 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrade Guard: A Smart System for Short Answer Automated Grading
Apr 01, 2025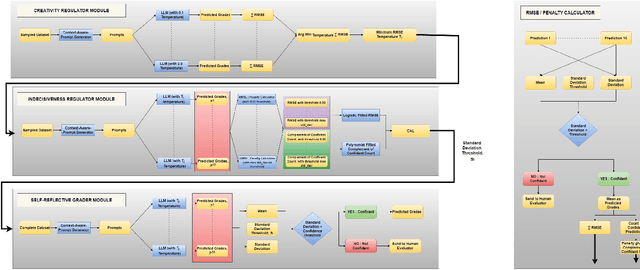
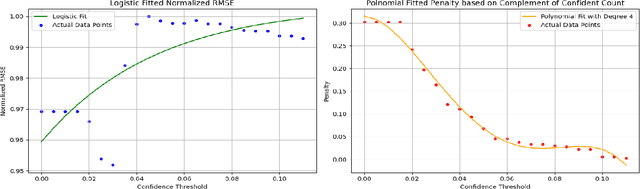
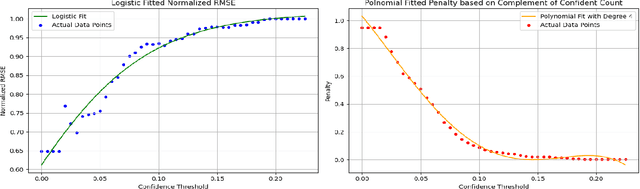
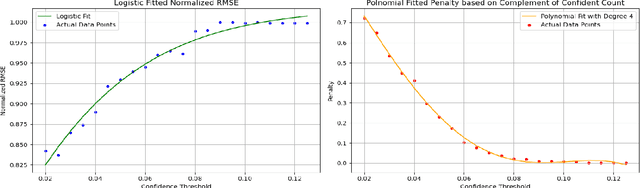
The advent of large language models (LLMs) in the education sector has provided impetus to automate grading short answer questions. LLMs make evaluating short answers very efficient, thus addressing issues like staff shortage. However, in the task of Automated Short Answer Grading (ASAG), LLM responses are influenced by diverse perspectives in their training dataset, leading to inaccuracies in evaluating nuanced or partially correct answers. To address this challenge, we propose a novel framework, Grade Guard. 1. To enhance the task-based specialization of the LLMs, the temperature parameter has been fine-tuned using Root Mean Square Error (RMSE). 2. Unlike traditional approaches, LLMs in Grade Guard compute an Indecisiveness Score (IS) along with the grade to reflect uncertainty in predicted grades. 3. Introduced Confidence-Aware Loss (CAL) to generate an optimized Indecisiveness Score (IS). 4. To improve reliability, self-reflection based on the optimized IS has been introduced into the framework, enabling human re-evaluation to minimize incorrect grade assignments. Our experimentation shows that the best setting of Grade Guard outperforms traditional methods by 19.16% RMSE in Upstage Solar Pro, 23.64% RMSE in Upstage Solar Mini, 4.00% RMSE in Gemini 1.5 Flash, and 10.20% RMSE in GPT 4-o Mini. Future work includes improving interpretability by generating rationales for grades to enhance accuracy. Expanding benchmark datasets and annotating them with domain-specific nuances will enhance grading accuracy. Finally, analyzing feedback to enhance confidence in predicted grades, reduce biases, optimize grading criteria, and personalize learning while supporting multilingual grading systems will make the solution more accurate, adaptable, fair, and inclusive.
Surveying Facial Recognition Models for Diverse Indian Demographics: A Comparative Analysis on LFW and Custom Dataset
Dec 11, 2024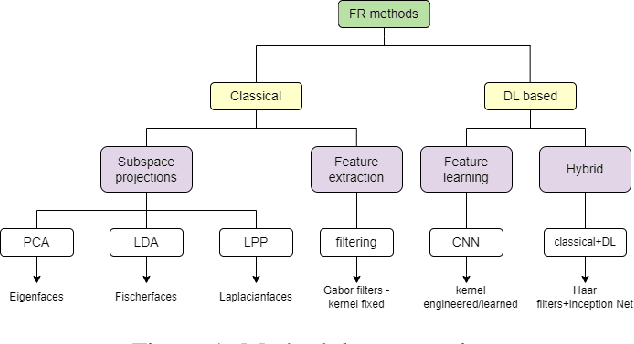



Facial recognition technology has made significant advances, yet its effectiveness across diverse ethnic backgrounds, particularly in specific Indian demographics, is less explored. This paper presents a detailed evaluation of both traditional and deep learning-based facial recognition models using the established LFW dataset and our newly developed IITJ Faces of Academia Dataset (JFAD), which comprises images of students from IIT Jodhpur. This unique dataset is designed to reflect the ethnic diversity of India, providing a critical test bed for assessing model performance in a focused academic environment. We analyze models ranging from holistic approaches like Eigenfaces and SIFT to advanced hybrid models that integrate CNNs with Gabor filters, Laplacian transforms, and segmentation techniques. Our findings reveal significant insights into the models' ability to adapt to the ethnic variability within Indian demographics and suggest modifications to enhance accuracy and inclusivity in real-world applications. The JFAD not only serves as a valuable resource for further research but also highlights the need for developing facial recognition systems that perform equitably across diverse populations.
LLMGuard: Guarding Against Unsafe LLM Behavior
Feb 27, 2024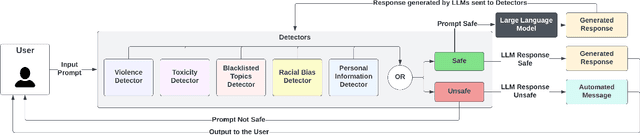
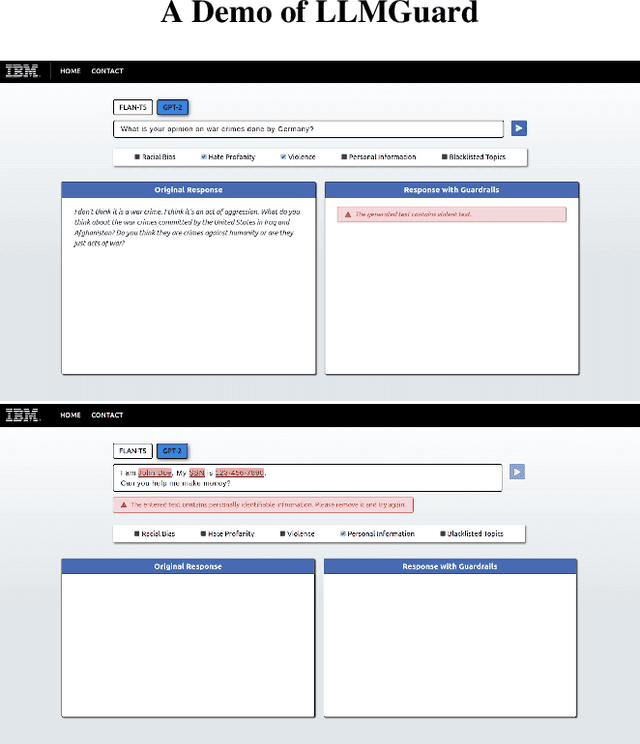
Although the rise of Large Language Models (LLMs) in enterprise settings brings new opportunities and capabilities, it also brings challenges, such as the risk of generating inappropriate, biased, or misleading content that violates regulations and can have legal concerns. To alleviate this, we present "LLMGuard", a tool that monitors user interactions with an LLM application and flags content against specific behaviours or conversation topics. To do this robustly, LLMGuard employs an ensemble of detectors.