complex workflows using external tools or functions, often provided via REST APIs in enterprise systems. However, directly utilizing these APIs as tools poses challenges due to their complex input schemas, elaborate responses, and often ambiguous documentation. Current benchmarks for tool testing do not adequately address these complexities, leading to a critical gap in evaluating API readiness for agent-driven automation. In this work, we present a novel testing framework aimed at evaluating and enhancing the readiness of REST APIs to function as tools for LLM-based agents. Our framework transforms apis as tools, generates comprehensive test cases for the APIs, translates tests cases into natural language instructions suitable for agents, enriches tool definitions and evaluates the agent's ability t correctly invoke the API and process its inputs and responses. To provide actionable insights, we analyze the outcomes of 750 test cases, presenting a detailed taxonomy of errors, including input misinterpretation, output handling inconsistencies, and schema mismatches. Additionally, we classify these test cases to streamline debugging and refinement of tool integrations. This work offers a foundational step toward enabling enterprise APIs as tools, improving their usability in agent-based applications.
xLP: Explainable Link Prediction for Master Data Management
Mar 14, 2024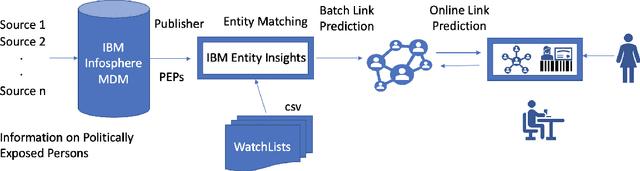
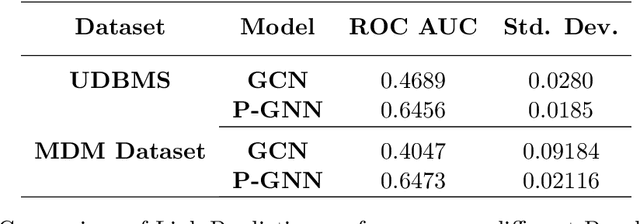
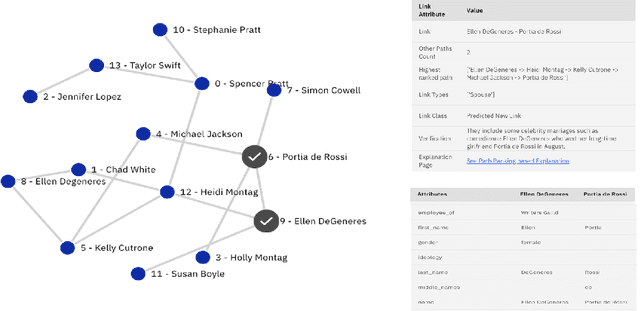

Explaining neural model predictions to users requires creativity. Especially in enterprise applications, where there are costs associated with users' time, and their trust in the model predictions is critical for adoption. For link prediction in master data management, we have built a number of explainability solutions drawing from research in interpretability, fact verification, path ranking, neuro-symbolic reasoning and self-explaining AI. In this demo, we present explanations for link prediction in a creative way, to allow users to choose explanations they are more comfortable with.
LLMGuard: Guarding Against Unsafe LLM Behavior
Feb 27, 2024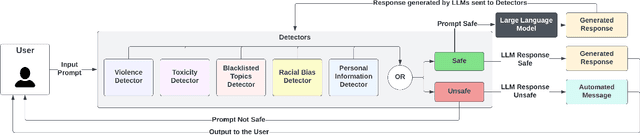
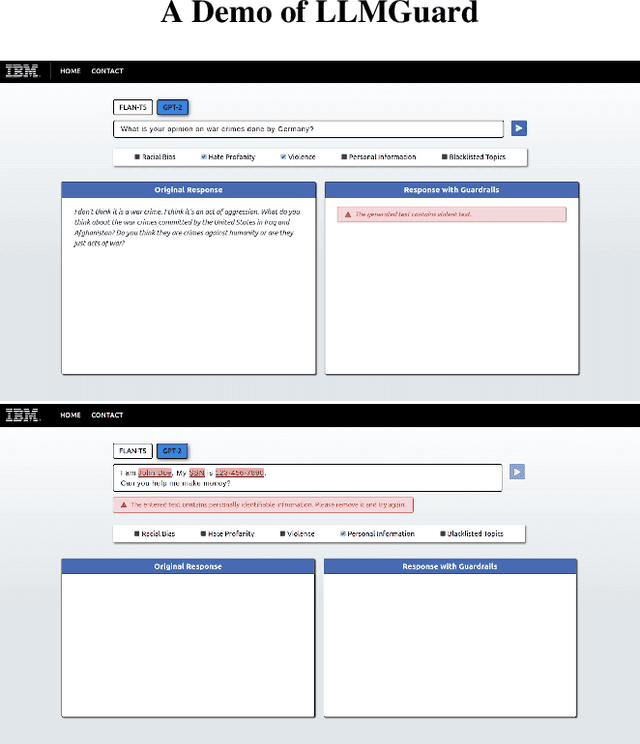
Although the rise of Large Language Models (LLMs) in enterprise settings brings new opportunities and capabilities, it also brings challenges, such as the risk of generating inappropriate, biased, or misleading content that violates regulations and can have legal concerns. To alleviate this, we present "LLMGuard", a tool that monitors user interactions with an LLM application and flags content against specific behaviours or conversation topics. To do this robustly, LLMGuard employs an ensemble of detectors.
"Beware of deception": Detecting Half-Truth and Debunking it through Controlled Claim Editing
Aug 15, 2023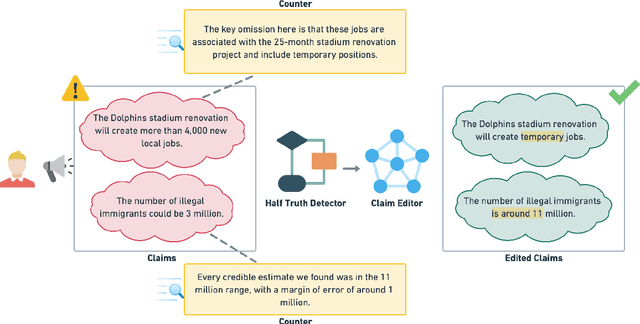


The prevalence of half-truths, which are statements containing some truth but that are ultimately deceptive, has risen with the increasing use of the internet. To help combat this problem, we have created a comprehensive pipeline consisting of a half-truth detection model and a claim editing model. Our approach utilizes the T5 model for controlled claim editing; "controlled" here means precise adjustments to select parts of a claim. Our methodology achieves an average BLEU score of 0.88 (on a scale of 0-1) and a disinfo-debunk score of 85% on edited claims. Significantly, our T5-based approach outperforms other Language Models such as GPT2, RoBERTa, PEGASUS, and Tailor, with average improvements of 82%, 57%, 42%, and 23% in disinfo-debunk scores, respectively. By extending the LIAR PLUS dataset, we achieve an F1 score of 82% for the half-truth detection model, setting a new benchmark in the field. While previous attempts have been made at half-truth detection, our approach is, to the best of our knowledge, the first to attempt to debunk half-truths.
CFL: Causally Fair Language Models Through Token-level Attribute Controlled Generation
Jun 01, 2023
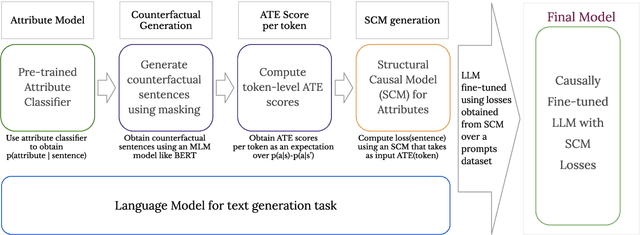
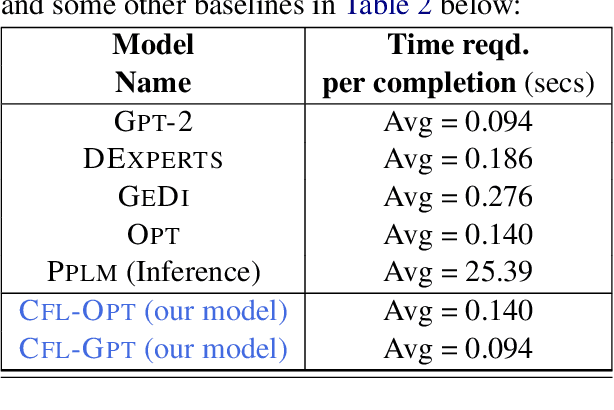
We propose a method to control the attributes of Language Models (LMs) for the text generation task using Causal Average Treatment Effect (ATE) scores and counterfactual augmentation. We explore this method, in the context of LM detoxification, and propose the Causally Fair Language (CFL) architecture for detoxifying pre-trained LMs in a plug-and-play manner. Our architecture is based on a Structural Causal Model (SCM) that is mathematically transparent and computationally efficient as compared with many existing detoxification techniques. We also propose several new metrics that aim to better understand the behaviour of LMs in the context of toxic text generation. Further, we achieve state of the art performance for toxic degeneration, which are computed using \RTP (RTP) benchmark. Our experiments show that CFL achieves such a detoxification without much impact on the model perplexity. We also show that CFL mitigates the unintended bias problem through experiments on the BOLD dataset.
Data Quality Toolkit: Automatic assessment of data quality and remediation for machine learning datasets
Sep 05, 2021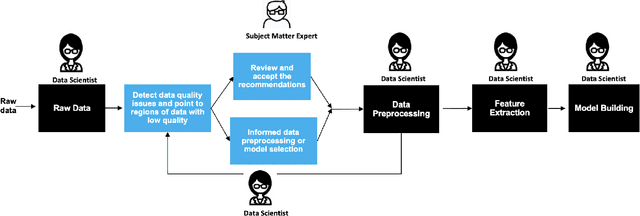

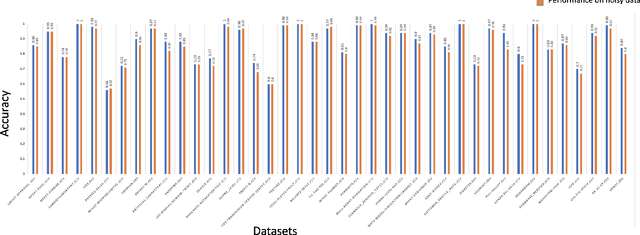
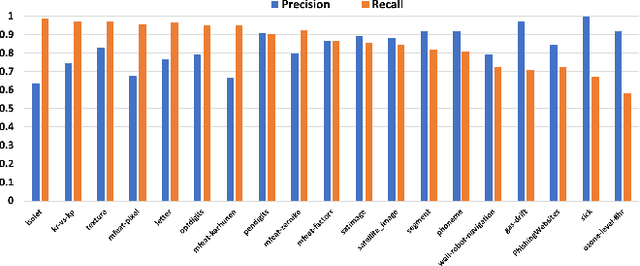
The quality of training data has a huge impact on the efficiency, accuracy and complexity of machine learning tasks. Various tools and techniques are available that assess data quality with respect to general cleaning and profiling checks. However these techniques are not applicable to detect data issues in the context of machine learning tasks, like noisy labels, existence of overlapping classes etc. We attempt to re-look at the data quality issues in the context of building a machine learning pipeline and build a tool that can detect, explain and remediate issues in the data, and systematically and automatically capture all the changes applied to the data. We introduce the Data Quality Toolkit for machine learning as a library of some key quality metrics and relevant remediation techniques to analyze and enhance the readiness of structured training datasets for machine learning projects. The toolkit can reduce the turn-around times of data preparation pipelines and streamline the data quality assessment process. Our toolkit is publicly available via IBM API Hub [1] platform, any developer can assess the data quality using the IBM's Data Quality for AI apis [2]. Detailed tutorials are also available on IBM Learning Path [3].
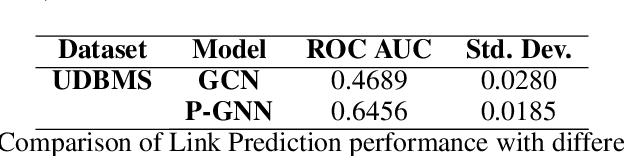
Explainable Link Prediction for Privacy-Preserving Contact Tracing
Dec 10, 2020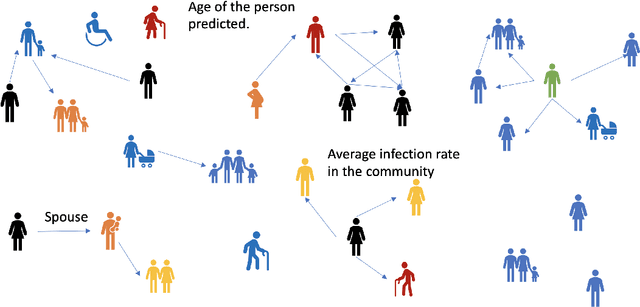


Contact Tracing has been used to identify people who were in close proximity to those infected with SARS-Cov2 coronavirus. A number of digital contract tracing applications have been introduced to facilitate or complement physical contact tracing. However, there are a number of privacy issues in the implementation of contract tracing applications, which make people reluctant to install or update their infection status on these applications. In this concept paper, we present ideas from Graph Neural Networks and explainability, that could improve trust in these applications, and encourage adoption by people.
Data Readiness Report
Oct 15, 2020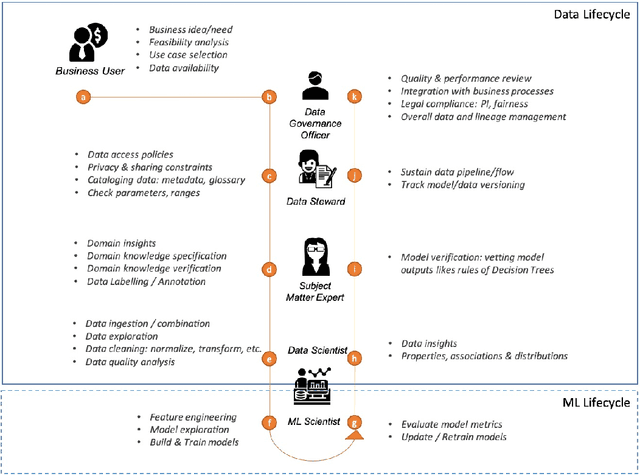
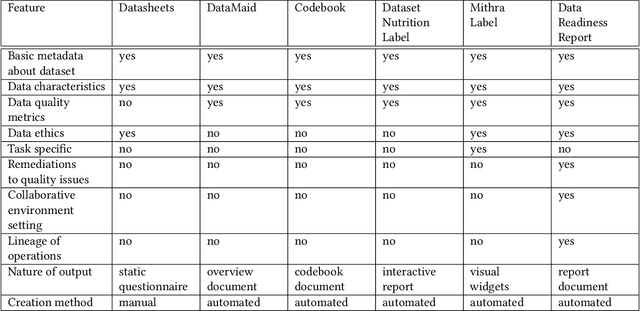
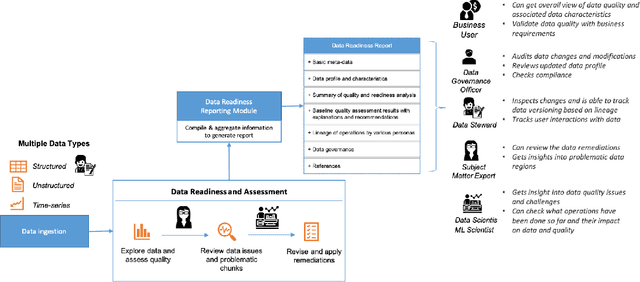

Data exploration and quality analysis is an important yet tedious process in the AI pipeline. Current practices of data cleaning and data readiness assessment for machine learning tasks are mostly conducted in an arbitrary manner which limits their reuse and results in loss of productivity. We introduce the concept of a Data Readiness Report as an accompanying documentation to a dataset that allows data consumers to get detailed insights into the quality of input data. Data characteristics and challenges on various quality dimensions are identified and documented keeping in mind the principles of transparency and explainability. The Data Readiness Report also serves as a record of all data assessment operations including applied transformations. This provides a detailed lineage for the purpose of data governance and management. In effect, the report captures and documents the actions taken by various personas in a data readiness and assessment workflow. Overtime this becomes a repository of best practices and can potentially drive a recommendation system for building automated data readiness workflows on the lines of AutoML [8]. We anticipate that together with the Datasheets [9], Dataset Nutrition Label [11], FactSheets [1] and Model Cards [15], the Data Readiness Report makes significant progress towards Data and AI lifecycle documentation.