 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMORPHOGEN: A Multilingual Benchmark for Evaluating Gender-Aware Morphological Generation
Apr 20, 2026While multilingual large language models (LLMs) perform well on high-level tasks like translation and question answering, their ability to handle grammatical gender and morphological agreement remains underexplored. In morphologically rich languages, gender influences verb conjugation, pronouns, and even first-person constructions with explicit and implicit mentions of gender. We introduce MORPHOGEN, a morphologically grounded large-scale benchmark dataset for evaluating gender-aware generation in three typologically diverse grammatically gendered languages: French, Arabic, and Hindi. The core task, GENFORM, requires models to rewrite a first-person sentence in the opposite gender while preserving its meaning and structure. We construct a high-quality synthetic dataset spanning these three languages and benchmark 15 popular multilingual LLMs (2B-70B) on their ability to perform this transformation. Our results reveal significant gaps and interesting insights into how current models handle morphological gender. MORPHOGEN provides a focused diagnostic lens for gender-aware language modeling and lays the groundwork for future research on inclusive and morphology-sensitive NLP.
Exploring Multilingual Unseen Speaker Emotion Recognition: Leveraging Co-Attention Cues in Multitask Learning
Jun 13, 2024



Advent of modern deep learning techniques has given rise to advancements in the field of Speech Emotion Recognition (SER). However, most systems prevalent in the field fail to generalize to speakers not seen during training. This study focuses on handling challenges of multilingual SER, specifically on unseen speakers. We introduce CAMuLeNet, a novel architecture leveraging co-attention based fusion and multitask learning to address this problem. Additionally, we benchmark pretrained encoders of Whisper, HuBERT, Wav2Vec2.0, and WavLM using 10-fold leave-speaker-out cross-validation on five existing multilingual benchmark datasets: IEMOCAP, RAVDESS, CREMA-D, EmoDB and CaFE and, release a novel dataset for SER on the Hindi language (BhavVani). CAMuLeNet shows an average improvement of approximately 8% over all benchmarks on unseen speakers determined by our cross-validation strategy.
CrossVoice: Crosslingual Prosody Preserving Cascade-S2ST using Transfer Learning
May 23, 2024


This paper presents CrossVoice, a novel cascade-based Speech-to-Speech Translation (S2ST) system employing advanced ASR, MT, and TTS technologies with cross-lingual prosody preservation through transfer learning. We conducted comprehensive experiments comparing CrossVoice with direct-S2ST systems, showing improved BLEU scores on tasks such as Fisher Es-En, VoxPopuli Fr-En and prosody preservation on benchmark datasets CVSS-T and IndicTTS. With an average mean opinion score of 3.75 out of 4, speech synthesized by CrossVoice closely rivals human speech on the benchmark, highlighting the efficacy of cascade-based systems and transfer learning in multilingual S2ST with prosody transfer.
Multilingual Prosody Transfer: Comparing Supervised & Transfer Learning
May 23, 2024The field of prosody transfer in speech synthesis systems is rapidly advancing. This research is focused on evaluating learning methods for adapting pre-trained monolingual text-to-speech (TTS) models to multilingual conditions, i.e., Supervised Fine-Tuning (SFT) and Transfer Learning (TL). This comparison utilizes three distinct metrics: Mean Opinion Score (MOS), Recognition Accuracy (RA), and Mel Cepstral Distortion (MCD). Results demonstrate that, in comparison to SFT, TL leads to significantly enhanced performance, with an average MOS higher by 1.53 points, a 37.5% increase in RA, and approximately a 7.8-point improvement in MCD. These findings are instrumental in helping build TTS models for low-resource languages.
LLMGuard: Guarding Against Unsafe LLM Behavior
Feb 27, 2024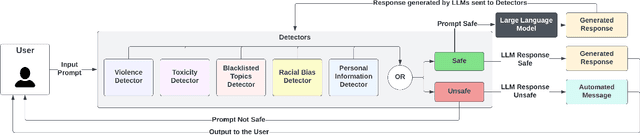
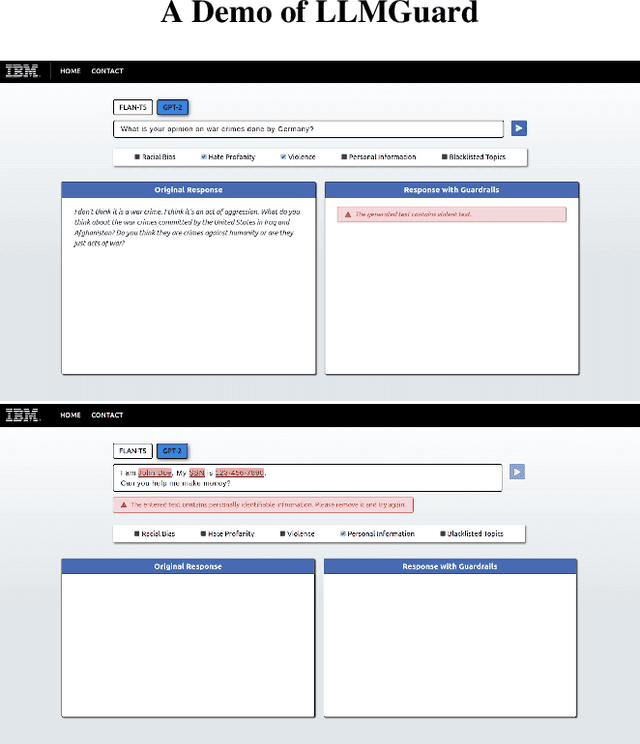
Although the rise of Large Language Models (LLMs) in enterprise settings brings new opportunities and capabilities, it also brings challenges, such as the risk of generating inappropriate, biased, or misleading content that violates regulations and can have legal concerns. To alleviate this, we present "LLMGuard", a tool that monitors user interactions with an LLM application and flags content against specific behaviours or conversation topics. To do this robustly, LLMGuard employs an ensemble of detectors.
Advancements in Scientific Controllable Text Generation Methods
Jul 08, 2023The previous work on controllable text generation is organized using a new schema we provide in this study. Seven components make up the schema, and each one is crucial to the creation process. To accomplish controlled generation for scientific literature, we describe the various modulation strategies utilised to modulate each of the seven components. We also offer a theoretical study and qualitative examination of these methods. This insight makes possible new architectures based on combinations of these components. Future research will compare these methods empirically to learn more about their strengths and utility.